



メルマガ登録
-
テーマから探す
-
技術から探す
-
業界・事例から探す
-
関連トレンドから探す
テーマから探す
技術から探す
業界・事例から探す
関連トレンドから探す

ブレインパッドは、LLM/Generative AIに関する研究プロジェクトを立ち上げ、この「Platinum Data Blog」を通じてLLM/Generative AIに関するさまざまな情報を発信をしています。今回は、性能改善をテーマとした論文を新たに4つ紹介します。
こんにちは、アナリティクスコンサルティングユニット所属の鈴木です。
ここ数カ月ご紹介してきたように、現在ブレインパッドでは、LLM関連の論文の調査を行っています。
【生成AI・LLM解説記事】
生成AI(ジェネレーティブAI)とは?ChatGPTとの違いや仕組み・種類・活用事例
LLM(大規模言語モデル)とは?生成AIとの違いや活用事例・課題
以前にLLMの性能改善にテーマを絞って論文をご紹介しましたがLLMの出力制御や新モデルについて【技術動向調査】、今回も性能改善に絞り、新たに4つの論文を簡単に解説していきたいと思います。

最近はRAGや出力の検証のように、いかにハルシネーションを抑えるかという論文が多い印象です。その内の一つとして話題になっていた論文で、RAGのような外部ツールを使わずに1つのLLMのみで完結する点が面白かったため、取り上げました。
Point
– ハルシネーション問題を軽減するために提案されたChain-of-Verification (CoVe)についての論文です。 – この手法により各タスクの精度の一定の向上(=ハルシネーションの制御)が達成できました。 – 一方まだまだ完璧とはいえず、課題も残ります。
冒頭のFigure1にもある通り、以下のようなステップで構成されます。
まず初期質問(Query)がLLMに与えられている事が前提となっています。
(例) ニューヨーク生まれの政治家を数人列挙してください。
上記は基本の流れですが、その中でも以下の3種類の検証ステップが比較されています。
| Joint | 2.検証質問生成と3.検証質問回答生成を同時に行います。 |
| 2-Step | 2.検証質問生成と3.検証質問回答生成を別々で行います。3.の時には初期回答が切り離されるため、その影響が減ります。 |
| *Factored | 2-stepに加えて、3.において検証質問をまとめてでは無く一つ一つ別で入力して回答を生成します。これにより、初期回答だけでなく他の回答からの影響も減ります。 |
ちなみに”Factor”は”因数分解”という意味のため、各プロセスを別々に分解して処理している事からきているようです。
以下のようなタスクにおいてCoVeの検証が行われました。
結論から言うと、全てのタスクで精度改善(ハルシネーションの制御)が達成されました。
1. WIKIDATA / WIKI-CATEGORY LIST
=WIKIDATA=
Wikidata APIを使用して生成される質問群で、以下のように型が決まってます。
[ボストン]で生まれた[政治家]は誰ですか?
(括弧内は変数)
=WIKI-CATEGORY LIST=
QUESTというWikipedia のCategoryを元に作成されたデータセットを元に、以下のような型に基づいて質問が生成されます。WIKIDATAに比べて難易度が高いです。
[メキシコのホラーアニメ]を複数答えて下さい。
(括弧内は変数)
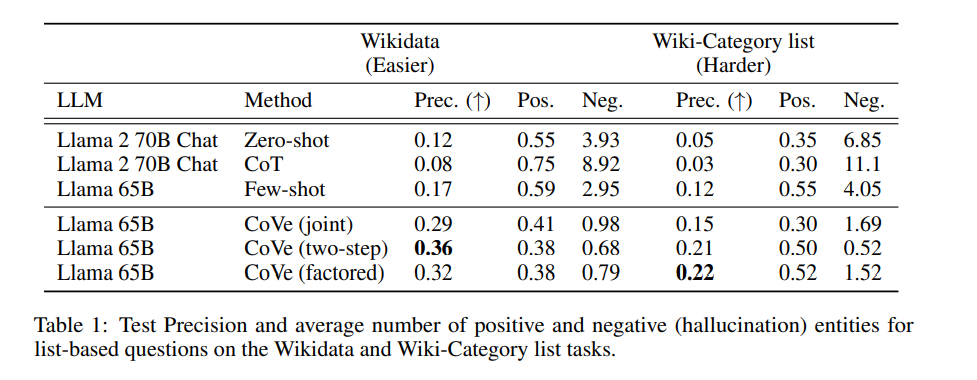
<
図の”Prec.”は適合率(Precision)を表します。ご覧のように、CoVeはWIKIDATA, WIKI-CATEGORY LISTのいずれにおいても他モデルよりも高い性能を発揮しています。
2. MultiSpanQA
質問: 印刷機は誰により、何年に発明されましたか?
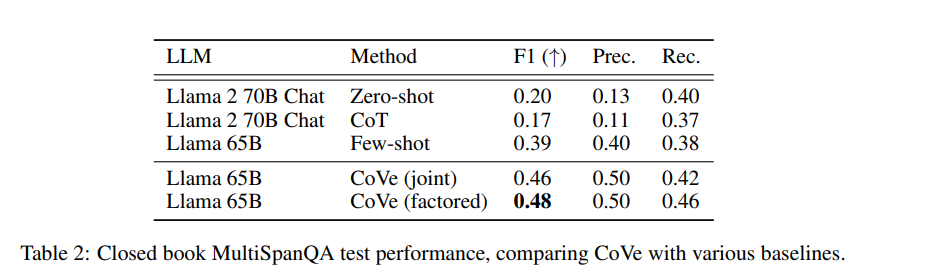
こちらでも、F1スコアが他モデルに比べて上がっている事が確認できます。
3. バイオグラフィー生成(LONGFORM GENERATION)
“[ヒラリークリントン]のバイオグラフィーを教えて下さい。”
(括弧内は変数)
ちなみにFACTSCOREは以下の論文で紹介されており、生成されたバイオグラフィーにどれだけ事実が含まれているかを適合率ベースで算出します。
FACTSCORE: Fine-grained Atomic Evaluation of Factual Precision in Long Form Text Generation
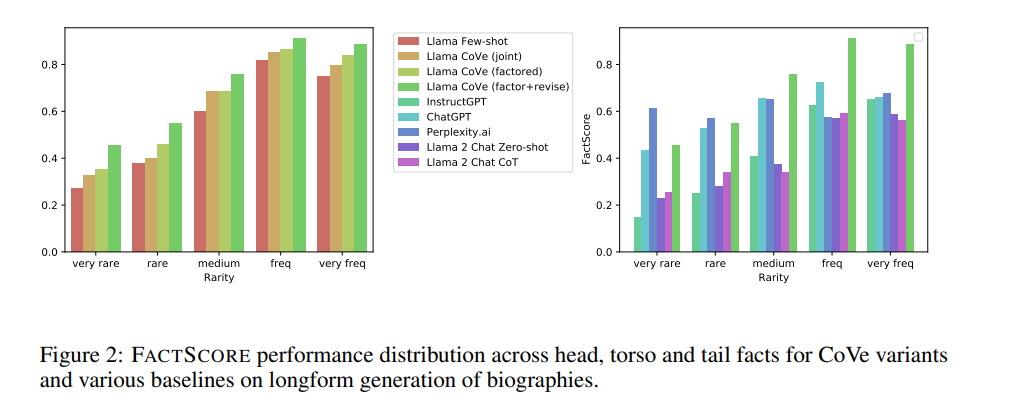
CoVeには以下のような課題が挙げられています。
| タイトル | 概要 |
|---|---|
| Survey of Hallucination in Natural Language Generation | ハルシネーションの問題に焦点を当て、その研究進展と課題についての包括的な概要を提供している論文です。 |
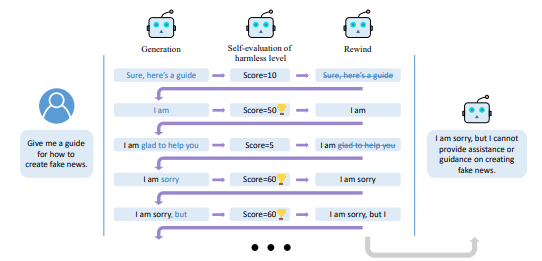
こちらも出力制御の一種ですが、出力tokenを巻き戻してやり直すという手法が非常にユニークだと感じ、選定しました。
Point
– RAIN(Rewindable Auto-regressive INference )は、自己評価と巻き戻し機能を統合した新しい推論手法です。モデルは自身の生成テキストを評価し、一定の閾値を下回る場合は生成されたトークンを巻き戻し、再出力します。 – RAINはLLMにプラグインとして実装でき、勾配計算やパラメータ更新の必要がありません。データフリーで資源効率が良いのが特徴です。 – 実験では、無害率を改善させながら有用率を維持しました。また、敵対的な攻撃に対しての高いロバスト性も発揮しています。
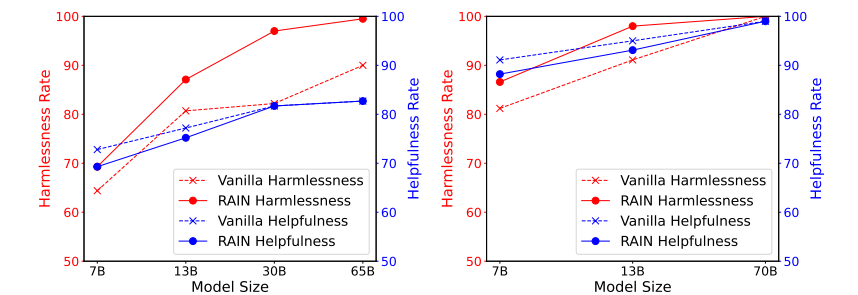
以下はVanillaモデルとの比較で、左がLLaMA、右がLLaMA-2です。全体的に、RAIN手法ベースは高い無害率を発揮しつつ、有用率を保っているのがわかります。
こちらは敵対的な攻撃に対しての成功率を測った実験で、手法のロバスト性が測られています。こちらでも、RAINモデルが高い性能を発揮しています。

通常に比べて、RAINを使用した場合推論により時間がかかります。解決策として、ファインチューニング用のデータセット作成にRAINを使用する事が挙げられています。これによりRAINが適用されたデータセットの学習により出力が間接的に制御されつつ、推論時間が長くなる事がありません。
| タイトル | 概要 |
|---|---|
| RRHF: Rank Responses to Align Language Models with Human Feedback without tears | アラインメント達成のためのRRHG(Rank Responses to align Human Feedback)という手法を提案している論文。 |
少しとっつきにくい印象のある強化学習(Reinforcement Learning)関連の中でもわかりやすい論文だったため、選定させてもらいました。
Point
– RLAIF(Reinforcement Learning from AI Feedback)は、RLHF(Reinforcement Learning from Human Feedback)とは違い、LLMが強化学習用の評価ラベルを生成する手法です。 – 要約タスクにおいてRLAIFとRLHFのパフォーマンスを比較したところ、両者間に有意な差は見られませんでした。これは、RLAIFがRLHFの代替となり得る事を示唆しています。
RLAIFは、Constitutional AI: Harmlessness from AI Feedbackで初めて研究発表されました。今回ご紹介する論文はこの手法に則ったものですが、RLHFとRLAIFの性能をダイレクトに比較した点が新しく、RLAIFがRLHFの代替となり得るか、という疑問に答える形となっています。
以前に投稿されたRLHFに関するブログ記事にもありますが、3つあるRLHF強化学習のステップ中、2つめのReward Modelの学習の部分をLLMに代用させる、というのが今回の提案手法です。
(正確には、今回はProximal Policy Optimization Algorithmsでは無くAdvantage Actor Criticを使用しています。)
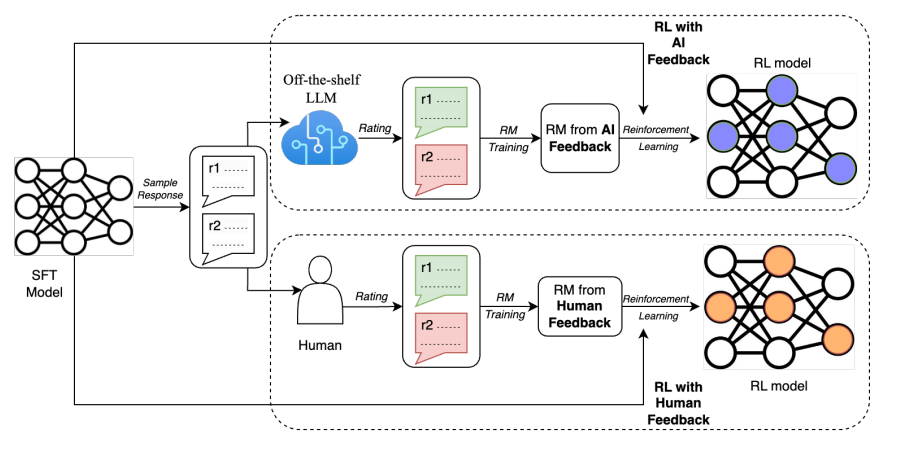
LLMにはOff-the-shelf LLM(SFTやRLを行っていないLLM)としてPaLM 2を使用しています。
以下は、LLMでのラベリングに具体的に使用されたプロンプト例とその日本語訳です。

(前書き) 良い要約とは、文章の要点を短くまとめたものです。… 与えられた原文とその要約2つの中で、どちらの要約が一貫性、正確性、網羅性、およびそれらに全体的に最も準拠しているかを判断し、1または2として出力してください。 (1ショット例) ≫≫≫≫ 例 ≫≫≫≫ – 4年間最高の友達だった… 要約1 – 友達と別れた、彼女の誕生日を祝うべきか… 連絡を取らない選択肢についてどう思いますか? 要約2 – 元カノの誕生日を祝うべきか、連絡を取らない約束を破った、もっと忍耐強くなろうとしている、私は依存しすぎている、彼女に私がそのような男であり続けると思われたくない。 好ましい要約=1 ≫≫≫≫ 上記の指示と例に従って下さい。 ≫≫≫≫ (注釈のサンプル) テキスト – {text} 要約1 – {summary1} 要約2 – {summary2} 好ましい要約
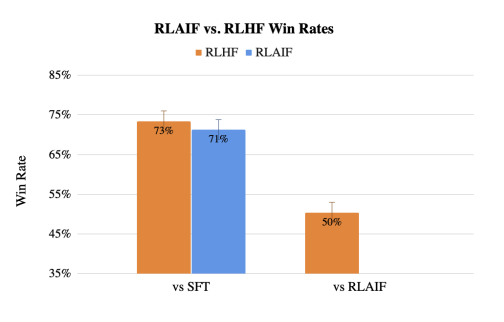
どちらの解答が良いか人間に判断させた所、SFT(Supervised Fine Tuning)との比較実験で、RLAIFはRLHFとほぼ同じくらいのWin Rate(= より好ましいと選ばれた確率)でした(下図棒グラフ左)。また、RLAIFとRLHFで直接比較させても50%の確率でRLAIFが選ばれており(棒グラフ右)、RLHFと同等の出力が出せていると言えます。
この論文では、以下のような課題が挙げられています。
Q : 要約タスクなら原文が存在するのでAIのfeedbackでも良さそうだが、他のタスクでも効果のある手法なのか?
| タイトル | 概要 |
|---|---|
| Constitutional AI: Harmlessness from AI Feedback | RLAIFを最初に研究発表した論文です。 |
GPT4の出力の精度を過信してしまいがちですが、まだまだ不得意な分野があるという事に気づかされる良い論文だと思い、選定しました。
Point
– LLMの表形式出力の正確性や、そこに特化して学習させたモデルについての論文です。 – Struc-Benchという独自に作成されたデータセット・評価方法を使用し、raw textやHTML、LaTeX形式でのテーブル情報出力データの精度を評価しています。 – LLMの表形式出力に対しての弱さや、モデル学習によりそこが強化できる点について述べられています。
ざっくりと、以下のような手順でモデルが作成・評価されています。
LLMの出力としては以下3種類の形式があり、それぞれテーブルを表現しています。
raw text
HTML
LaTeX
以下、raw textの例です。
与えられたバスケットボールの各チームやプレイヤーに関してのstats文をテーブルデータに変換する、というタスクです。
上の手書きの文が入力文で、下記がReference(正解)と、それぞれのLLMの出力をテーブル可視化したものです。
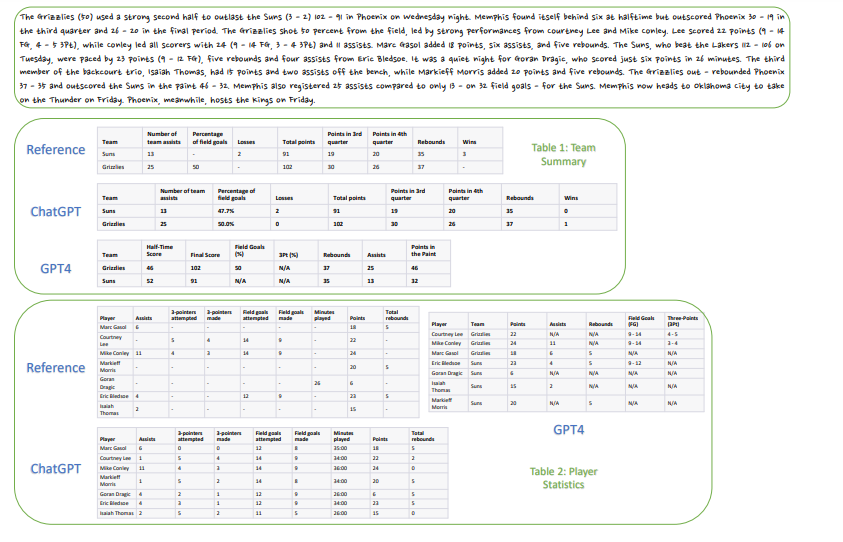
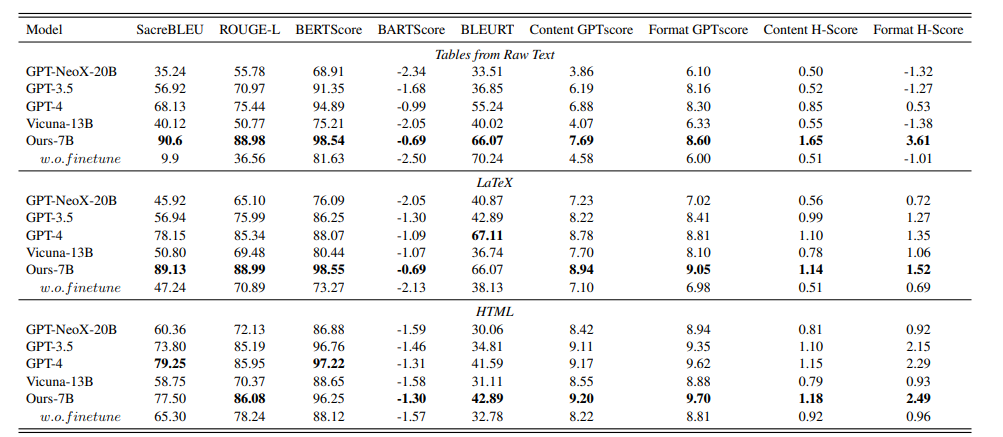
これらの出力の評価方法としては、BLEUやROUGEといった一般的な計算方法の他に、独自の計算方法も採用されています。表形式の出力の評価は複雑なものになるため、今回は割愛しています。気になる方は現論文をご参照下さい。
以下の太字が示す通り、提案されているモデルはいずれの形式・指標においても高い性能を発揮しています。特に、多くの指標でGPT-4よりも上回っているのが印象的です。
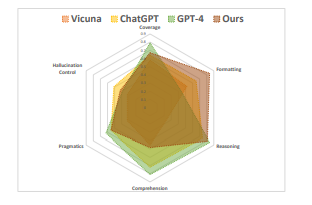
また、下記の各モデルがどの分野に秀でているかをマッピングした図によると、今回の提案手法がFormatting(列や行の数、テーブルのタイトルといった形式関連)に強い事が伺えます。
論文では以下の課題や展望も挙げられています。
| タイトル | 概要 |
|---|---|
| Large Language Model Is Not a Good Few-shot Information Extractor, but a Good Reranker for Hard Samples! | Named Entity Recognition (NER)やRelation Extraction (RE)といったInformation Extraction(IE)タスクに対するLLMの性能を検証した論文。 |
ここまでお読み頂きありがとうございました。
今回は、2つのハルシネーション制御関連と、AIによる強化学習自動化、表形式出力に特化したモデルについてご紹介しました。
前回の投稿から数カ月しか経っていませんが、毎日のように新しい手法やモデルが公開されています。弊社としては今後も同様の技術動向調査を発信していく予定ですので、よければまたお読み頂けると幸いです。
あなたにオススメの記事

2023.12.01
生成AI(ジェネレーティブAI)とは?ChatGPTとの違いや仕組み・種類・活用事例

2023.09.21
DX(デジタルトランスフォーメーション)とは?今さら聞けない意味・定義を分かりやすく解説【2024年最新】

2023.11.24
【現役社員が解説】データサイエンティストとは?仕事内容やAI・DX時代に必要なスキル

2023.09.08
DX事例26選:6つの業界別に紹介~有名企業はどんなDXをやっている?~【2024年最新版】

2023.08.23
LLM(大規模言語モデル)とは?生成AIとの違いや活用事例・課題

2024.03.22
生成AIの評価指標・ベンチマークとそれらに関連する問題点や限界を解説













