



メルマガ登録
-
テーマから探す
-
技術から探す
-
業界・事例から探す
-
関連トレンドから探す
テーマから探す
技術から探す
業界・事例から探す
関連トレンドから探す

1年前と比較して「顧客がなぜ自社サービスを利用するのか」の解像度は上がりましたか?
あるいは、「顧客の解約リスク」を定量的に常に把握できていますか?
効果が乏しいマーケ施策を特定し中止の意思決定・予算配分の修正ができたのは何件ですか?
大量の顧客データを蓄積し分析から購入・継続利用のきっかけ作りはできているが、顧客の解像度が上がらない状態のままで意思決定し、前年踏襲のマーケティング戦略・戦術が慣習的に続いているのではないでしょうか。
もちろん、マーケティング活動において様々な課題が山積みである事は十分に理解しています。しかし、変化の激しいデジタルビジネスにおいて競争優位なマーケティング戦略を設計・遂行するには、スピーディーで成功確率の高い意思決定が必要不可欠です。そのために顧客データの蓄積・拡張のみならず「資産化」が連動して運用されていなければなりません。
本記事では、顧客データを蓄積した上で「拡張」し、それらをもとに「資産化」することによりマーケティング戦略と戦術を洗練していくためのステップをご紹介します。
※本記事は、2023年9月27日にオンライン配信された、「<オンラインセミナー>デジタルビジネスの成否を分ける~顧客データの資産化への取り組みステップ~」の内容を記事用に再編集しました。

株式会社ブレインパッドの辻 陽行と申します。新卒でブレインパッドに入社後、開発から実運用までの利害関係者の調整や、機械学習モデル特有のリスクヘッジプランの設計など、幅広い支援を実施してきました。

2020年からの3年間は、150名以上が在籍するデータサイエンティスト部署の副部長としてマネジメントに従事し、現在は、コンシューマーインダストリーユニットにてインダストリー責任者を担当しています。
【辻陽行執筆のその他記事】
私はデータ活用支援のお問い合わせをいただいたとき、「顧客データをマーケティングに活用していますか?」と質問します。これに対し、「データ基盤を整え、データ活用人材を採用するなど、取り組んではいる」と回答されるお客様がほとんどです。
さらに、「昨年と比較して、顧客の解像度はどの程度上がりましたか?」「それによりオペレーションをどう変えましたか?」と質問します。すると、「KPIを設計し、顧客と業務の見える化を進めているはずなのに、なぜかよくわからない」と回答されるケースがあります。顧客データが蓄積されやすいデジタルビジネスの担当者ですら、データ活用に関する悩みを抱えているのです。
そこで今回は、企業のデータ活用が停滞する理由とデータ資産化の必要性、データ資産化のステップについてお話しします。
まず、企業のデータ活用が停滞する理由についてです。
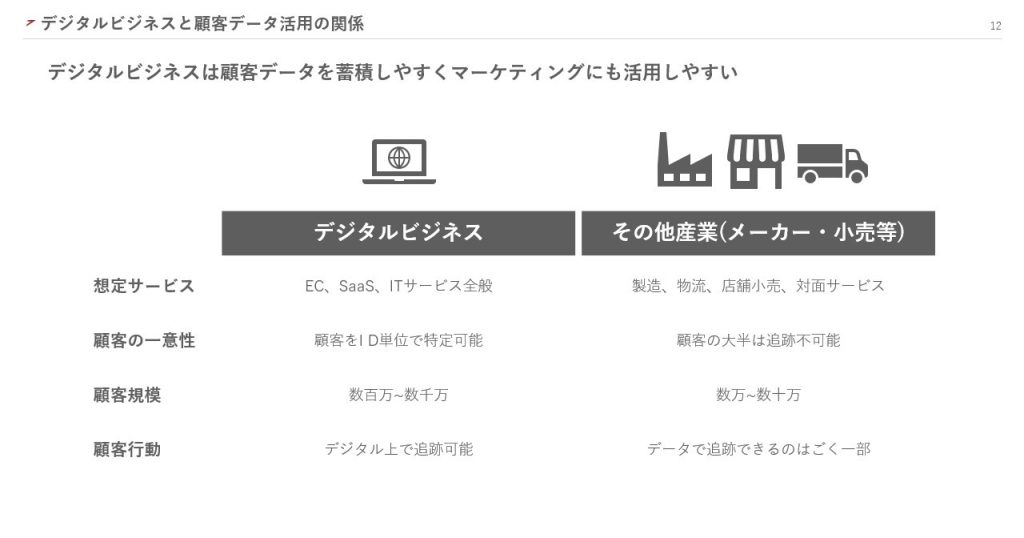
デジタルビジネスと一口に言っても、定義はさまざまです。今回は、EC、SaaS、ITサービス全般をデジタルビジネスと定義しました。これに対し、製造、物流、店舗小売、対面サービスをその他の産業と定義しています。
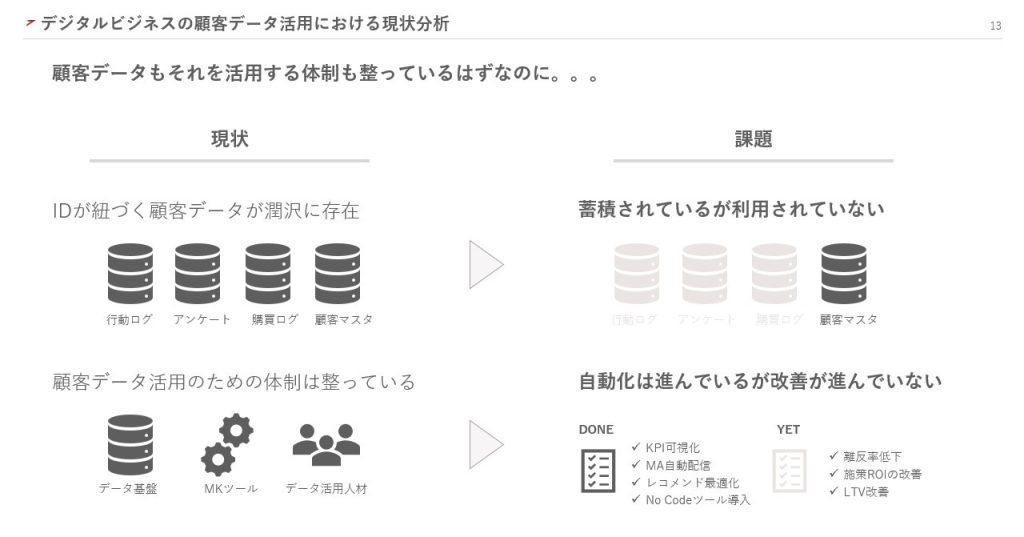
デジタルビジネスは顧客データを蓄積しやすく、ID単位で特定できるため、データを活用しやすい環境が整っているといえます。しかし、多くの企業では一部のデータしか活用できていないのが現状です。
また、データ活用のための体制を整え、業務の自動化はできているものの、改善には至っていないケースも見受けられます。
なぜこのような状況に陥るのでしょうか。それは、ビジネスの成果に影響する「意思決定のためのデータ活用」に着目していないからだと考えられます。
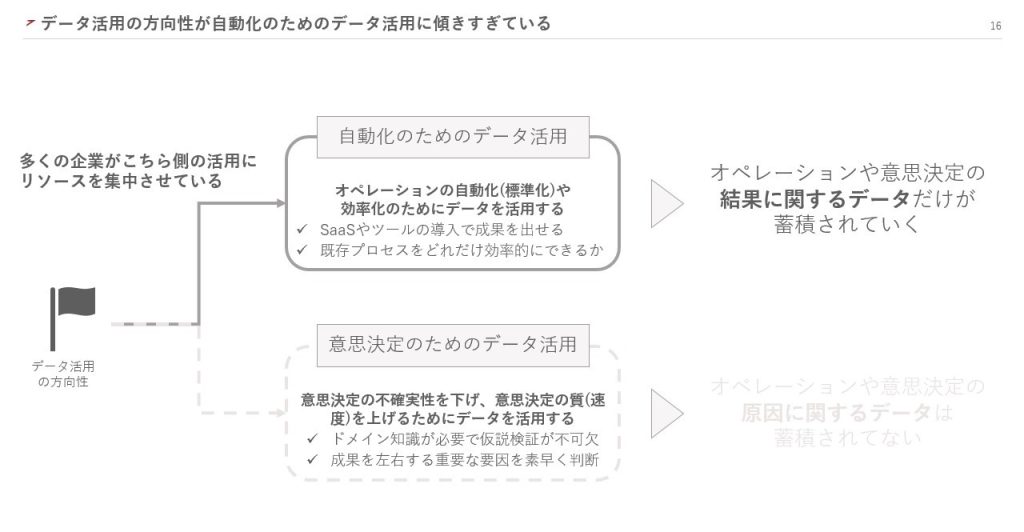
データ活用には、「自動化のためのデータ活用」と「意思決定のためのデータ活用」の2種類があります。このうち、多くの企業は「自動化のためのデータ活用」にリソースを集中させているのではないでしょうか。
「自動化のためのデータ活用」とは、既存のオペレーションを自動化し、効率化するためのデータ活用です。SaaSやMAツールなどの導入によって、すぐに成果を出すことができます。しかし、ここにリソースを集中させると、オペレーションや意思決定の結果に関するデータだけが蓄積されてしまいます。
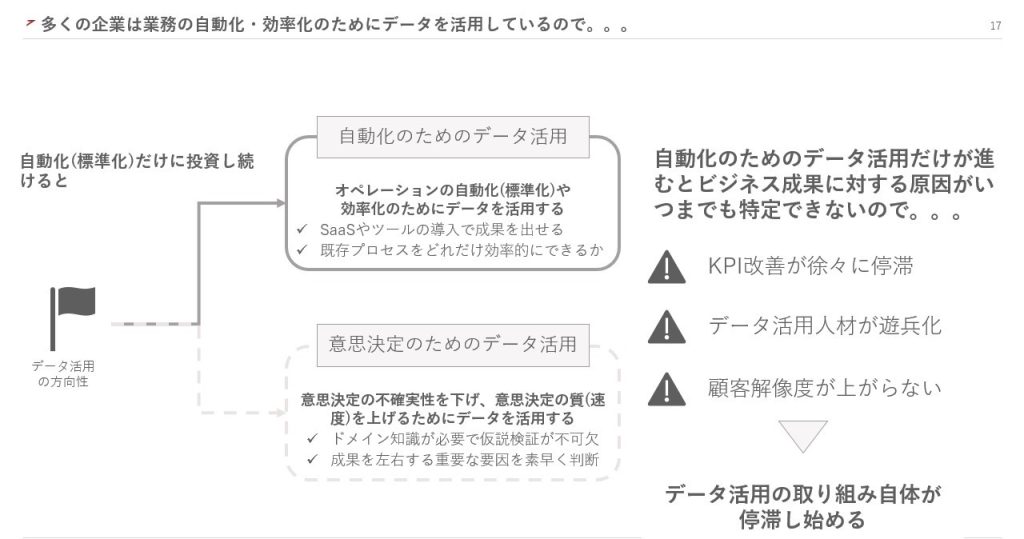
結果に関するデータが蓄積されても、ビジネスの成果に対する原因は特定できません。そのため、KPIの改善が徐々に停滞し、データ活用人材のリソースを持て余すことになります。顧客の解像度も上がらず、結果としてデータ活用の取り組みが停滞しはじめるのです。
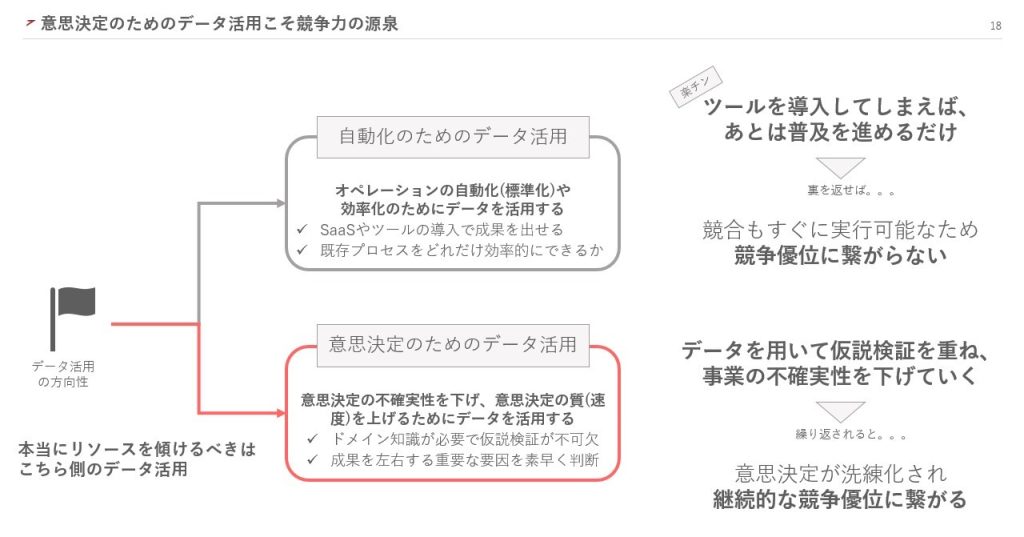
したがって、私は「意思決定のためのデータ活用」にリソースを集中させるべきだと考えています。「意思決定のためのデータ活用」とは、意思決定の不確実性を下げ、質やスピードを上げるためのデータ活用です。
前述の通り、「自動化のためのデータ活用」では、ツールを導入し普及を進めるだけで業務を効率化できます。しかし、競合も同じ施策をすぐに実行できるので、競争優位には繋がりません。
一方「意思決定のためのデータ活用」では、データを用いて仮説検証を重ね、事業の不確実性を下げていきます。そのため、競合と比べて意思決定が洗練され、継続的な競争優位性に繋がるのです。
では、ビジネスの成果に影響する「意思決定のためのデータ活用」がなぜ進まないのでしょうか。理由として、次の3点が挙げられます。

1点目は、顧客の行動の原因を推定するデータが収集される仕組みがないことです。
オペレーションの遂行に必要な「結果」に関するデータは、自然に蓄積されます。しかし、オペレーションの改善に必要な「原因」に関するデータは、積極的に取得する仕組みがなければ蓄積されません。また、「原因」に関するデータは効果の見積もりが難しいため、取得に消極的な企業が多いのも事実です。
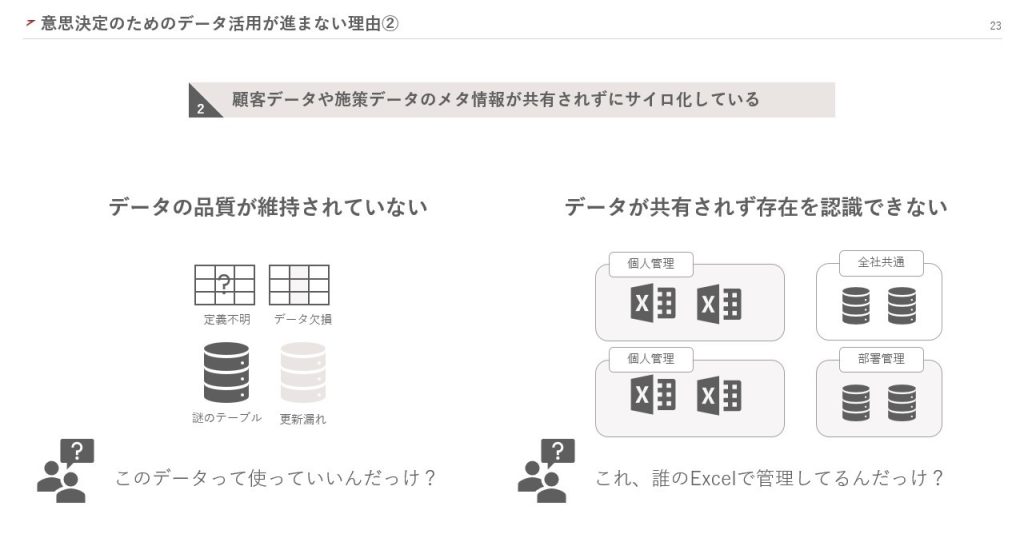
2点目は、顧客データや施策データのメタ情報が共有されずにサイロ化していることです。サイロ化とは、組織内でデータが孤立し、共有されていない状態を意味します。
そもそもデータのメタ情報が定義されていないと、データが格納されたテーブルがあっても使っていいかわからない状態になります。そして、データの欠陥が放置され、品質が維持されなくなるのです。その結果、データを使うこと自体にリスクが伴い、意思決定に活用できないという問題が生じます。
また、データを個人のExcelで管理していると、組織内で内容が共有されません。マーケティング施策によってユーザーの行動に変化があっても、データが共有されていなければ原因を特定できないでしょう。そもそもデータが存在するのか、お互いに把握できていないケースも見受けられます。
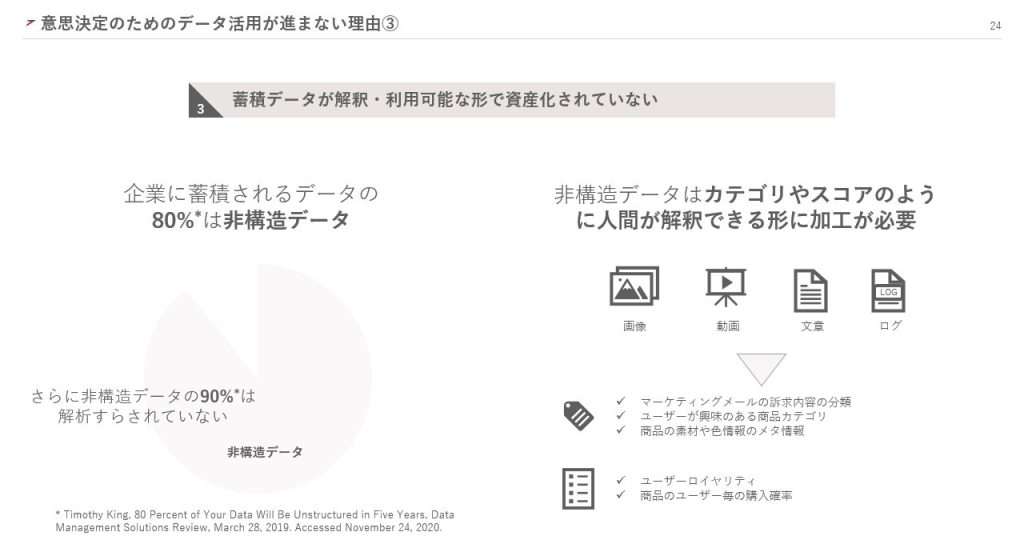
3点目は、蓄積データが解釈・利用可能な形で資産化されていないことです。
ある調査では、企業に蓄積されるデータの80%が非構造化データだとされています。非構造化データとは、構造が定義されておらず、意味を解釈しづらいデータのことです。しかも、非構造化データの90%は解析すらされていないのが現状です。
非構造化データを活用するには、カテゴリやスコアのように人間が解釈できる形に加工する必要があります。例えば、画像や動画、文章などの情報から、マーケティングメールの訴求内容を分類したり、ユーザーが興味のある商品カテゴリを分析したりといった加工が必要です。また、ユーザーロイヤリティやユーザーごとの購入確率なども、解釈可能なスコアに加工して保存する必要があります。
次に、「意思決定のためのデータ活用」を支援した事例をお話しします。

こちらは、店舗とECサイトを展開するアパレル企業で、商品販売を支援した事例です。シーズンごとに新商品の販売計画を立てており、マーケットや顧客のデータを活用して計画の精度を上げたいという依頼でした。
支援前は、新商品の販売計画が担当者個人の見積もりによるものでした。そのため、計画の根拠が統一されておらず、販売継続・中止の意思決定が曖昧になるという課題があったのです。
さらに、販売計画よりも売れたものは継続し、売れなかったものは中止するというフローを毎シーズン繰り返していました。このままでは、顧客の解像度も意思決定の質も上がりません。
このような依頼の場合、まずはクイックに意思決定の基準となる指標をモデル化します。これは運用で使うためのモデルではなく、原因となるデータが揃っているか判断するために使うためのモデルです。
具体的なアプローチは、次の通りです。

まず新商品の販売数を予測するために、誰がいつ新商品に興味を持ち、どれぐらいの人が買うのかという仮説を洗い出します。その上で、仮説をデータで表現できるか検討し、表現できた要素をもとに数理モデルを構築します。そこから実績値と数理モデルの予測値を比較し、どの程度乖離があるのか、乖離の原因は何かを考察するのです。最後に、乖離の原因が生じている可能性が高いデータを意思決定に活用する方針を立てます。
ここでは、業務プロセスやデータ管理状況の把握を省略しています。なぜこのように乱暴なアプローチを採用しているのかと言うと、まずは、意思決定に必要なデータが活用可能な状態かを素早く的確に判断できるからです。

仮説出しの段階では、販売計画の根拠を言語化する必要があります。すると、人によって想定している影響要因が異なることがわかるでしょう。また、前年比+5%のように予測ではなく目標値を入れているだけのケースも明らかになります。
次に、仮説をデータで表現する段階では、そもそもデータが存在しないことを認識できます。データは存在するものの、正しいデータかわからない場合もあるでしょう。ログに関しても、仮説を表現するためには加工が必要な場合があります。
実際にモデル化していくと、利用できるデータが限られていることに気がつきます。また、評価データごとに結果にバラつきがあると、運用が難しいと判断できるでしょう。
誤差検証の段階では、現時点で表現可能なデータでは不十分だとわかります。ここではじめて、データの蓄積にリソースを割くべきだという議論ができるようになるのです。また、当初重要だと考えていた原因の影響が小さく、仮説の再検討が必要だということもわかります。
最後に、データ資産化の方針を策定する段階では、蓄積されていないデータをどのように収集するかの検討がはじまります。そして、蓄積されていても利用できていないデータについては、整備することで方針を策定できるようになるのです。

このプロセスを何度も繰り返すことで、新商品の販売数をシミュレーションできるようになります。個人の暗黙知だった仮説が組織全体の形式知となり、必要なデータを収集・蓄積して活用できるようになるからです。
これにより、成功か失敗かではなく、自分たちがまだ把握できていない部分の解明を重視するようになります。結果として、前年を踏襲した計画の策定ではなく、意思決定の不確実性を下げることに意識を向けられるのです。
【関連】【アパレル×DX】先進企業に学ぶデータ分析とマーケティングのあり方とは?

また、意思決定のPDCAサイクルにもデータ活用が組み込まれるようになります。
Planの段階では、販売者個人の見積もりではなく、シミュレーション結果を加味した販売計画を立てられます。
Doの段階では、新商品案を比較し、見込みのある商品だけを選定して市場に投入することが可能です。シミュレーション結果が悪い商品は、稟議で棄却するフローを組み込むこともできるでしょう。
Checkの段階では、販売状況の評価だけでなく、シミュレーション結果との誤差の要因を考察できます。
Doの段階では、予測結果に基づき継続すべきか判断し、必要なデータを収集してモデルに取り込むことが可能です。
今回の事例では、意思決定の不確実性を下げるための取り組みを続けた結果、売れ残るリスクの高い新商品を高い精度で事前予測できるようになりました。シミュレーション結果を通して、予算配分の意思決定が効率的になったといえます。

データを用いた仮説検証をしていない場合、施策の結果だけを評価し、個人の暗黙知をベースに業務を遂行することになります。マーケティング施策がギャンブルのように行われている状態です。
一方、今回のように仮説検証をすると、施策の影響要因となるデータを継続的に収集・管理できるようになります。これをモデルに反映させることで、組織的な知見をベースに業務を実行できるのです。そして、マーケティング施策の影響要因が明らかになり、組織としての意思決定のスピードや質が向上します。
では、どのようにデータ資産化を進めていくのでしょうか。
そもそもデータ資産化とは、ビジネスの意思決定に活用可能な状態でデータが管理されている状態を意味します。なぜデータの資産化が必要かというと、原因を特定するためのデータは、戦略的に収集管理しなければ活用できるようにならないからです。顧客データを意思決定に反映させていくことで、マーケティングの施策の不確実性を下げることができます。
データ資産化には、「収集」「蓄積」「拡張」「資産化」のステップがあります。
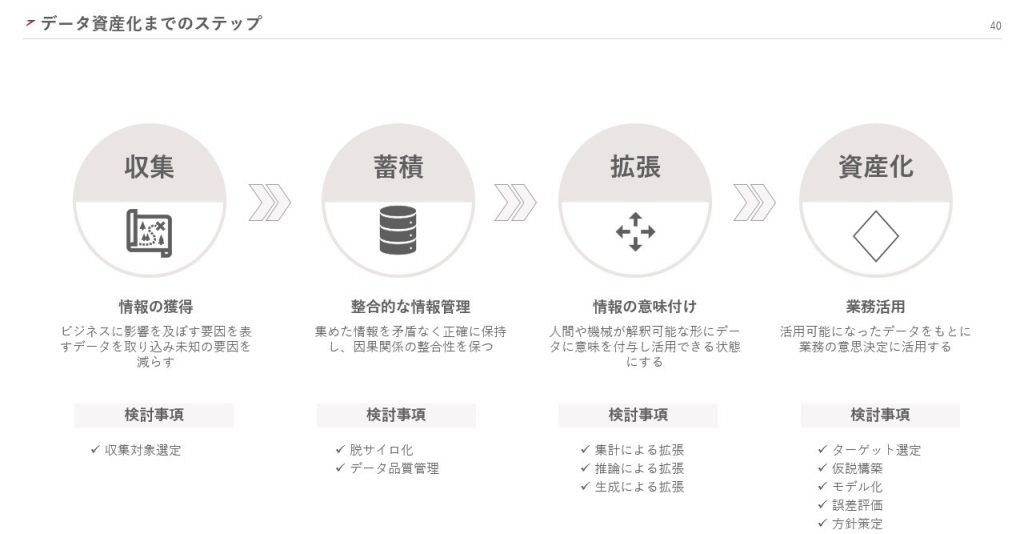
ここで大切なのが、何をデータとして収集し資産化すべきか設計することです。そのため、資産化の実行は「収集」からスタートしますが、設計は「資産化」からスタートすることに注意してください。
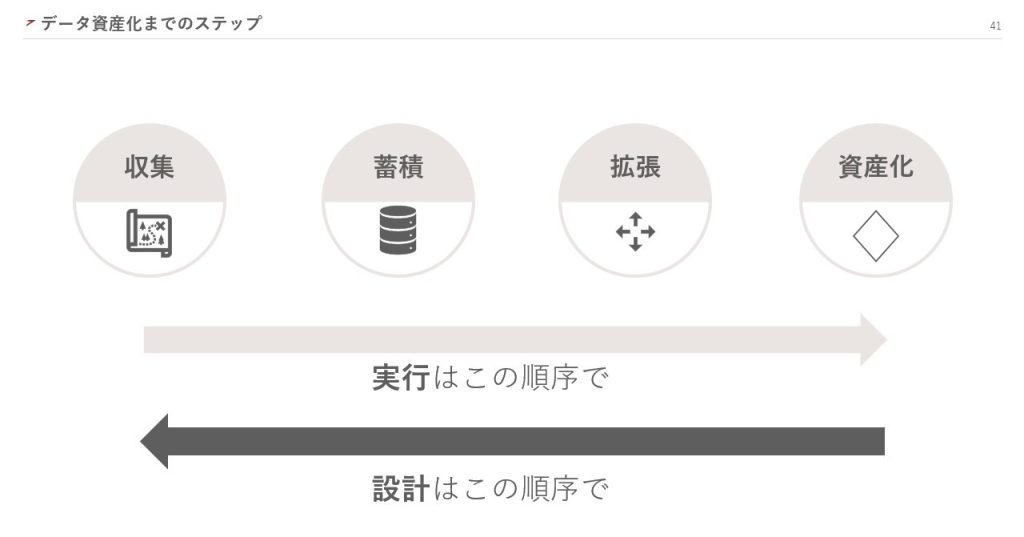
ここから、各ステップの内容について詳しくお話しします。
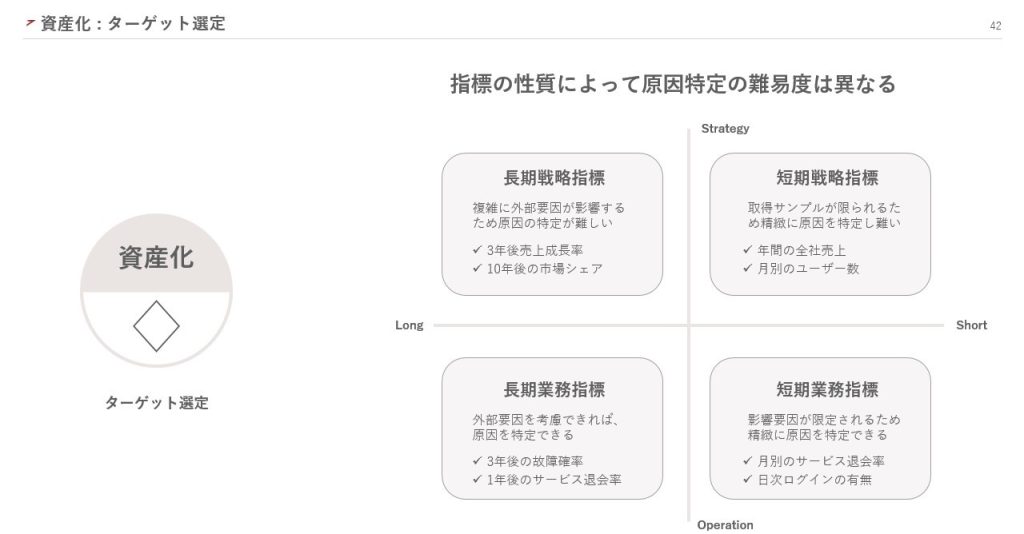
「資産化」のステップでは、まず不確実性をコントロールするターゲットを選定します。
このとき、指標の性質によって原因特定の難易度が異なる点に注意が必要です。例えば、長期戦略指標は外部要因が複雑に影響するため、原因特定が難しいとされています。はじめは原因を特定しやすい短期業務指標から選ぶとよいでしょう。

ターゲットを選定したら、仮説構築を行います。仮説構築とは、選定した指標が何に影響を受けて決まるのかを言語化するフローです。実際の業務担当者が自由に仮説を設定しましょう。

次に、言語化された仮説をモデル化します。初回設計時は、仮説のうちデータで表現可能な要素に絞ってモデリングしましょう。2回目以降は、データ資産化で表現可能になった要素を加えてモデルを更新します。
モデルには、統計モデル、機械学習モデル、深層学習モデルの3種類があります。それぞれ解釈のしやすさや表現力などが異なるため、選択するアプローチに応じたモデル構築が必要です。

モデル化ができたら、予測値と実績値を比較して大きな乖離が生じる理由を考察します。予測値や実績値が異常な値となる場合や、分布に偏りが見られる場合は、原因の特定も必要です。これにより、影響が大きい未考慮の原因データが明らかになるため、優先的に資産化の方針を策定します。

「拡張」のステップでは、人間や機械が解釈できるようデータに意味を付与します。方法は大きく3つあります。
1つ目は、集計による拡張です。ツールを使い、クロス集計や条件分岐により意味を付与します。
2つ目は、推論による拡張です。機械学習により、顧客別の購買購入確率や嗜好カテゴリなどを作成することで顧客情報を意味づけします。
3つ目は、生成による拡張です。深層学習により、商品レビューや広告クリエイティブのカテゴリを理解できるデータとして保持します。

次に、「蓄積」です。
データマネジメントの中でも、資産化においてはデータの共有と品質管理が非常に重要です。個人が管理するデータフォーマットを整え、いかに組織内で共有するのかが鍵となります。また、因果関係の逆転やデータリークが生じないデータマートを構築し、利用時の整合性の手間を減らす必要もあります。

最後に、「収集」です。基本的には、収集インパクトとコストを考慮しながらデータの範囲を拡大していきます。
「0 Party Data(※Forrester Research社による造語)」とは、ユーザーフィードバックのように、直接行動の原因を認識できるデータのことです。収集するにはユーザーの同意やアクションが必要ですが、非常に重要なデータとなります。
「1st Party Data」とは、個人を特定して行動の原因を推定できるデータのことです。自社保有の顧客データなどが該当します。
「2nd, 3rd Party Data」とは、集団の行動傾向を推定できるデータのことです。競合の情報や世の中全体のトレンドを考慮する場合に必要となります。
これらのステップを業務と連動して進めていくことで、データを資産化できるようになります。
最後に、デジタルビジネスでありがちな課題を例に、データ資産化の実現方法を紹介します。
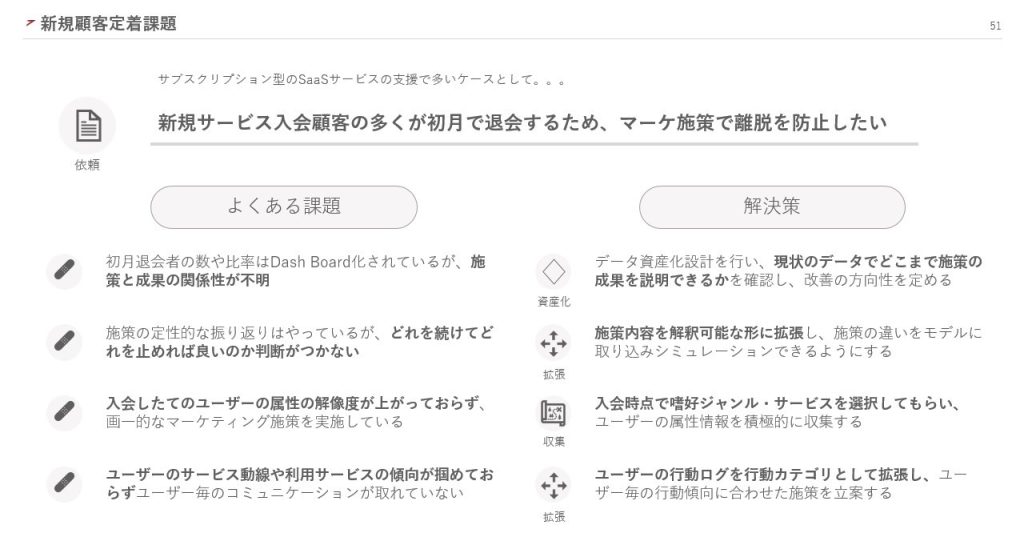
まずは、新規サービスに入会した顧客が初月で退会するのを防止したいという依頼です。こちらは、サブスクリプション型のSaaSサービスで多く見られます。
例えば、初月の退会者数や比率をDash Boardで管理していても、施策と成果の関係性を把握できていないことがあります。この場合、まずはデータ資産化の設計から開始します。現状のデータでどこまで施策の成果を説明できるか確認し、改善の方向性を定めていく方法です。
また、施策の定性的な振り返りはできているものの、どれを続けてどれを止めればいいか判断できないこともあります。この場合、施策内容をデータ化できていないことが原因である可能性があります。そのため、施策内容を解釈可能な形に拡張し、施策の違いをモデルに取り込みシミュレーションできるようにしています。
入会したてのユーザーの属性がわからない場合もあります。既存のプロセスでは、入会後の限られたデータでしか属性を推測できません。そこで、入会時点で嗜好ジャンルやサービスを選択してもらい、データを収集するプロセスを追加する形で解決を図ります。
なお、ユーザーのサービス動線や利用サービスの傾向が掴めていなければ、ユーザーごとのコミュニケーションが取れません。この場合、ユーザーの行動ログを行動カテゴリとして拡張します。そして、ユーザーごとの行動傾向に合わせた施策を立案しています。
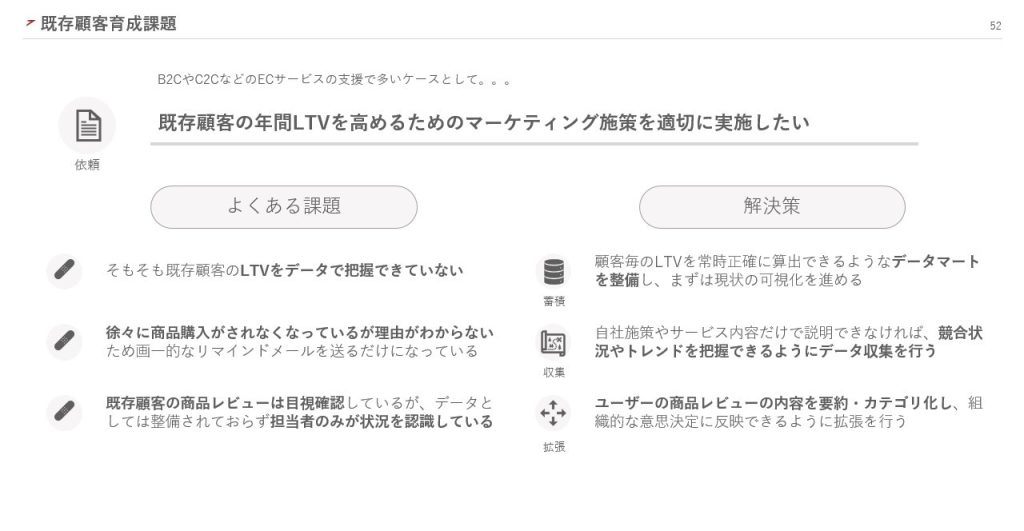
次に、既存顧客の年間LTVを高めるマーケティング施策を実施したいという依頼です。こちらは、BtoC、CtoCのECサービスで多く見られます。
まず、既存顧客のLTVを把握できていない可能性があります。この場合、顧客ごとのLTVが正確に算出できるデータマートを整備し、現状を可視化する必要があります。
また、商品が購入されなくなる理由がわからず、画一的なリマインドメールを送るだけになっている場合もあります。自社の施策やサービス内容だけで理由の説明が難しければ、競合やトレンドを把握できるようなデータ収集が必要です。
既存顧客の商品レビューは担当者が目視で確認しているものの、データとして整備されていないこともあります。この場合、商品レビューの内容を要約・カテゴリ化し、組織的な意思決定に反映できるように拡張します。
企業のデータ活用が停滞するのは、「自動化のためのデータ活用」が優先されていることが原因です。意思決定に必要な「原因」に関するデータが企業に蓄積されにくい構造を改善する必要があります。
そして、データの資産化が必要な理由は、意思決定の不確実性を下げるために、目的に合わせた能動的なデータ収集・管理が必要となるからです。データ資産化の戦略に沿って、収集・蓄積・拡張・資産化を継続的に実施することで、段階的に意思決定の不確実性を下げることができます。
データ活用やAIを用いたDX事例がブレインパッドでは複数ございます。顧客データの資産化への取り組みステップについてご相談がありましたら、ぜひブレインパッドにご連絡ください。当社の専門部隊がみなさんのソリューション化をご支援いたします。
記事・執筆者についてのご意見・ご感想や、お問い合わせについてはこちらから
あなたにオススメの記事

2023.12.01
生成AI(ジェネレーティブAI)とは?ChatGPTとの違いや仕組み・種類・活用事例

2023.09.21
DX(デジタルトランスフォーメーション)とは?今さら聞けない意味・定義を分かりやすく解説【2024年最新】

2023.11.24
【現役社員が解説】データサイエンティストとは?仕事内容やAI・DX時代に必要なスキル

2023.09.08
DX事例26選:6つの業界別に紹介~有名企業はどんなDXをやっている?~【2024年最新版】

2023.08.23
LLM(大規模言語モデル)とは?生成AIとの違いや活用事例・課題

2024.03.22
生成AIの評価指標・ベンチマークとそれらに関連する問題点や限界を解説













