



メルマガ登録
-
テーマから探す
-
技術から探す
-
業界・事例から探す
-
関連トレンドから探す
テーマから探す
技術から探す
業界・事例から探す
関連トレンドから探す


こんにちは。株式会社ブレインパッドでデータサイエンティストを務める辻です。
LLMとは、大量のテキストデータを学習し、人間が書いたかのように自然な文章を生み出せるAIモデルのことです。ChatGPTをはじめとする生成AIの土台となる技術として注目を集めており、DXや業務効率化の現場でも一気に導入が広がっています。
ここでは、LLMの仕組みや特徴、生成AIとの違い、実際の活用事例まで、ひととおり整理して解説していきます。
LLM(大規模言語モデル)は、自然言語処理(NLP)の領域で使われる深層学習モデルの一つで、膨大なテキストデータを学習することで、人間のような自然な言葉の生成や理解を可能にしている技術です。
もう少し技術寄りに踏み込むと、LLMは深層学習を使った非常に複雑なモデルで、その土台にあるのがニューラルネットワークと呼ばれる仕組みです。
この仕組みは、人間の脳のニューロンの働きをコンピュータ上で模した計算モデルにあたります。
ニューラルネットワークは複数の層からなる構造を持ち、入力されたデータを受け取りながらパターンを学習して、予測や分類を行います。LLMの場合は、巨大なテキストデータをこのネットワークに通し、大量のパラメータを少しずつ調整しながら言語の構造を学ばせていく、というイメージです。
代表的なLLMとしては、次のようなものが挙げられます。
Gemini、GPT、Llamaは、人間が書いた文章とほぼ遜色のないレベルで流暢かつ論理的なテキストを自動生成できるモデルです。いずれも数十億規模のパラメータからなる巨大なニューラルネットワークで、膨大な量のテキストデータをもとに学習が行われています。
LLMは機械翻訳やテキスト要約、対話システムといった自然言語処理の主要なタスクと相性がよく、近年では人間並みの精度を出せるところまで来ています。
【関連記事】
ChatGPTとは?使い方・始め方・仕組み・最新の活用事例を一挙ご紹介!
LLMの用途は、文章生成のような身近なものから業務支援まで本当に幅広いです。
ここでは、LLMが得意とする代表的な6つのタスクと、それぞれのメリットを見ていきます。
LLMはブログ記事やビジネスメール、業務レポート、さらには小説のような創作文まで、いろいろな種類の文章を自動で書き起こすことができます。キーワードやテーマを伝えるだけで、構成の整った自然な文章を短時間で出してくれるのが大きな特徴です。
ライティングにかかる時間を短くできる、表現の幅を広げられる、アイデア出しがスムーズになる、といったメリットがあります。文章校正にも対応しており、誤字脱字のチェックや言い回しの修正、トーンの調整までまとめて任せられます。
マーケティングの現場では、SEO記事の初稿づくりや広告コピーの作成にLLMを使う企業が増えており、制作コストを抑えつつ品質も安定させる、という両立が現実的になってきました。
LLMは、長文の資料や会議の議事録、調査レポートからエッセンスを抜き出す要約タスクが得意です。数十ページに及ぶドキュメントでも、「3行で要約して」「重要ポイントを箇条書きで」と頼めば、必要な情報だけを整理して返してくれます。
膨大な情報を短時間で押さえられるので、意思決定のスピードが上がるのが大きな利点です。経営層や管理職が抱える情報処理の負担を減らせるほか、マルチモーダル対応のLLMなら、会議の録画ファイルを音声から文字起こしし、議事録としてまとめるところまで一気通貫でこなせます。
多言語間の高精度な翻訳や、外国語でのチャットボット応対にもLLMが使われています。
従来の機械翻訳と違い、文脈や業界特有の専門用語、文化的なニュアンスまで踏まえた自然な訳文を出せるのが強みです。
グローバル展開での言語の壁を下げられる、翻訳コストを抑えられる、リアルタイムでコミュニケーションが取れる、といったメリットがあります。指示の出し方を工夫すれば、地域ごとの商習慣や文化的背景を考慮したローカライゼーションにも対応できるため、越境ECや海外マーケティングの現場でも活用が進んでいます。
LLMはプログラミング言語も学習でき、自然言語で指示するだけでソースコードを書いてくれたり、既存コードのバグを見つけて修正案を出してくれたりします。GitHub CopilotやClaude Codeといった開発支援ツールは、まさにこの仕組みを応用したサービスです。
コーディングのスピードアップ、デバッグ作業の効率化が大きなメリットです。
エラーメッセージを貼るだけで原因と修正案を提示してくれるので、エンジニアにとっては学習コストの軽減にもつながります。非エンジニアでも自然言語で簡単なスクリプトを作れるようになり、業務の内製化を後押ししてくれる存在にもなっています。
LLMは、人間と自然に会話できる対話AI(チャットボット)のベース技術としても活躍しています。単純なFAQ応答にとどまらず、文脈をふまえた込み入ったやり取りや、過去の会話履歴を参照した一貫性のある応答もできます。
24時間365日の顧客対応ができる、対応品質を均一に保てる、カスタマーサポートにかかる人件費を削減できる、といった点が主な利点です。
応対内容を分析することで顧客のニーズを掴み、サービス改善につなげられる、といった副次的な効果も期待できます。
最近のLLMは、テキストだけでなく、画像・音声・動画・センサーデータなど、複数の種類の情報(モダリティ)を横断的に扱えるマルチモーダルLLMへと進化しています。
1つのプロンプトで画像の中身を説明させたり、動画を要約させたり、音声を文字起こしして分析させたりと、かなり高度な処理ができるようになってきました。
OpenAIの「GPT-5.5」、Googleの「Gemini 3 Pro」、Anthropicの「Claude Opus 4.7」、Metaの「Llama 4」などがマルチモーダル対応の代表例で、100万トークンを超える長大なコンテキストを扱えるモデルも登場しています。
こうした進化によって、医療画像の診断支援、製造現場の異常検知、ロボット制御、カメラ映像とテキスト指示を組み合わせた業務自動化など、これまでのテキスト処理の枠を越えた応用範囲が一気に広がっています。
マルチモーダル化は、LLMが単なる「言語モデル」から「感覚を統合した汎用AI」へ進化していくうえでの大きな節目と言えるでしょう。
【関連記事】
マルチモーダルAIの導入事例を紹介!代表モデルや業界別の活用方法とは?
マルチモーダルLLMとは?LLMとの違いや導入するメリットについて解説
LLMは、単語どうしの関係を学習しながら、次にくる言葉を予測する仕組みで動いています。
ここでは、プロンプト(指示)を受け取ってから自然な文章として出力されるまでの流れを、5つのステップに分けて見ていきます。
最初のステップは、入力された文章を「トークン」と呼ばれる最小単位に分割する処理です。英語なら単語や句読点、日本語なら単語やサブワード(単語の一部)が、それぞれトークンの単位になります。
たとえば「生成AIは便利です」という文字列なら、「生成」「AI」「は」「便利」「です」のように分割されます。
LLMは人間の文章をそのままの形で扱えないため、いったんモデルが処理できる形に変換する必要があるわけです。分割の細かさはモデルによって違い、扱えるテキスト量(コンテキスト長)や生成の品質に大きく影響します。
トークンに分けただけでは、コンピュータはまだ計算ができません。そこで各トークンを多次元の数値データ(ベクトル)に変換していきます。
この処理は「エンベディング(埋め込み)」とも呼ばれます。
ベクトル化することで、単語の意味的な近さや、文脈上の関連性を数値空間の中で表現できるようになります。
たとえば「犬」と「猫」のベクトルは近い位置に置かれ、「犬」と「自動車」のベクトルは離れた位置に置かれる、といった具合です。こうした数値表現が、LLMの言語理解の土台になっており、次の学習や文脈理解のステップにつながっていきます。
LLMは、インターネット上の膨大なテキストデータを使った「事前学習(Pre-Training)」を通じて、言語の構造や一般的な知識を身につけていきます。
この段階では、文章の穴埋めや次の単語の予測といったタスクをひたすら繰り返しながら、数十億〜数兆個におよぶパラメータを少しずつ最適化していきます。
事前学習で主に使われているのは、教師ラベルがついていないテキストから自律的にパターンを学ぶ「自己教師あり学習」という方法です。これにより、LLMは特定のタスクに縛られない、汎用的な言語能力を獲得できます。事前学習の後で、特定のタスクに合わせた「ファインチューニング」や、人間のフィードバックを使った強化学習(RLHF)を加えていくことで、より実用的な応答品質に仕上げていきます。
文脈を理解する段階で活躍するのが、Transformerアーキテクチャの中核を担うセルフアテンション機構です。
セルフアテンションは、文中のそれぞれのトークンが、ほかのどのトークンと強く結びついているかを計算しながら、文全体の意味を捉える仕組みです。
たとえば「彼は銀行でお金を引き出した」という文では、「銀行」が金融機関のことなのか川岸のことなのかを、「お金」「引き出す」といった周りの言葉との関連の強さから判断していきます。
セルフアテンションのおかげで、LLMは長い文章でも代名詞や指示語の指す先を正しく押さえられ、一貫性のある文脈理解ができるようになります。この仕組みこそが、LLMの自然な応答を支える根っこの部分です。
最後のステップが「デコード(出力生成)」です。
モデルは、ここまでのプロセスで得た文脈情報をもとに、次にくる確率がいちばん高いトークンを選び、順番に出力していきます。選ばれたトークンの並びは、再び人間が読める自然言語の文章へと変換されていきます。
この「次の単語を予測して出力する」プロセスを延々と繰り返すことで、LLMは長い文章でも一貫した内容を組み立てられます。
出力時には温度パラメータ(temperature)などの設定をいじることで、定型的な回答にするか、もっと創造的な表現にするかをコントロールできるのも面白いところです。
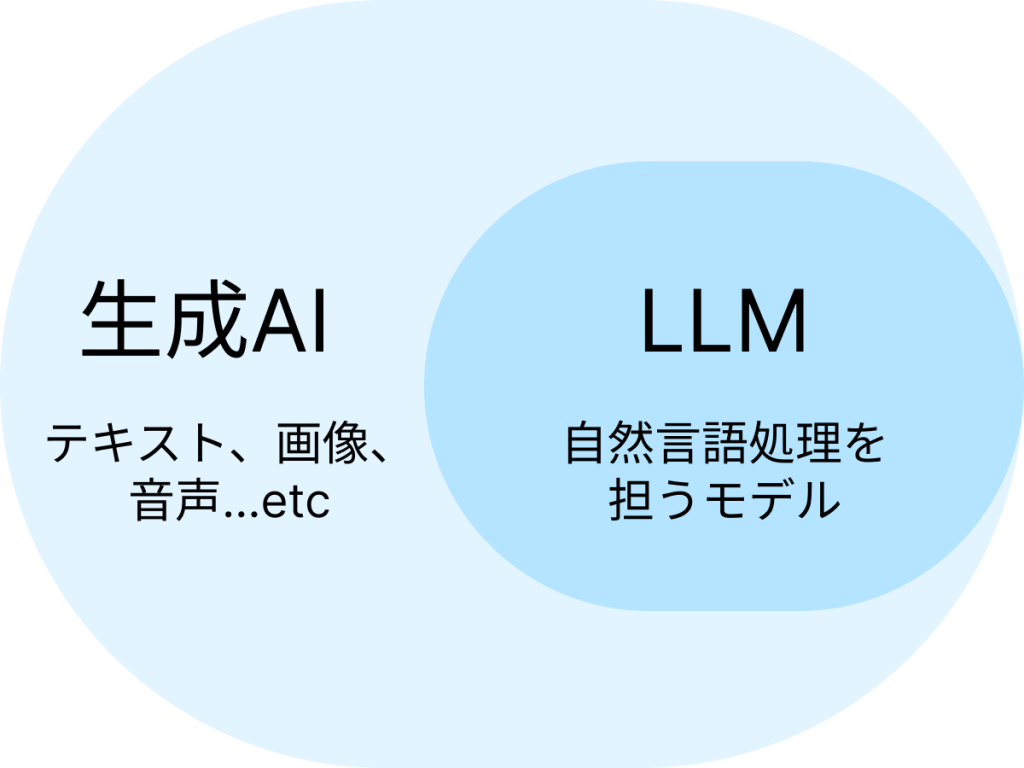
LLMは生成AIの一種で、特に言語処理に特化したモデルにあたります。
ここでは、LLMと混同されやすい「生成AI」「機械学習」「ChatGPT」との違いを順に整理していきます。
「LLM」と「生成AI」「自然言語処理」との違い
LLMは、膨大なテキストデータから言語のパターンを学び、テキスト生成や要約といったテキスト関連のタスクを高い精度でこなせる深層学習モデルです。
一方、生成AIは、テキスト・画像・音声・動画などを自律的に生み出せるAI技術全体を指す言葉で、その生成プロセスにはTransformer、GAN、Diffusionなど、さまざまな仕組みが含まれます。
画像生成で有名なStable DiffusionやMidjourney、動画生成のSoraなども生成AIの仲間ですが、これらはLLMではありません。
LLMは生成AIの中でも、特に自然言語処理(テキスト)を担うモデルという位置づけです。つまり、生成AIという大きなカテゴリの中にLLMが含まれていて、LLMは生成AIの中のひとつ、という関係になります。
【関連記事】
生成AI(ジェネレーティブAI)とは?仕組みやChatGPTとの関連性を解説
「LLM」と「機械学習」との違い
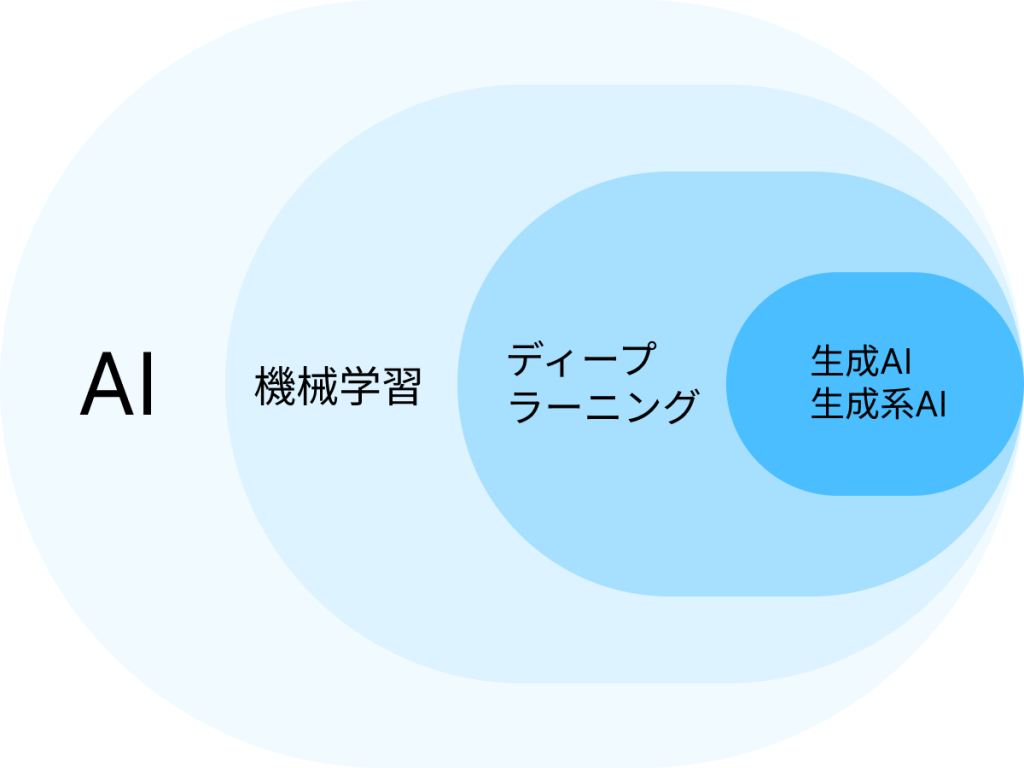
「LLM」と「機械学習」の関係をシンプルに整理すると、「LLM(生成AIの一種)」は「機械学習」の一種、という言い方ができます。
機械学習は、統計学やデータマイニングの手法を使ってコンピュータにデータから学ぶ力を持たせ、未知のデータに対しても予測や判断ができるようにする技術です。
データを読み込ませ、そこから統計的なパターンや特徴を抜き出してモデルを組み立てます。このモデルを使うことで、新しい入力データに対する分類や回帰といったタスクができるようになります。
深層学習や生成AIは、もともと機械学習の応用分野のひとつなのですが、画像認識・音声認識・会話の要約といった、従来の機械学習モデルでは手に負えなかったタスクを解けるようになってきたことで、ここまで注目を集めるようになりました。
【関連記事】
機械学習とは?3つの学習手法と知っておきたい活用事例
入社1年目が教わる「はじめての人工知能」 第5回:人工知能(AI)を支える「機械学習」の全体像
ChatGPTは、OpenAIが開発した対話特化型のAIサービスの名前で、その内側で動いているのがLLM(GPTシリーズ)です。つまり、LLMはあくまで土台となる技術で、ChatGPTはそのLLMを応用して、特に対話機能に磨きをかけたAIモデル・サービス、という関係性になります。
LLMが要約・翻訳・分類・コード生成といったあらゆる言語タスクに汎用的に対応できるのに対して、ChatGPTはユーザーとの自然な会話に重きを置き、入力に対して的確な応答を返すことに特化しています。
最新のモデルでは推論能力が大きく向上し、スピードと精度の両立も進んできました。同じような関係で、GoogleのGeminiアプリやAnthropicのClaudeアプリも、それぞれ自社で開発したLLMを応用した対話AIサービスです。
LLMはカスタマーサポートのような身近な業務から、専門領域の業務支援まで幅広く使われています。
ここでは、業務領域ごとに具体的な企業の導入事例を見ていきましょう。
カスタマーサポートの領域では、LLMを使ったチャットボットの導入が一気に進んでいます。
東京海上日動火災保険は、RightTouch社の対話型AIエージェント「スマートエージェント」を導入し、顧客のWeb行動データとLLMを組み合わせることで、保険の名義変更や契約内容確認などの手続きページへ24時間365日自動で誘導する仕組みを整えました。
これまで把握しづらかった「サイレントカスタマー」を見える化しつつ、オペレーターの負荷も同時に下げる効果が出ています。
メルカリでは、生成AI・LLMを活用した「メルカリAIアシスト」の提供をスタートし、出品商品の改善提案機能を実装しました。
出品者に対して売れやすくするためのアクションを提案することで、購入者にとっても魅力的な商品情報が並ぶ、という好循環が生まれています。
LLMの導入によって、24時間対応・対応品質の均一化・人件費削減を一度に狙える体制を築けるようになっているわけです。
【参考】
東京海上日動がRightTouchの対話型AIエージェント「スマートエージェント」を導入
メルカリ、生成AI・LLMを活用してお客さまの最適な行動を促す「メルカリAIアシスト」の提供を開始
マーケティング領域では、ターゲット分析からコンテンツ制作まで、一貫してLLMが活躍しています。LLMは大量の消費者データを分析し、行動パターンや好みを予測することで、精度の高いターゲティングを可能にしてくれます。
セガサミーホールディングスでは、画像生成AIとLLMを組み合わせてデザイン案出しのスピードを上げ、デザイン案の件数を約100倍に増やした事例が報告されています。
共同印刷でも、営業資料作成をLLMで自動化し、業務時間を約30%削減することを目標に掲げています。
広告コピーやSNS投稿、ランディングページの構成案、SEO記事の初稿づくりなど、マーケティングの幅広い業務でLLMが取り入れられており、制作スピードと品質の両立に貢献しています。
【参考】
AI×エンタメでさらなる感動体験を創出!! 玩具のデザイン案・アンケート集計にAIを導入
共同印刷、SI&Cと完全プライベート型ローカルLLMの実証実験を始動。AI活用で業務効率化と人材育成を加速
社内業務の効率化では、議事録作成・文書要約・社内問い合わせ対応といったところでLLMが大きな力を発揮しています。
パナソニック コネクトは、全社員向けのAIアシスタント「ConnectAI」を展開し、生成AI導入から1年で年間44.8万時間相当の業務削減を達成したと公表しています。
日立ソリューションズは、5000人規模の全社員を対象にAIチャットボットを導入し、社内問い合わせ対応の約30%を削減しました。
生成AIの利用率も導入前の30%から50%へ伸び、議事録作成支援も合わせて、業務効率化が大きく前進しています。NTTドコモも、社内業務を横断的に支援する生成AI基盤を全社展開するなど、大企業での全社的な導入の動きが加速しています。
【参考】
パナソニックコネクト、「聞く」から「頼む」へシフトしたAI活用で年間44.8万時間の削減を達成 | 技術・研究開発
株式会社日立ソリューションズ Alli LLM App Marketの導入事例やシステム構築例を紹介
専門業務の支援領域でも、高度な知識を必要とする現場でLLMの活用が広がっています。
三井住友海上火災保険では、NECの日本語LLM「cotomi」を活用し、照会応答機能の業務特化型LLMを開発しました。
また、西松建設が導入した燈株式会社の「AKARI Construction LLM」は、建設業界ならではのノウハウを内製化し、若手への技術継承を後押しする専門特化型LLMの代表例です。
富士通もSalesforceのEinstein for Serviceを採用し、コンタクトセンター業務で平均後処理時間を89%、平均処理後時間を86%削減するなど、法務・医療・金融・建設といった専門知識が問われる領域で、LLMが業務の質とスピードの両方を引き上げています。
【参考】
照会応答機能の高度化に向けた業務特化型LLMを開発
文章生成AIを導入し業務で利用開始
富士通、コンタクトセンター効率化と高度化による顧客体験の向上のためSalesforceのカスタマーサービス向け生成AIの採用を決定
ナレッジ管理の領域では、社内に積み上がっている大量のドキュメントから必要な情報を引き出す「エンタープライズサーチ」や「RAG(検索拡張生成)」といった応用技術にLLMが組み込まれています。
社内マニュアルや技術文書、FAQなどをベースにすれば、社員は自然言語で質問するだけで必要な知識にアクセスできるようになります。
サーキュレーションでは、従業員が主導して生成AIアプリを開発しており、現場レベルでのナレッジ活用が着実に進んでいます。
これまで属人化していた業務知識を標準化したり、新入社員のオンボーディングを早めたり、ベテラン社員の暗黙知を形式知に落とし込んだり、と、長らく難しかった組織的な知識マネジメントの課題を、LLMが一気に解きほぐしつつあります。
【参考】
■導入事例■【サーキュレーション様】データプライバシーを担保しながら、数十個の生成AIアプリをリリースし飛躍的な生産性向上を実現
LLMの課題やリスクとしてよく挙がるのは、精度・コスト・セキュリティといったあたりです。ChatGPTやClaudeが広く使われるようになったことで、運用現場からも新しい課題が次々と上がってきています。
ここでは、技術・セキュリティ・社会という3つの切り口で整理してみます。
LLMを業務利用する際に最も警戒すべきは、以下の技術的な課題です。
LLMをビジネスで活用するなら、次のセキュリティ・プライバシー面のリスクへの対策は必ず押さえておきたいところです。
技術面だけでなく、社会や個人へのインパクトも軽視できないリスクです。
LLMが抱える課題やリスクに対しては、技術的な対策をいくつか組み合わせて打つのが基本です。
ここでは、ガードレール・コンテンツモデレーション・データ管理・プロンプト最適化という4つの観点から、具体的なやり方を紹介します。
ガードレールは、LLMが出してよい内容や形式、実行してよいアクションをあらかじめ決めておくための制約の仕組みです。「政治的な発言はしない」「暴力的な表現は使わない」「個人情報は出力しない」といったルールを事前に設定しておくことで、LLMの出力品質と安全性を同時に高められます。
ガードレールはLLMとユーザーの間に立つ安全装置のような役割を果たし、ポリシーに反する入出力をフィルタリングしたりブロックしたりします。
これはモデル自体を訓練し直す(アライメント)アプローチとは違い、外側からLLMをコントロールする考え方です。NVIDIAの「NeMo Guardrails」、AWSの「Bedrock Guardrails」、Azureの「Content Safety」など、各プラットフォームが専用ツールを提供しており、ハルシネーションやプロンプトインジェクション攻撃への対策としても役立ちます。
コンテンツモデレーションは、LLMの入出力を事前または事後にチェックし、不適切な内容を見つけて削除・修正する仕組みです。テキストだけでなく画像・動画コンテンツの自動分析にも応用されており、有害な表現や差別的な発言、暴力的・成人向けのコンテンツなどを検知してブロックします。
人の手による精査は精度が高く、文脈に応じた判断もできる一方で、コストと時間がかかります。逆にAIを使った自動モデレーションはコスト効率に優れますが、文脈の読み取りには弱いという弱点があります。
実務では両者を組み合わせたハイブリッド運用が一般的で、バイアスや偽情報が広まるのを抑える重要な防波堤として機能しています。
データ管理とは、LLMの学習や運用に使うデータの品質・セキュリティ・ガバナンスをまとめて担保する取り組みのことです。具体的には、個人情報や機密情報のマスキング、アクセス権限の厳格な設定、データの出所・更新頻度・正確性の継続的なチェック、利用ログの記録と分析、といったあたりが含まれます。
特に、社内データを使ったファインチューニングやRAGの構築では、学習データの鮮度と正確さがそのまま出力品質に効いてくるため、データマネジメント体制の整備は外せません。
GDPRや個人情報保護法といった法令への対応もデータ管理の大事な要素で、適切なデータ管理こそが、情報漏洩や著作権リスクを最小化するための第一歩となります。
プロンプト最適化は、LLMに渡す指示文(プロンプト)を工夫することで、出力の精度・安全性・再現性を高めるテクニックです。役割の明示(「あなたは〇〇の専門家です」)、出力形式の指定、制約条件の明記、具体例の提示などが代表的な手法として知られています。
セキュリティを高めたいなら、入力データとシステム指示をはっきり分ける、外部からの入力をそのまま実行させない、出力結果は必ず人間がレビューする、といった設計が効きます。
プロンプトに「個人情報は含めない」「機密情報を扱う場合は要約だけ出力」といったルールを組み込んでおくことで、プロンプトインジェクションへの耐性も高められます。
プロンプト設計はLLM活用の土台であり、運用品質を決定づける大事な対策の一つです。
最後に、LLMがどのような進化を遂げるかについて考察を述べて、本記事を締めさせていただこうと思います。
LLMの今後の進化についてですが、私は以下の三つの点でさらなる発展が見込まれると考えています。
LLMは大量のテキストデータを学習することで、自然言語処理のさまざまなタスクに対応できるようになります。
しかし、データ量だけではなく、データの質も重要です。
例えば、多様なジャンルやドメイン、言語、文化、時代などのデータを取り入れることで、LLMはより幅広い知識や文脈を獲得できます。また、データに含まれるバイアスや誤りを排除することで、LLMはより正確かつ公平な予測や推論を行えます。
また、LLMは基本的に「WEB上で収集可能なデータ」を用いて学習を行っているため、企業の機密情報や個人間の人間関係のような「WEBからは収集できない情報」に対する適切な回答は困難です。それを克服するためには、企業や個人の固有の状況や情報を踏まえて、適切に対応できるようなデータを集めてLLMを再学習させるための工夫も必要になってきます。
この「WEBから収集できない情報を学習させる技術」について例を挙げると、「ファインチューニング」があります。ChatGPTに社内文書を学習させ、社内情報をアウトプットしてくれるような仕組みの実装が可能です。これは通常のChatGPTでは実現不可能です。
以下の記事では、ChatGPTのファインチューニング実装について具体的に解説しています。あわせてご覧ください。
【関連記事】
社内文書に特化したChatGPT ファインチューニング実践編
LLMはパラメータ数が多いほど、より複雑な言語現象を捉えられると言われています。実際に、近年では数十億から数兆個のパラメータを持つ巨大なLLMが開発されており、驚異的な性能を示しています。
しかし、モデルサイズの増加は計算コストやメモリ消費も増加させるため、効率的な学習や推論の方法が求められます。また、実際のビジネス適用を考えると「人間なら数秒で終わるような応答が、LLMでは数分かかる」ような状態になってしまえば、導入はたちまち困難になります。
サービス品質の観点でも、LLMの推論の効率化は重要なトピックと考えられています。
例えば、量子化(*1)や蒸留(*2)と呼ばれる学習や推論の効率化技術を用いることで、LLMの性能を落とさずにモデルサイズを圧縮させる技術が日々発展してきています。
*1:量子化とは、モデルのパラメータ数や計算負荷を削減する一つの技術手法です。
*2:蒸留とは、すでに学習済みのモデルを模倣する一つの技術手法です。
LLMは人間の言語や知識を反映するだけでなく、人間の価値観や判断も影響を受けます。そのため、LLMは倫理的に問題のある内容を生成したり、人間に悪影響を及ぼしたりする可能性があります。
例えば、LLMは偏見や差別、虚偽や誇張などの不適切な言葉を使ったり、人間のプライバシーやセキュリティを侵害したりする恐れがあります。
これらの問題に対処するためには、LLMの開発者や利用者は倫理性と責任性を持って行動する必要があります。どんな行動かと言いますと、LLMの目的や制限を明確にし、適切な評価や監視を行い、問題が発生した場合には迅速に対応することが挙げられます。具体的には前述したコンテンツモデレーションやガードレールといった技術をさらに発展させていく必要があります。
LLMは、生成AIを理解するうえで中心になる技術です。最後に、よく寄せられる質問にお答えします。
RAG(Retrieval-Augmented Generation:検索拡張生成)とは、LLMが回答を組み立てる際に、外部のデータベースや文書から関連性の高い情報を検索・取得し、その情報を踏まえて回答を生成する技術です。「Retrieval(検索)」「Augmented(拡張)」「Generation(生成)」の頭文字を取ってRAGと呼ばれます。
LLMが学習済みの知識だけで答えるのに対して、RAGはLLMに最新情報や社内文書といった外部情報を与えたうえで回答を作る、という点が大きな違いです。これによりRAGは、LLM単体の弱点である「情報の鮮度不足」や「ハルシネーション」を抑え、モデルを再学習させなくても、企業独自の情報にもとづく正確な回答を実現できます。つまり、LLMが基盤技術で、RAGはそのLLMの能力を拡張する応用手法、という関係になります。
【関連記事】
生成AIにおけるRAGとは?検索拡張生成の仕組みから活用例や注意点を解説
2025〜2026年にかけての一番のトレンドは、LLMが単体のツールから、自律的に動くAIエージェント(Agentic AI)へと進化している点です。
自律型のAIエージェントは、目標を与えるだけで自分で計画を立て、外部ツールを呼び出しながら、複数ステップにまたがるタスクをこなしていきます。
さらに、テキスト・画像・音声・動画をまとめて扱うマルチモーダル化、100万トークンを超える長文コンテキストへの対応、ローカル環境で動く小型かつ高性能なモデル、日本語に特化した国産LLMの実用化など、進化の方向性は本当に多岐にわたります。
LLMはこれからも、私たちの働き方や暮らしを根っこから変えていく技術として進化を続けていくはずです。
LLM(大規模言語モデル)は、膨大なテキストデータを学習し、人間のように自然な文章を生成・理解できるAIモデルで、ChatGPTやGemini、Claudeといった生成AIサービスの中核を担う技術です。
トークン分割・ベクトル化・モデル学習・文脈理解・デコードという5つのステップで高度な言語処理を実現し、文章生成・要約・翻訳・コード生成・対話・マルチモーダル処理など、幅広いタスクに対応できます。
活用領域もカスタマーサポート・マーケティング・社内業務効率化・専門業務支援・ナレッジ管理など多岐にわたり、東京海上日動・パナソニック コネクト・日立ソリューションズ・富士通・三井住友海上といった国内大手企業での導入が一気に進んでいます。
一方で、ハルシネーションやセキュリティリスク、倫理的な課題への対策も欠かせません。ガードレール・コンテンツモデレーション・データ管理・プロンプト最適化を組み合わせた運用が必要になってきます。
LLMはこれからも、自律型AIエージェントやマルチモーダルモデルへとさらに進化していき、AI活用の中核技術として、企業のDX推進や社会の変革をリードする存在になっていくはずです。
自社の業務課題にどう当てはめていくかを見極められるかどうかが、これからのビジネスでの競争力を左右する鍵になっていくでしょう。
あなたにオススメの記事

2023.12.01
生成AI(ジェネレーティブAI)とは?ChatGPTとの違いや仕組み・種類・活用事例

2023.09.21
DX(デジタルトランスフォーメーション)とは?今さら聞けない意味・定義を分かりやすく解説【2024年最新】

2023.11.24
【現役社員が解説】データサイエンティストとは?仕事内容やAI・DX時代に必要なスキル

2023.09.08
DX事例26選:6つの業界別に紹介~有名企業はどんなDXをやっている?~【2024年最新版】

2023.08.23
LLM(大規模言語モデル)とは?生成AIとの違いや活用事例・課題

2024.03.22
生成AIの評価指標・ベンチマークとそれらに関連する問題点や限界を解説













