



メルマガ登録
-
テーマから探す
-
技術から探す
-
業界・事例から探す
-
関連トレンドから探す
テーマから探す
技術から探す
業界・事例から探す
関連トレンドから探す

人々の行動パターンが多様化した近年、本当の意味での「パーソナライズ」を実現するには、アルゴリズムの力を借りて個々のユーザの特徴を考慮したレコメンドを提示していくことが不可欠と感じています。
本記事では、レコメンドのアルゴリズムとしての「協調フィルタリング」、「教師あり学習」、「強化学習」の違いから、強化学習の優位性を紐解き、強化学習アルゴリズムの一例である「多腕バンディットアルゴリズム」の概要を解説し、アルゴリズムによるレコメンドの精度向上によって顧客コミュケーションがどう変化するかについて考えていきます。


従来は、大量の顧客とのコミュニケーション方法を探る上で、ユーザを人間が把握可能な数のセグメントに分け、施策を考えるという方法がとられていました。
しかし、人々の行動パターンが多様化した近年では、年代、ジェンダー、居住地などといったユーザのデモグラフィックを使ったセグメントでユーザの好みを一括りにして理解することは乱暴な方法のように感じます。
世界的に有名な、あるVODサイトでも、レコメンドに年齢、ジェンダーといった情報は使用していないと明言されています。
デモグラフィック以外のデータを用いたとしても、人々の好みのパターンは多様で、人間が把握可能な数のパターンにすべての顧客を当てはめることにも限界があります。
人々の好みが人間に把握できないほど多様化しているならば、本当の意味での「パーソナライズ」を実現するには、アルゴリズムの力を借りて個々のユーザに対するレコメンドを提示していくことが不可欠であると考えます。

レコメンドに使用されるアルゴリズムは様々ですが、ここでは協調フィルタリング、教師あり学習、強化学習という3つのアルゴリズムのカテゴリを取り上げ、特徴を解説してみます。
協調フィルタリングはレコメンドでよく使われるアルゴリズムで、「自分に似ている人が買っている商品をレコメンドされれば購入したくなるだろう」という関係を利用して、レコメンドするアイテムを提示する手法です。シンプルで効率的なアルゴリズムですが、以下のような弱点もあります。
筆者の経験として、あるECサイトでコーヒーメーカーを購入したら、コーヒー好きなユーザとの類似度が高まったためか、コーヒー関連グッズを大量にレコメンドされ、反応していないのに数ヶ月の間、同様のレコメンドをされ続けたことがあります。
このエピソードには協調フィルタリングによるレコメンドの弱点がよく現れているのではないでしょうか。
協調フィルタリングから一歩進んで、ユーザの購入、閲覧パターンの特徴量から購入しそうな商品を予測する機械学習モデルを構築し、それによりレコメンドするという手法も考えられます。このような手法は「教師あり学習」に分類されます。
この場合、購入、閲覧パターンが類似しているだけでなく、実際購入するかどうかも評価することができるため、反応がないのに同じような商品をレコメンドし続ける挙動は抑制できそうです。
しかし、
という弱点は依然として存在します。
現実には、データが十分ない状況からレコメンドを行わなければいけない状況もあります。新型コロナウイルスの流行時にもあったように、人々の行動様式が大きく変化する事象は常に起こりうるため、データが十分にたまる時が来ないということも考えられます。
また、未知のパターンに関するデータを積極的に取りに行き、素早く最適な状態に近づけるような動きができることも、小規模なサイトであったり、ニッチなカテゴリの商品など、取れるデータが少ない場合は特に重要となります。
このような状況で高いパフォーマンスが期待できるのが強化学習です。
強化学習は、データが溜まった後のパフォーマンスではなく、データが溜まり、それを利用する過程全体でのパフォーマンスの累計値を最大化する手法です。
データを溜める過程で、より効率的に最適な状態に近づけるために、「どのようにデータを取りに行くのが良いか」も最適化する観点も持っているのが教師あり学習との大きな違いです。
強化学習に分類されるアルゴリズムの一つである多腕バンディットアルゴリズムは、Webサイトでのコンテンツのレコメンド、Web広告で提示する広告コンテンツの選択など、様々な場面で利用されています。
ここでは、多腕バンディットアルゴリズムについて解説し、強化学習の特徴である「データを取りに行く過程も含めたパフォーマンスの最大化」の実例を見てみます。
ECサイトで商品をレコメンドしたり、ユーザに見せるWeb広告を選択するような状況は、「多腕バンディット問題」としてモデル化することができます。
多腕バンディット問題とは、報酬が得られる確率が異なる複数のスロットマシンがあり、決まった回数だけスロットを回して良いとする場合、どのようにスロットマシンを選択すると報酬が最大になるのか?という問題です。
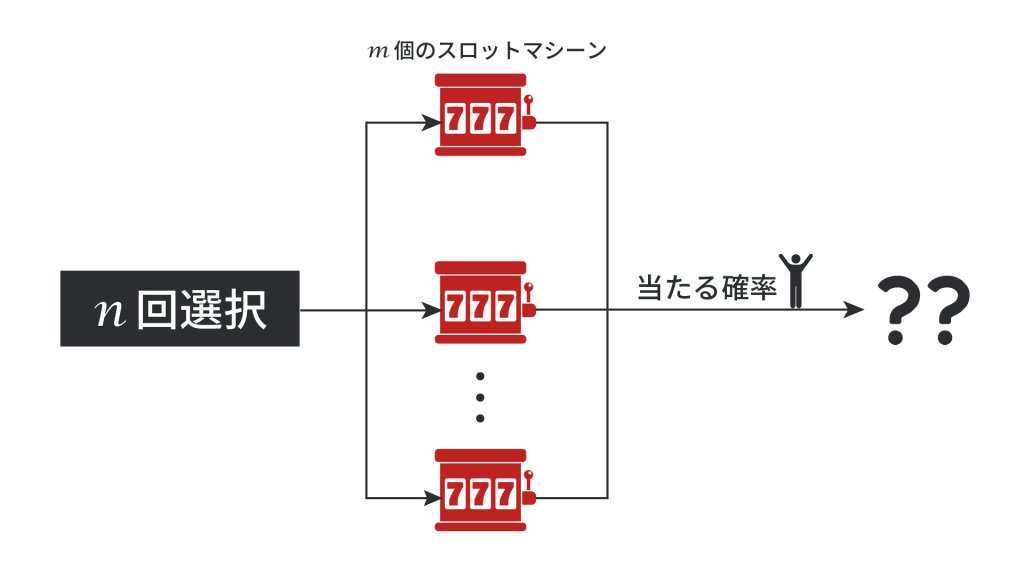
スロットが当たるかどうかは確率的であるため、ある程度の数を回さなければ良し悪しはわかりません。一方で、当たりにくいスロットをたくさん回してしまっては報酬の累計値は小さくなってしまいます。
このような状況下では、
という2つの方針が考えられますが、これらの行動には
という相反する性質があることから、これらをバランスよく行うことが最終的な報酬を最大化するためには必要となります。
多腕バンディットアルゴリズムは、このようなバンディット問題の解法となるアルゴリズムの総称で、活用、探索のバランスをとり、最終的な報酬の累計値を最大化するために利用されています。
サイトのデザインの選択などの場面でよく利用されるA/Bテストですが、これもバンディット問題に対する一つの戦略と考えることができます。
A/Bテストは、
という手順で行われますが、1.が探索のみをするフェイズ、2.が活用のみをするフェイズと考えることができます。
バンディット問題への戦略としてのA/Bテストの改善すべき点としては、以下のようなものが考えられます。
多腕バンディットアルゴリズムは、A/Bテストのように、探索フェイズ、活用フェイズというような区切りはなく、多数のコンテンツを同時に投入することも可能です。
与えられたすべてのコンテンツに対して、
の両方を評価して、現時点の情報から最善とされるコンテンツを提示することを繰り返すことで、探索・活用のバランスをとります。
シンプルな方法ですが、
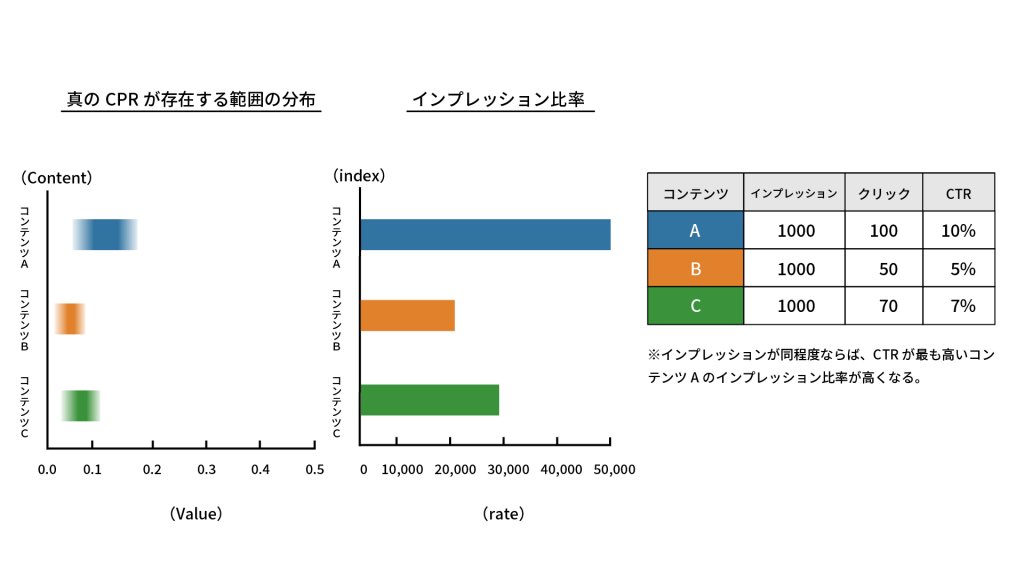
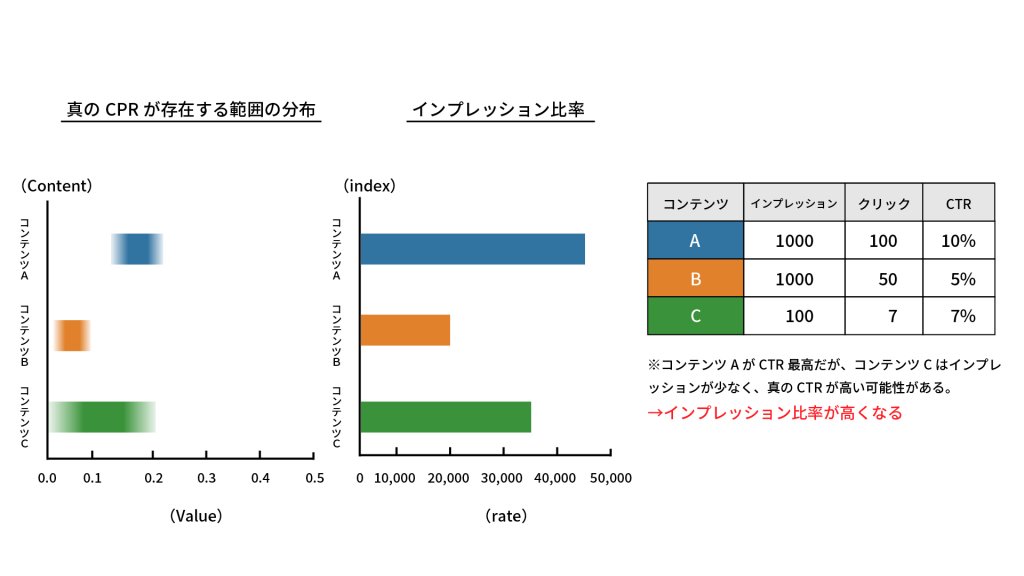
というように、状況に応じて探索、活用を使い分けることができます。
また、多腕バンディットアルゴリズムには、文脈付き多腕バンディットアルゴリズムと呼ばれるバリエーションがあり、それを利用すると、
といった「文脈」に応じたコンテンツの有効性の違いに対しても、探索、活用のバランスをとって戦略的に対応することができます。
この節では、ブレインパッド製品のCDP・Rtoasterの最適化機能”conomi-optimize”で、多腕バンディットアルゴリズムを用いてコンテンツ表示比率を最適化する機能をプロダクトとして実装した経験から、実利用での難しさや、どのような状況で特に有効であるかといった知見について解説していきます。
Rtoasterの最適化機能”conomi-optimize”を用いて、月間数千万PVの規模の実際のお客様のサイトで、バナーの表示比率最適化を行い、多腕バンディットアルゴリズムをテストした際に、多腕バンディットを現実の問題に応用するためには以下のような課題があることがわかりました。
これらの課題は、現実は理想的な多腕バンディット問題ほど単純ではないということに集約されます。それぞれの課題について詳しく解説していきます。
理想的な多腕バンディット問題では、スロットマシンの数は変化しませんが、現実のコンテンツは常に追加、削除されていきます。これにより、他のコンテンツより大幅にクリックされやすいコンテンツが追加された場合、いち早くそのコンテンツの有効性に気づかなければ機会損失が発生してしまいます。
この課題は、多腕バンディットアルゴリズムで、情報がないコンテンツに対してどの程度の報酬を期待するかを決める「初期分布」の工夫により改善することができました。
具体的には、情報がないコンテンツに対しては、既存のコンテンツのうち最も報酬の高いコンテンツの報酬と同程度の報酬を期待し、情報が得られるにつれてそれを修正していくという方法をとっています。
これにより、情報がない新規コンテンツはある程度大きなインプレッションが割かれ、いち早くそのコンテンツの有効性を確認しながら、有効性に応じてその後の比率を決めていく挙動を実現できました。
理想的な多腕バンディット問題では、スロットマシンの当たりやすさは時間変化しませんが、実際のコンテンツのクリックされやすさは様々な影響で変化します。
例えば、ユーザが同じコンテンツを見過ぎて飽きてくる効果や、ニュースやSNSで話題になって急にコンテンツがクリックされやすくなる効果など、コンテンツの有効性の変化には緩やかなもの、急激なものがあり、これらの変化に対応していくことが必要です。
この課題は、コンテンツの直近の成果を重視するようにデータを重み付けして学習することで、有効性の変化に素早く気づいてインプレッションの比率に反映する挙動に改善することができました。
理想的な多腕バンディット問題では一度に引くスロットマシンは1個ですが、現実のバナーなどのコンテンツを表示する枠は複数ある場合が多いです。
また、複数のコンテンツは横並びで表示されたり、カルーセルとして表示されるなどサイトによって様々なデザインで表示されますが、多くの場合最初の枠のコンテンツが最もユーザの目に留まりやすい傾向があり、その影響で表示枠によってクリックされやすさが変化するという要素もあります。
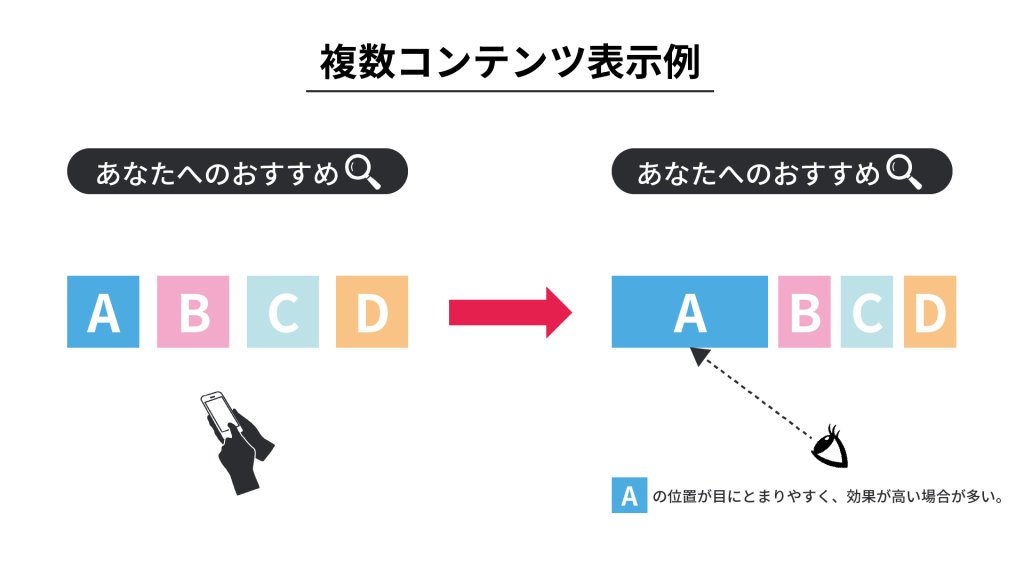
この課題に対しては、文脈バンディットアルゴリズムで「表示された位置」を文脈に加えて学習を行い、コンテンツを選ぶ際には表示された位置による効果を差し引いた期待報酬を用いて、最初の枠から順にコンテンツを選択する方法で対応しました。
ユーザに対して複数のコンテンツの組をレコメンドする問題はSlate Recommendationと呼ばれ、近年この問題に特化したアルゴリズムの研究も行われているため、そのようなアルゴリズムの採用で更に良い結果が得られるかもしれません。
実際のサイトで様々なユーザ群、コンテンツ群に対して多腕バンディットを用いた最適化を適用した結果、コンテンツ数が多く、コンテンツの入れ替わりが激しい状況で特に大きな改善が見られました。
コンテンツ数が多く、コンテンツの入れ替わりが激しい状況では、探索を戦略的に行う多腕バンディットの挙動が有利に働いたことが改善の大きな要因となっていました。
特に、「タイムセール」のような効果が高く、期限が限られているバナーが追加された際にバナーの有効性を素早く検知して大きな割合のインプレッションを割くことで、限られたタイムセール期間を有効活用できたような挙動も確認できました。
多腕バンディットアルゴリズムは実装が容易な割には拡張性があり、様々な状況に対処することができる強みがある一方で、強化学習のアルゴリズムをとしてはシンプルなものであり、コンテンツを提示したことによるユーザの状態の変化、例えばクリックベイト的なコンテンツを提示し続けることで短期的なクリックは上がってもユーザの長期的な満足度が下がってしまうような現象に対しては、対症療法的にしか対応できないという弱点もあります。
変化が少なく、最初からデータが潤沢にあるような状況では深層学習やランダムフォレスト系の複雑なモデルを用いた教師あり学習に強みがある場面もあるかもしれませんし、高い実装コストに対しても採算が取れるような大規模なサイトでのレコメンドでは、強化学習の「環境」のモデルとしてより複雑なものを使う深層強化学習系モデルに強みがあるかもしれません。
状況に合わせた適切なアルゴリズムを意図を持って選択していくことが重要となると考えています。
記事の冒頭に書いたように、ユーザの好みは人力では把握できないほど多様であるため、本当の意味でのパーソナライズを実現するには、アルゴリズムの力を借りて個々のユーザに対するレコメンドを提示していくことが必要です。
そのためには、どのようにユーザとコミュニケーションをとっていきたいか、というマーケターの意図をアルゴリズムの形で表現するデータサイエンスの領域と、アルゴリズムの力を現実の課題で発揮させるためにシステムに統合された形で実装・運用していくエンジニアリングの領域、両方のスキルセットを持ったプロフェッショナルの連携が必須であると感じています。
※DXについて詳しく知りたい方はこちらの記事をお読み下さい。
【関連】DX(デジタルトランスフォーメーション)とは?「DX=IT活用」ではない。正しく理解したいDXの意義と推進のポイント
あなたにオススメの記事

2023.12.01
生成AI(ジェネレーティブAI)とは?ChatGPTとの違いや仕組み・種類・活用事例

2023.09.21
DX(デジタルトランスフォーメーション)とは?今さら聞けない意味・定義を分かりやすく解説【2024年最新】

2023.11.24
【現役社員が解説】データサイエンティストとは?仕事内容やAI・DX時代に必要なスキル

2023.09.08
DX事例26選:6つの業界別に紹介~有名企業はどんなDXをやっている?~【2024年最新版】

2023.08.23
LLM(大規模言語モデル)とは?生成AIとの違いや活用事例・課題

2024.03.22
生成AIの評価指標・ベンチマークとそれらに関連する問題点や限界を解説













