



メルマガ登録
-
テーマから探す
-
技術から探す
-
業界・事例から探す
-
関連トレンドから探す
テーマから探す
技術から探す
業界・事例から探す
関連トレンドから探す

前回の記事では、RAG(検索拡張生成)の精度向上において、メタデータフィルタリングとデータ前処理が、検索対象の絞り込みとノイズ除去に不可欠であることを解説しました。これらの手法は、適切な文書を見つけるという点において非常に有効です。
しかし、RAGのビジネス活用が進むにつれ、単に事実を検索するだけでは不十分なケースが増えています。例えば、製造業の保守現場やシステム運用の現場では、以下のような高度な問いに答える必要があります。
こうした問いは、文書の特定の箇所に答えが書いてあるわけではありません。文書全体に点在する複数の情報を統合し、その因果関係を辿る推論のプロセスが必要です。
従来のチャンクベースの検索(以下、NaiveRAG)では、文書を一定の長さで分割して管理するため、こうした情報間の論理的なつながりや階層構造が分断され、消失しやすいという限界がありました。今回は、この課題を解決する手法として注目される「GraphRAG」の可能性と限界について、故障木解析(FTA)を用いた検証結果を交えて解説します。
※ GraphRAGにはいくつかの手法やライブラリが存在しますが、今回は、Microsoftが公開したライブラリである「graphrag」(以下、ms-graphrag)を使用しました。以下、GraphRAGのインデックス手法や検索手法について、ms-graphragの具体的な挙動をベースに説明します。
GraphRAGとは、情報の最小単位を「チャンク(断片)」ではなく、「要素」と「関係性」として捉え、それらをネットワーク状のデータ構造(ナレッジグラフ)として保持・検索する新しいRAG手法です。
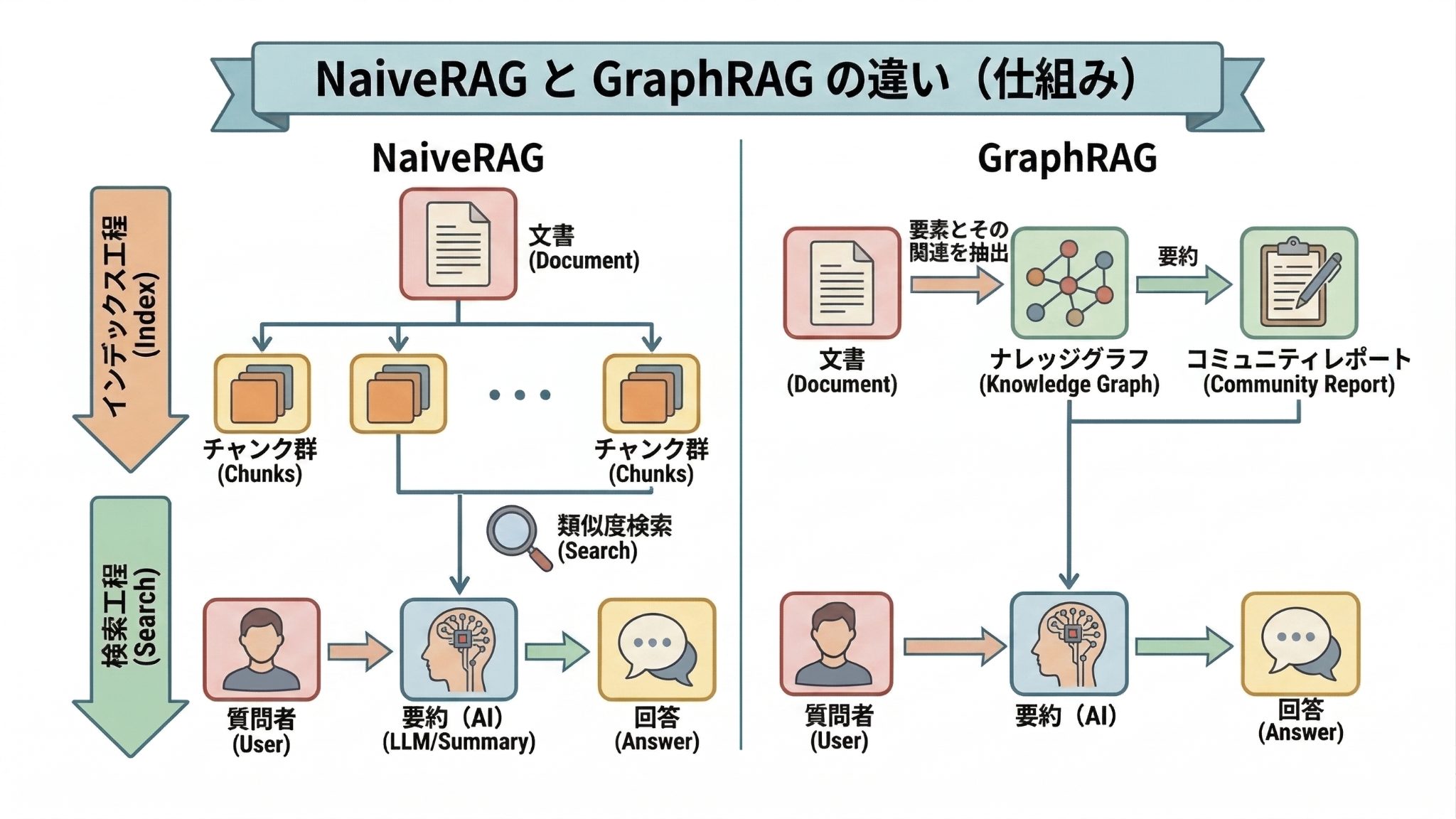
| NaiveRAG | GraphRAG | |
| インデックスの方法 | 文書を一定の長さで区切った「断片(チャンク)」としてインデックス化 | 文書から「要素」とそれらの「関係性」を取り出しグラフ構造としてインデックス化 |
| 検索のアプローチ | 質問文と意味の近い(ベクトル距離の近い)チャンクを取得 | 質問文と意味の近い要素を取得後、加えてグラフ構造に基づき周囲の要素も取得 |
| 得意なタスク | 特定の事実や数値のピンポイントな抽出 | 因果関係の特定、複数情報の統合、全体像の把握 |
GraphRAGがNaiveRAGに対して優位性を持つ点は、大きく分けてふたつあります。
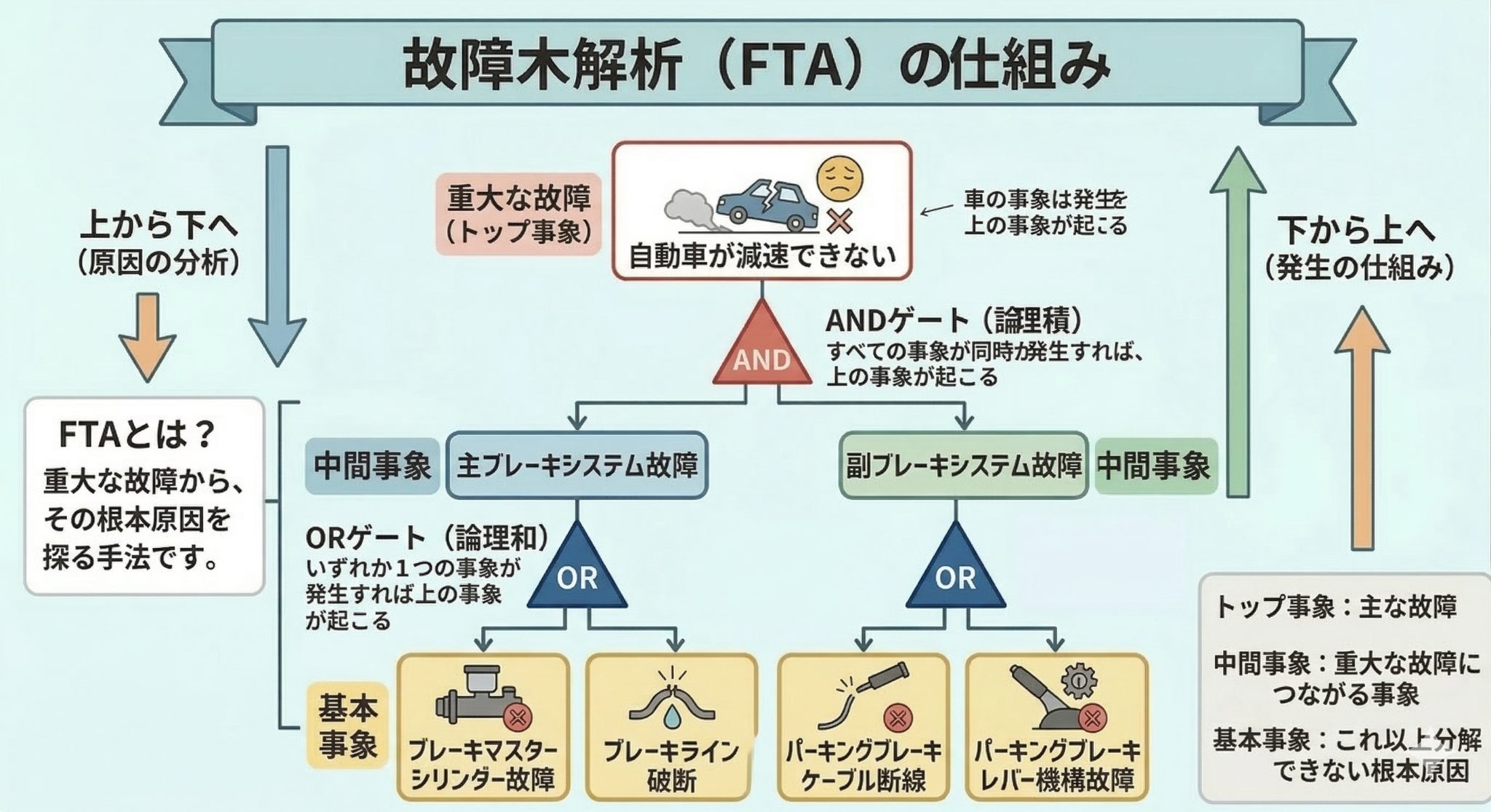
検証の題材として、製造業や航空宇宙、インフラ管理などの安全性が極めて重視される現場で不可欠な「故障木解析(FTA: Fault Tree Analysis)」を採用しました。
FTAは、発生してはならない重大な事故(トップ事象)を起点に、その原因を「なぜ?」と下位に向かって掘り下げていく解析手法です。その構造は名前の通り「樹状(ツリー状)」になっており、最終的には部品の故障や人為的ミスといった最小単位の原因(基本事象)に辿り着きます。
この解析において重要なのが「論理ゲート」という考え方です。
このように、FTAは「何が起きると、何が起きるか」という因果関係を厳密に定義した、いわば「論理の設計図」です。実務の現場では、航空宇宙、自動車、エネルギーなどの高い安全性が求められる産業において、設計段階でのリスク評価や、事故発生後の原因究明に広く活用されています。
具体的には、特定の部品が故障した際にシステムが停止する確率を算出したり、致命的な事故を招く「最短のルート」を特定したりすることで、効率的なメンテナンス計画の策定や安全対策の優先順位付けに役立てられています。
FTAデータには、AIによる検索において非常に難易度の高い特徴がふたつあります。
従来のNaiveRAGでは、文書を細切れにして検索するため、この「ゲートを介した論理の継ぎ目」が分断されやすく、AIが因果関係を見失う原因となります。一方、要素間のつながりを直接保持する GraphRAGであれば、この複雑な論理を維持したまま検索できるのではないか。これが今回の検証の核心です。
今回、「FTAを正しく検索できるか?」を検証するための資料として、FTAのハンドブックとして世界的に認知されている「Fault Tree Analysis Handbook with Aerospace Applications」(以下、NASA FTA Handbook)を選択しました。このハンドブックにはいくつかの故障木解析の事例が掲載されていますが、最も基礎的な「圧力タンクの例(Pressure Tank Example)」を検証データとして選びました。
この事例は、ポンプとモーターによって駆動される圧力タンクシステムを題材としています。システムの主目的はタンク内の圧力を一定範囲に保つことですが、制御が失敗すると「タンクの破裂」という致命的な事故(トップ事象)を招く恐れがあります。
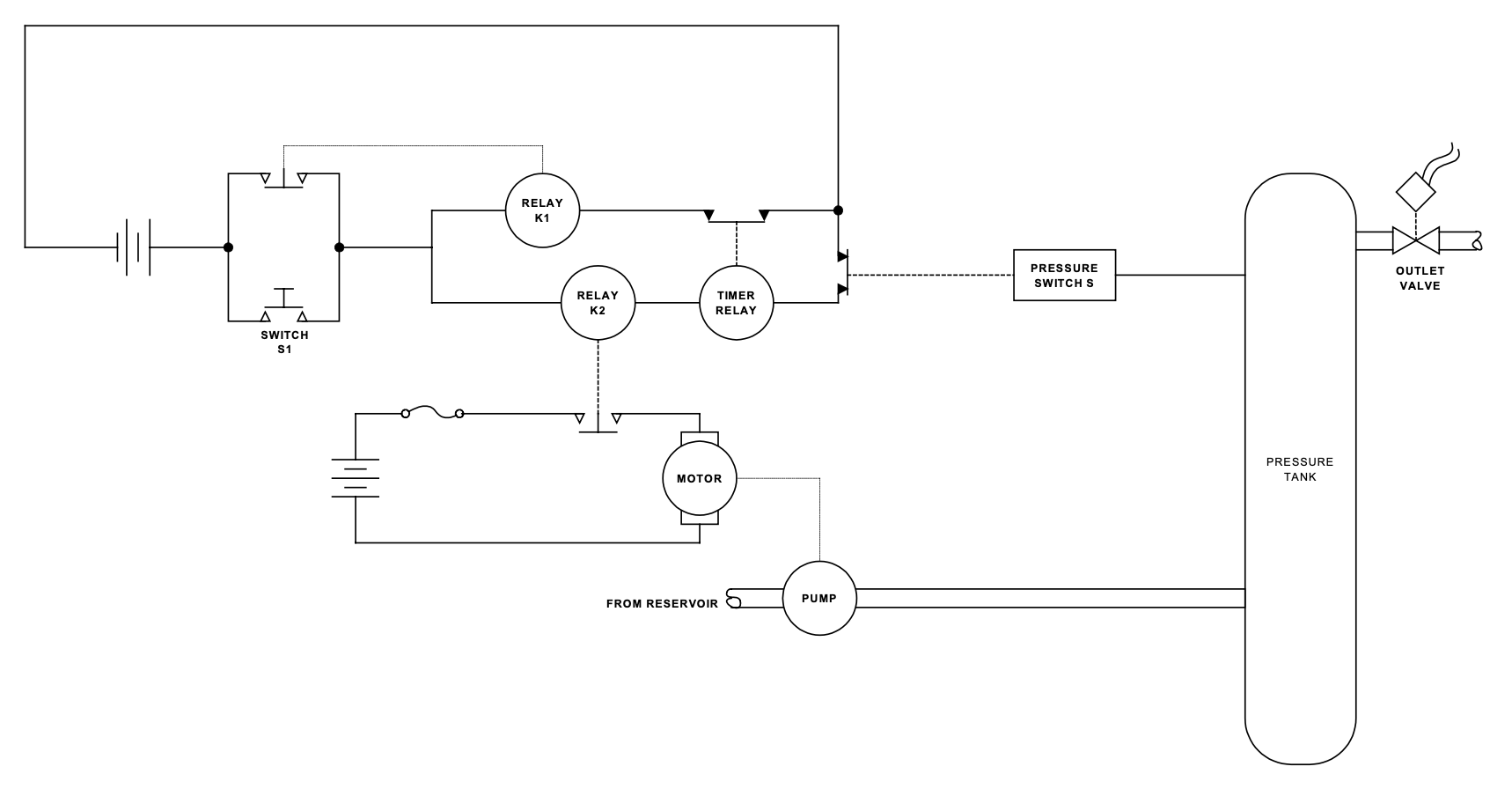
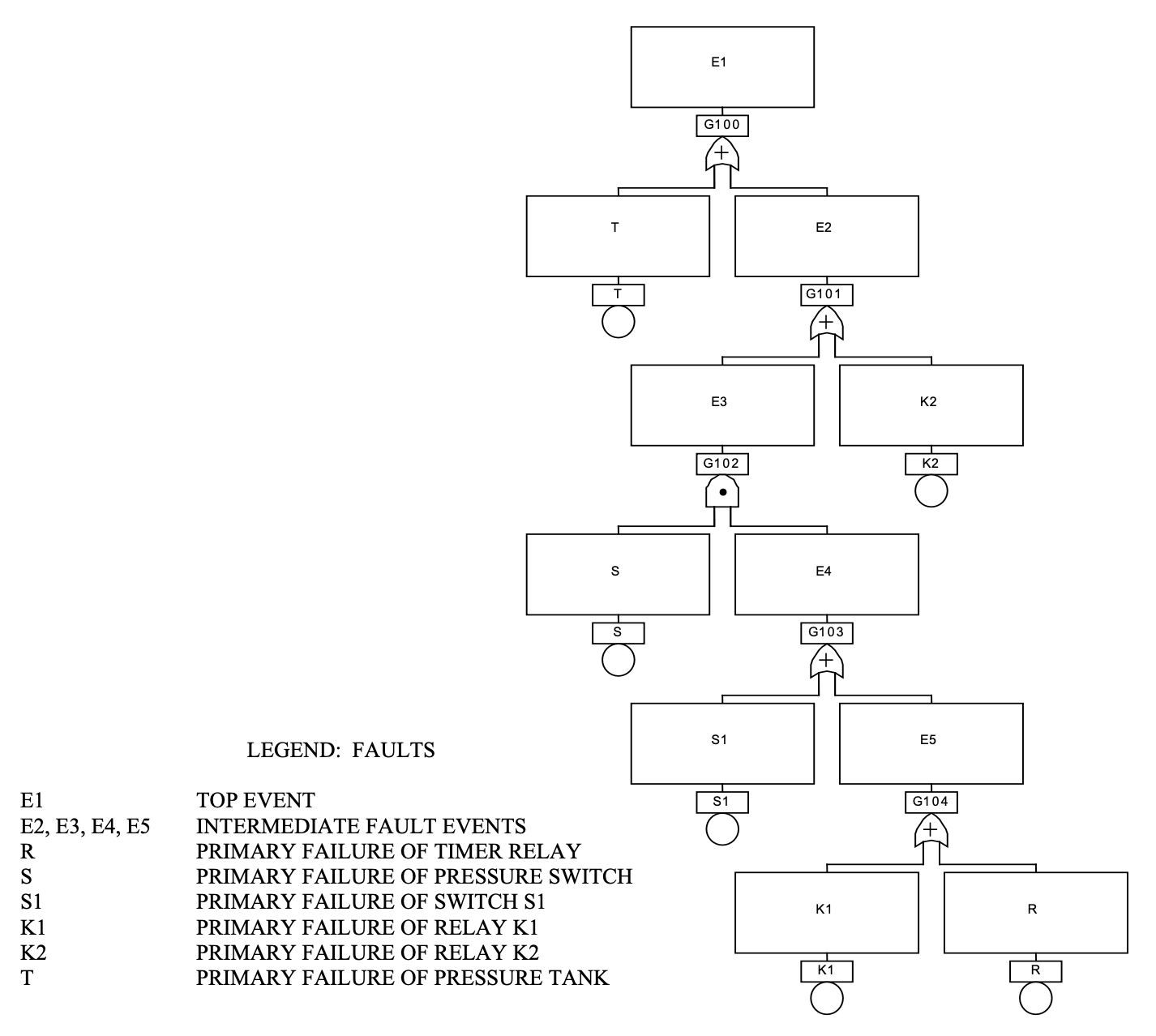
GraphRAGを導入する際、多くの人が「LLMが自動的にグラフを構築してくれる」という点に期待を寄せます。しかし、実運用において最も重要かつ工数がかかるのは、LLMに渡す前のデータ整形です。
特に技術文書の場合、重要な情報の多くが回路図や故障木(Fault Tree)といった「図」の中に存在します。GraphRAGはテキスト間の関係性を抽出するのは得意ですが、PDF上の図をそのまま読み取って、その論理構造を100%正確にナレッジグラフに変換できるわけではありません。
「図として表現された知見を、いかに情報の欠落なくテキスト(構造化データ)に変換し、グラフの種として整備するか」。この準備の質が、最終的な回答精度を左右します。
今回の検証対象である「NASA FTA Handbook」は、複雑な回路図や故障木が多用されています。これらをGraphRAGに取り込むにあたり、以下のステップで精度向上を図りました。
NASA FTA HandbookはPDF形式であり、回路や故障木は図として表現されています。一方で、ms-graphragには図を直接読み取る機能がありません。そこで、Mermaid記法と呼ばれる図をテキストとして表現する記法を用いて変換することで、ms-graphragが認識できる形に整形しました。
コードブロック:圧力タンクシステムの回路図をMermaid記法で表現したもの(一部)
graph TD
subgraph Control_Circuit [Control Circuit]
B1[Battery] --> S_Logic{Start Logic}
%% Self-holding logic
subgraph S_Logic [Switch & Latching]
S1[Push Switch S1]
K1_Latch[/K1 Latching Contact/]
S1 --- K1_Latch
end
S_Logic --> K_Coils{Relay Coils}
subgraph K_Coils [Parallel Load]
K1((Relay K1))
K2((Relay K2))
end
...続けて、ステップ1で作成したMermaid記法をms-graphragの標準インデックス機能に渡しました。本来、ms-graphragの標準機能は、LLMを用いてテキストから要素や関係性を推論・抽出することでグラフを構築するものです。
しかし、このLLMによる抽出を試みたところ、回路や故障木の構成要素やつながりを網羅的に拾いきれない場合があるという課題に直面しました。汎用的な抽出プロンプトだけでは、専門的な論理構造を正確に再現するのは困難であることが分かりました。
そこで今回は、LLMによる自動抽出に頼るのではなく、Mermaid記法のテキストを解析して直接グラフデータへと変換するスクリプトを自作・実行しました。LLMによる自動抽出ではこぼれてしまう複雑な論理構造を、Mermaid経由の機械的な変換によって、正確にナレッジグラフへと再現することに成功しました。
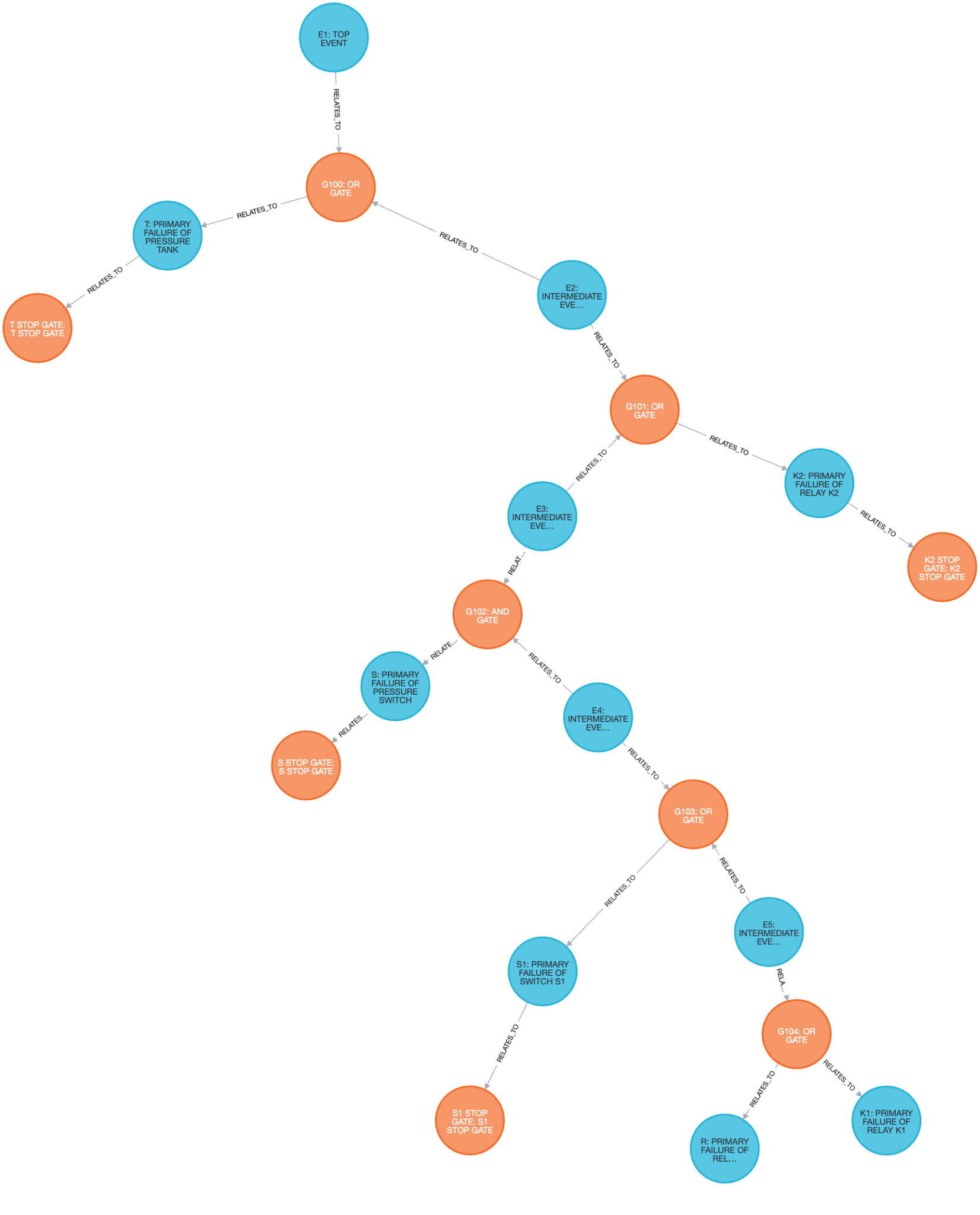
GraphRAGの検索の準備ができたので、GraphRAGの検索・回答精度の検証を、NaiveRAGとの比較を行うことで実施しました。
本セクションは非常にボリュームがあるため、ご自身の関心領域に合わせて読み方を変えていただけますと幸いです。
従来のNaiveRAGが情報を「文書の断片(チャンク)」としてバラバラに管理するのに対し、GraphRAGは情報を「要素」と「関係性」が編み込まれたグラフ構造として保持します。
では、AIがそのグラフ構造を「正しく理解している」とは、具体的にどのような状態を指すのでしょうか。今回の検証では、GraphRAGが持つ推論能力の限界値を測るため、情報の理解度を以下の4段階のレベルに定義しました。レベルが上がるほど、単なる情報の抽出を超えた、高度な「構造の把握能力」が求められます。
1. 個々の要素の理解
最も基本的なレベルです。膨大な情報群の中から、特定の名称、固有名詞、あるいは独立した概念といった情報の最小単位を正しく見つけ出せる状態を指します。これが実現されていれば、「膨大な資料の中に、〇〇という項目が存在するか?」といった質問に答えることができます。
2. 直接的な関係にある要素間の関係性の理解
ある要素と、そのすぐ隣にある要素がどう結びついているか、「1対1の直接的なつながり」を把握できている状態です。これが実現されていれば、「要素Aは要素Bに依存している」「要素Cは要素Dの構成要素である」といった、隣接する情報同士の関係性に関する質問に答えることができます。
3. 間接的な関係にある要素間の関係性の理解
直接つながっていないふたつの要素が、他の要素を介してどのように影響し合っているか、複数ステップのつながりを辿れる状態です。これが実現されていれば、「要素Aの変化が、Bを経由して、離れた場所にある要素Zにどう伝播するか?」という、文書内の離れた位置に書かれた情報を結びつけて質問に答えることができます。
4. 要素間の全体構造の理解
個別のつながりを統合し、情報のグラフ構造全体を俯瞰できている状態です。これが実現されていれば、「末端の各要素の変化が、複数の経路を経て最終的に最上位の要素にどう影響するか」という長距離のルートを辿ったり、複雑に絡み合った全体図を要約したりすることができます。
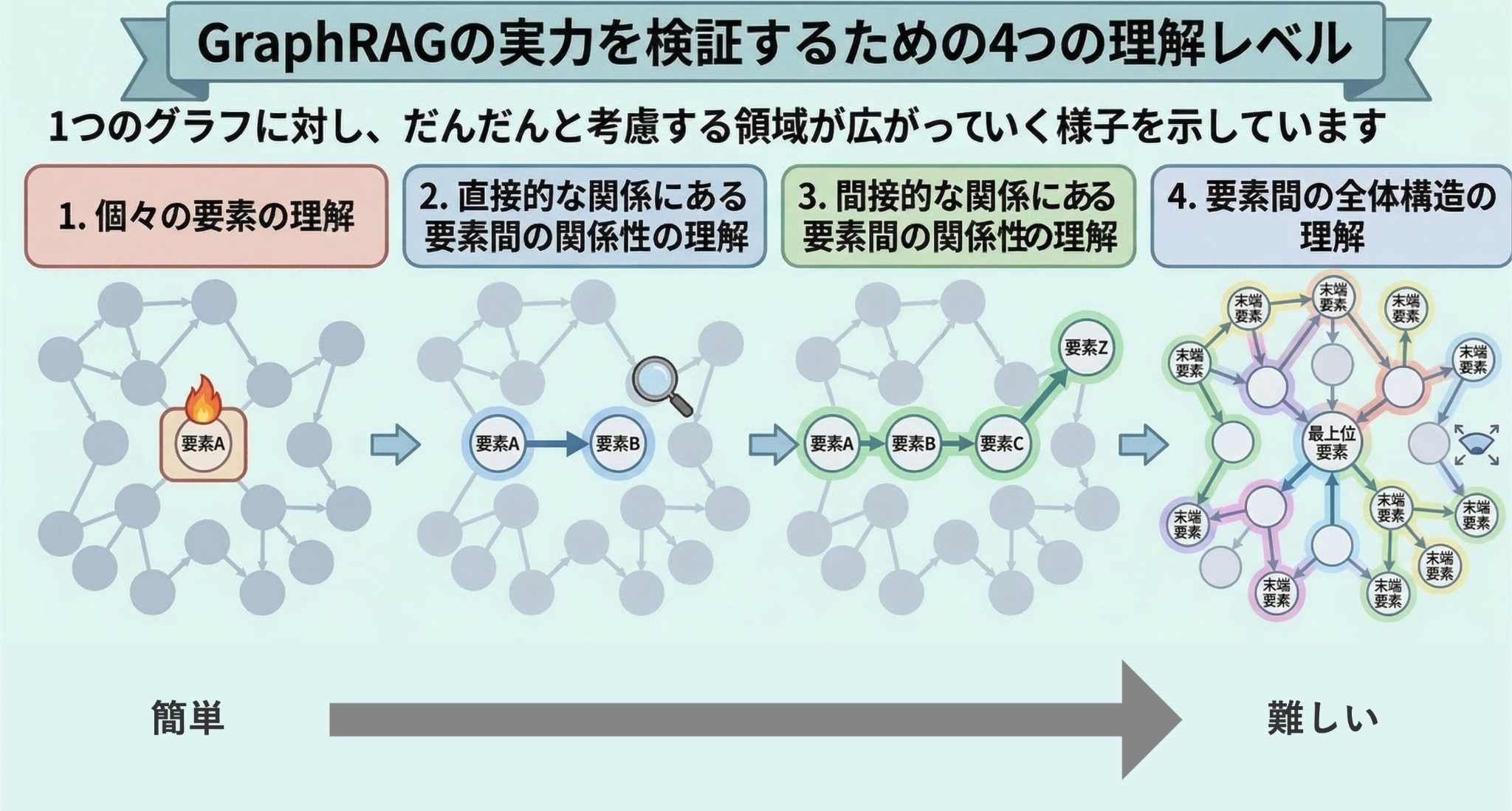
上記4つのレベルを踏まえ、精度検証のためのFTAに関する質問を用意しました。
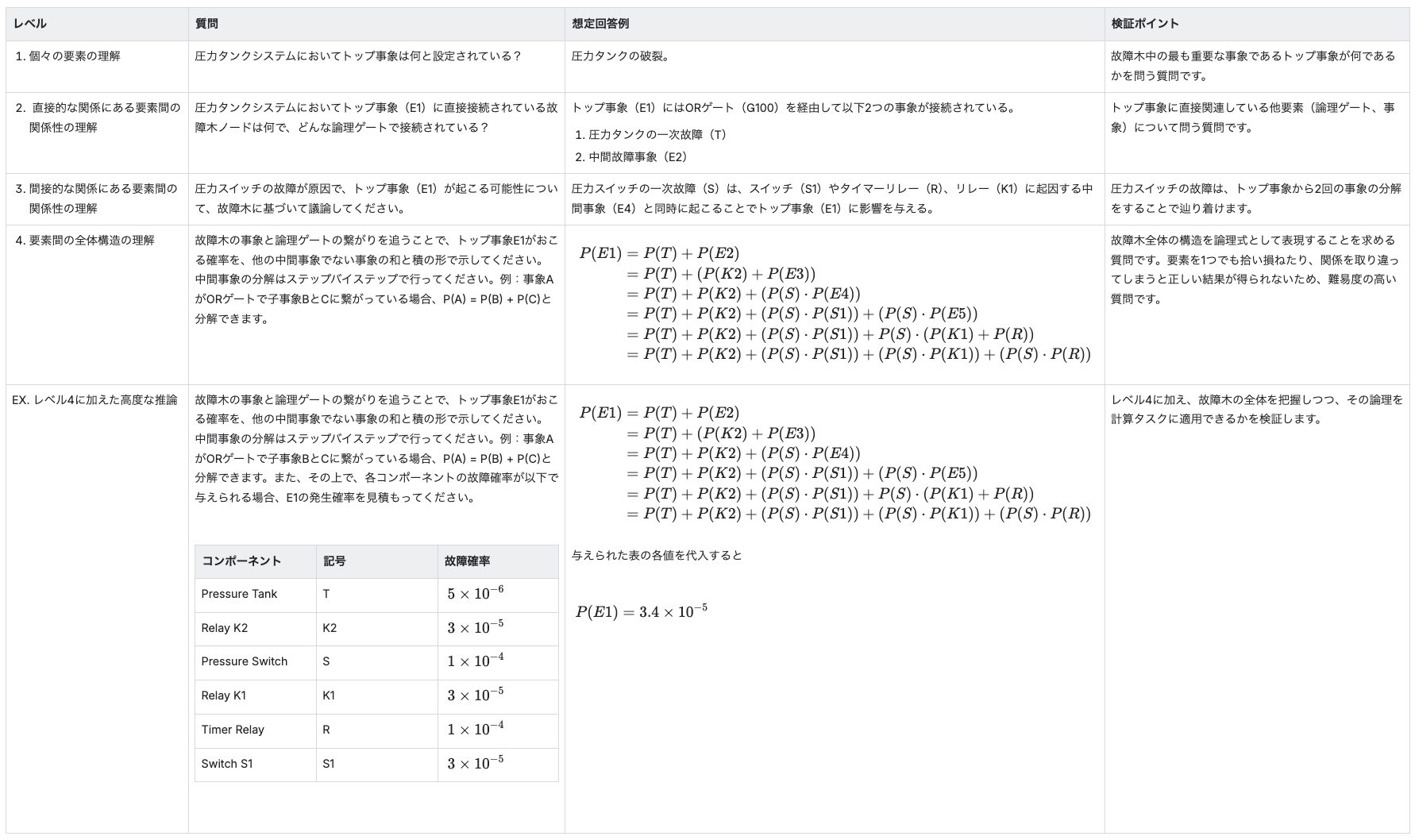
なお、NaiveRAGはDifyを用いて構築しました。PDFそのままではなくMermaid記法で書かれた回路図・故障木を文書として与えることで、GraphRAGとなるべく公平な条件で検証ができるようにしました。
【結果】
「トップ事象の名称は何か?」という問いに対し、両者とも正確に回答しました。
個々の要素の理解は、NaiveRAGが得意とする「ベクトル検索(意味の近さによる検索)」が問題なく発揮される領域です。文書内のどこかに「トップ事象はE1である」と明記されていれば、それを拾い上げるのは容易であるため、問題なく回答できました。
GraphRAGにおいても、トップ事象が1つの要素としてインデックスされているため、迷わず回答できているようです。
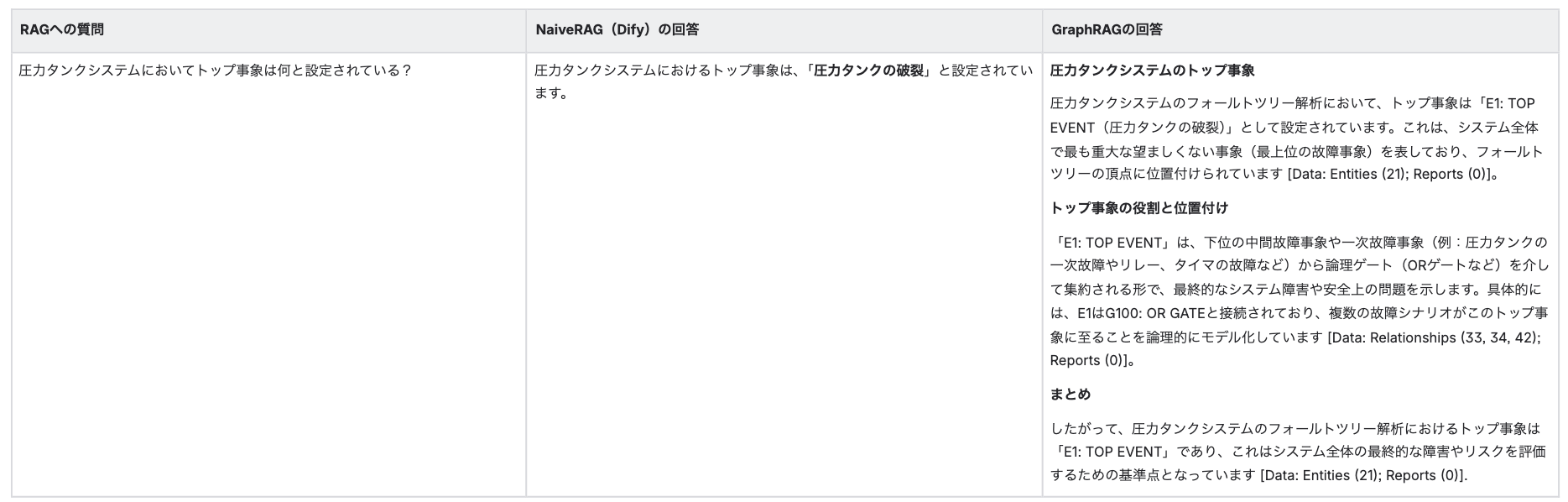
【結果】
レベル1と同様、NaiveRAGもGraphRAGも正確な回答が得られました。
トップ事象に直接する情報はドキュメント内でも近くに書かれているため、NaiveRAGにおいても同一のチャンクとして検索・回答できているようです。
GraphRAGにおいてもトップ事象に直接関連する他要素を拾い上げ、回答できています。

【結果】
ここでNaiveRAGが限界を迎えました。NaiveRAGは、質問内容である「スイッチの故障」と関連性の高い断片を拾いますが、その中間にある「リレーの動作」や「論理ゲート」が書かれた別の情報を、芋づる式に引き出すことができていません。
実用上で故障木解析(FTA)を行うなら、この程度の論理を追う質問は最低レベルの要求と言えます。こうした構造的な推論ができないNaiveRAGでは、実務における実用性が乏しいことが明らかになりました。
一方GraphRAGでは、要素のつながりを追うことでユーザの質問に問題なく答えられています。
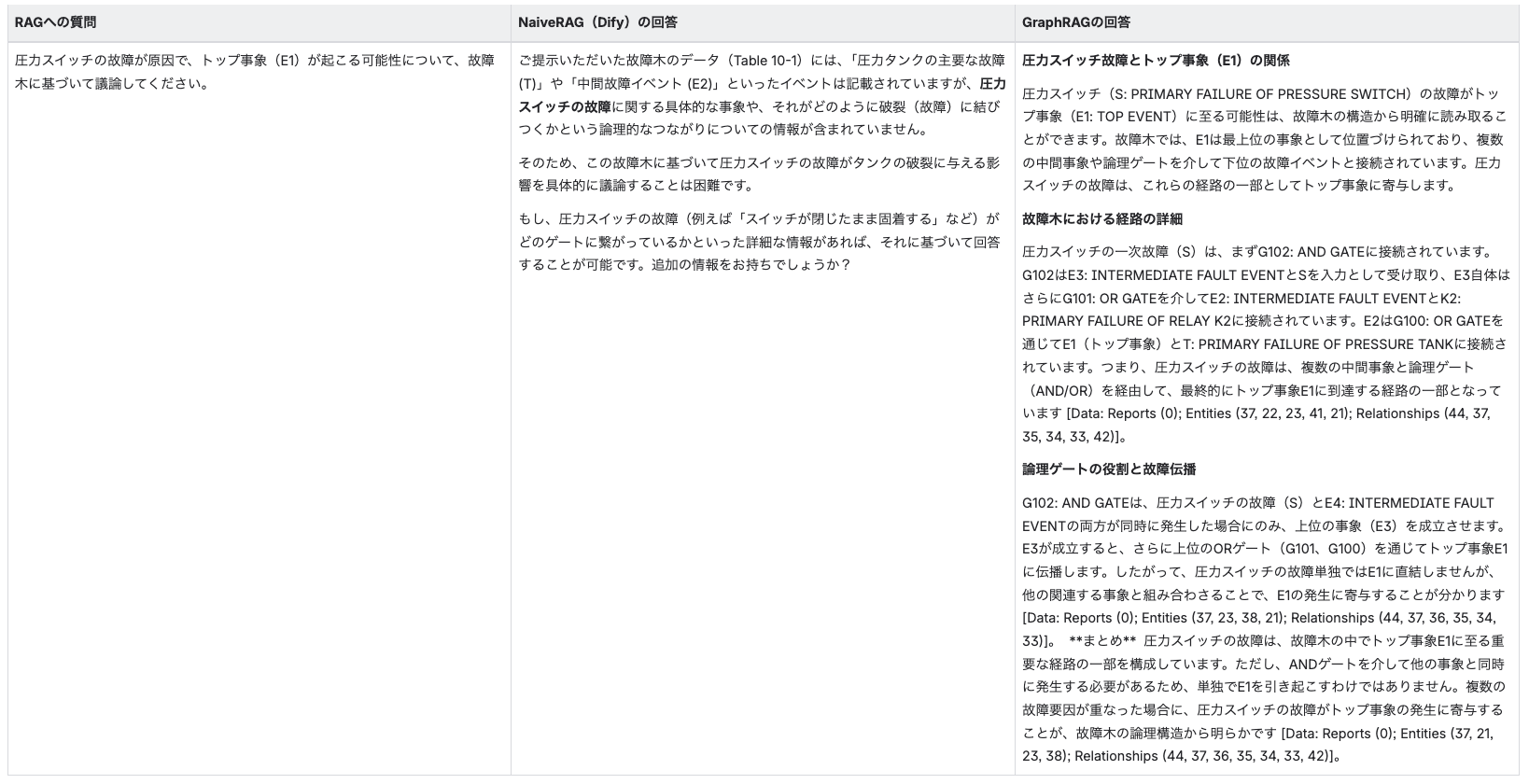
ここで、GraphRAGがグラフ構造をどのように検索しているのかをステップバイステップで追ってみます。(検索には、ms-graphragのLocal Searchを使用しています)
GraphRAGでは、NaiveRAGが関連するチャンクをベクトル距離の近さで検索するように、あらかじめベクトルが計算されている要素から質問に近い要素を検索します。
| 順位 | 要素 |
| 1 | S: PRIMARY FAILURE OF PRESSURE SWITCH |
| 2 | S1: PRIMARY FAILURE OF SWITCH S1 |
| 3 | T: PRIMARY FAILURE OF PRESSURE TANK |
| 4 | E2: INTERMEDIATE FAULT EVENT |
| 5 | E3: INTERMEDIATE FAULT EVENT |
| 6 | E5: INTERMEDIATE FAULT EVENT |
| 7 | K1: PRIMARY FAILURE OF RELAY K1 |
| 8 | R: PRIMARY FAILURE OF TIMER RELAY |
| 9 | E4: INTERMEDIATE FAULT EVENT |
| 10 | K2: PRIMARY FAILURE OF RELAY K2 |
| 11 | E1: TOP EVENT |
| 12 | S1 STOP GATE: S1 STOP GATE |
「圧力スイッチ」「トップ事象(E1)」を含むクエリに対して、S(圧力スイッチ) が最も類似度が高く、E1、E2、E3 など故障木の主要ノードも上位に来ています。
Step 1 で得た要素が属するコミュニティを特定し、そのコミュニティの要約レポートを取得します。インデックス作成時に LLM が生成した「コミュニティの概要」です。
今回の例では、2件のコミュニティレポートが参照されました。
1件目のコミュニティレポートは「Pressure Tank Fault Tree Analysis: Key Events and Gates」というタイトルです。トップ事象(E1)や圧力タンクの一次故障(T)など故障木の上流〜中流の構造を説明しています。
2件目のコミュニティレポートは「Pressure Tank Fault Tree: Relay and Timer Failure Network」というタイトルです。リレー・タイマー故障に焦点を当て、故障木の下流構造を説明しています。
これらのレポートを参照することで、故障木の全体像と局所的な故障経路をコンテキストとしてより正確な回答を実現しています。
Step 1で取得した要素と直接繋がってる要素を取得することで、グラフの局所的な構造を取得します。
| ID | どこから | どこへ |
| 33 | E1: TOP EVENT | G100: OR GATE |
| 34 | E2: INTERMEDIATE FAULT EVENT | G100: OR GATE |
| 35 | E2: INTERMEDIATE FAULT EVENT | G101: OR GATE |
| … | … | … |
グラフの元になったテキストを取得します。ここではMermaid記法で記述された故障木図がテキストとして参照されています。
上記4ステップで集めた情報をまとめてLLMに渡し、回答を生成します。このタイミングで、参照したレポートや要素、関係などを引用として付与します。
ms-graphragではこのようなステップでグラフ構造を活かした検索と回答生成を行っています。
【結果】
「全体の論理構造を式にせよ」という、情報の網羅性と構造把握を求める難易度の高い質問でしたが、GraphRAGでは最終的な式を正確に答えることができています。グラフ構造を活かした検索や、コミュニティレポートによるコンテキストの補完が役立っているようです。

【結果】
NaiveRAGの回答は、論理式を組み立てる段階から間違えてしまっているため、最終的な数値も誤りです。
GraphRAGでは、グラフからの式抽出までは正しかったものの、LLMによる多段階計算(Chain of Thought)において数値の取り扱いや計算におけるミスが見られました。


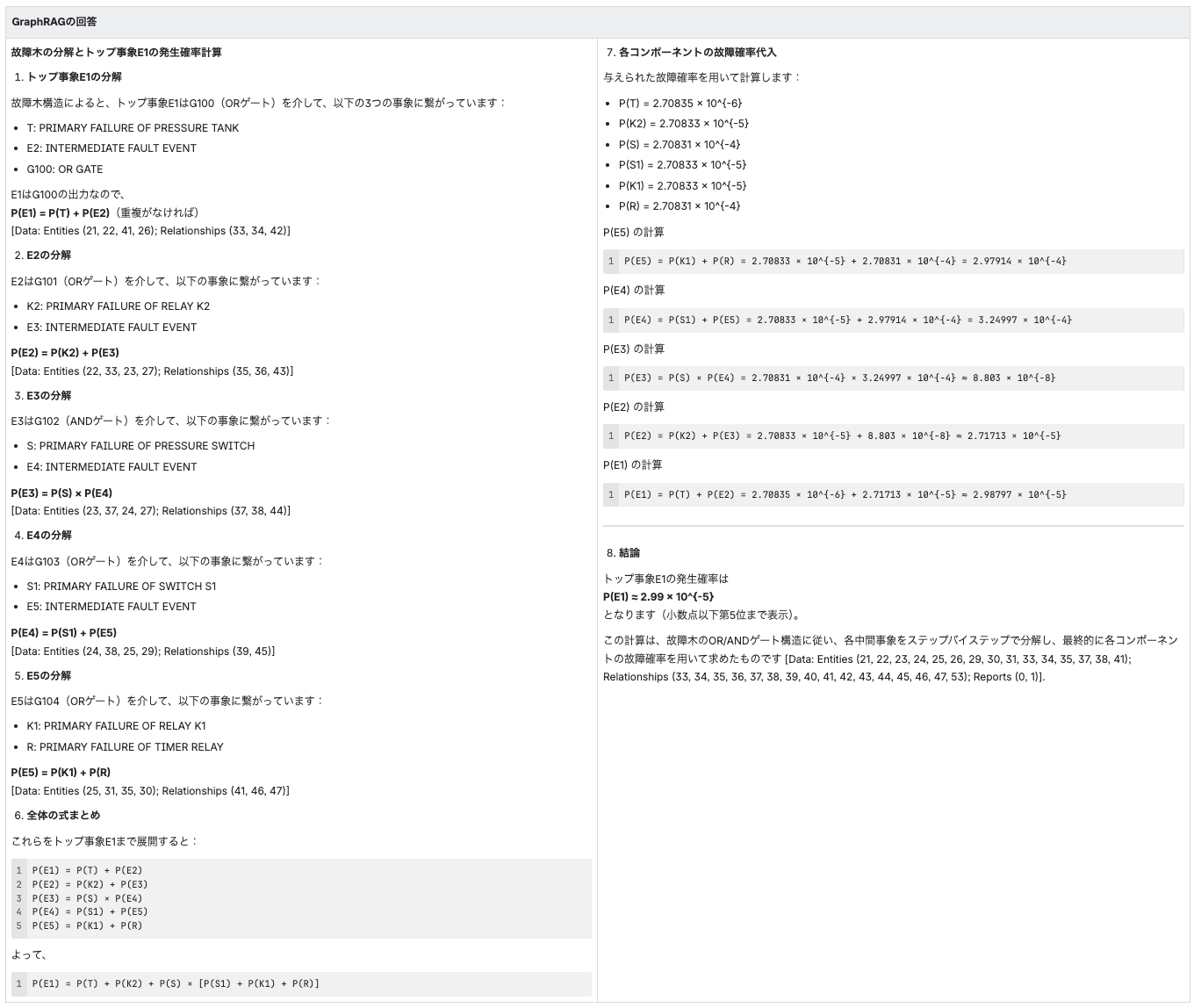
今回の検証結果をまとめると、下記の表のようになりました。
| レベル | 検証ポイント | NaiveRAG | GraphRAG |
| 1 | 個々の要素の理解 | ○ | ○ |
| 2 | 直接的な関係にある要素間の関係性の理解 | ○ | ○ |
| 3 | 間接的な関係にある要素間の関係性の理解 | × | ○ |
| 4 | 要素間の全体構造の理解 | × | ○ |
| EX | 要素間の全体構造を理解した上での高度な推論 | × | × |
今回の検証により、GraphRAGの真価は情報の「構造化」にあることが明確になりました。基本的な事実確認や直接的な関係把握(レベル1・2)では2つの手法に大きな差はありませんでしたが、情報の継ぎ目が重要となる間接的な推論や全体構造の把握(レベル3・4)において、GraphRAGはNaiveRAGを圧倒する結果を残しました。
情報を断片的なチャンクで管理するNaiveRAGは、離れた情報を繋ぎ合わせる際に論理が分断されやすいのに対し、GraphRAGは「ナレッジグラフ」としてつながりを保持するため、複雑な因果関係も正確に辿ることが可能です。GraphRAGの、文書の内容を「点(事実)の集合」ではなく「線(つながり)」や「面(全体構造)」で情報を捉えるという特長は、高度な専門知識の解析において極めて有効な武器になると言えるでしょう。
高度な計算を伴う推論(レベルEX)には課題も残りますが、こちらはGraphRAGによって抽出された「正確な論理構造」をベースに、実際の計算処理を外部のプログラムへ委ねる「AIエージェント」のようなな仕組みを構築することで、実務上の課題を克服できる可能性を秘めています。
ここまではGraphRAGの検索精度の高さに焦点を当ててきましたが、実際にビジネス現場へ活用する際は、単なる「精度」以外の多角的な指標を考慮する必要があります。実務導入において検討すべき最大のポイントは、「運用コスト」と「検索精度」のトレードオフです。
具体的に、従来のNaiveRAGと今回のGraphRAGをビジネス視点で比較すると以下のようになります。
表:NaiveRAGとGraphRAGのビジネス活用における比較
| 評価項目 | NaiveRAG | GraphRAG |
| インデックス作成にかかる料金 | 低い(埋め込みモデル中心) | 非常に高い(埋め込みモデルに加え、LLMによる抽出・要約が必要) |
| 最低限必要なデータの前処理 | 少ない(単純なチャンク分割から始められる) | 多い(PDFや図表をテキスト形式にする必要がある。今回の場合のように機械的な変換スクリプトの作成が必要な場合も。) |
| 更新・メンテナンス性 | 高い(差分追加・修正が容易) | 低い(全体構造の再構築が必要) |
| 回答生成のスピード | 高速 | やや低速(検索ステップが多いため) |
| 得意なタスク | 特定の事実や数値の検索 | 間接的な関係性の把握・全体構造の要約 |
「製品マニュアルの特定箇所を確認したい」「社内規定の具体的な文言を知りたい」といった、答えが文書の特定の場所に明記されている場合は、NaiveRAGで十分です。 また、日々新しい文書が追加されたり、頻繁に内容が修正されたりする動的なナレッジベースの場合、該当するチャンクを更新・追加するだけで済むNaiveRAGの柔軟性が大きなメリットとなります。
今回検証したFTA(故障木解析)のように、複数の事象が複雑に絡み合い、かつその「つながり」自体に価値がある領域ではGraphRAGが圧倒的に優位です。その反面、新情報が加わるたびにグラフ全体の整合性を取る必要があるため、運用にはコツがいります。よって、更新頻度が低く、内容の固まった「技術標準」や「トラブル事例集」などの解析で、その真価を最も享受できるでしょう。考えられる有効な活用シーンは、例えば以下の通りです。
GraphRAGは非常に強力ですが、インデックス作成や計算リソースの面でコストが高い”重厚”な技術でもあります。そのため、ビジネスにおける現実的な解は、全ての情報を一律にグラフ化するのではなく、情報の網羅性や、情報同士の関連性が重要となる特定のコア領域に絞って導入することです。例えば、日常的なFAQ検索にはNaiveRAGを用い、専門性の高い分析業務にのみGraphRAGを適用するといった目的別の使い分けや、抽出された論理構造を元に次のアクション(推論やツール利用)を設計するような適材適所のシステム構成こそが、高い運用コストに見合う成果を最大化する鍵となるでしょう。
本記事では、GraphRAGとNaiveRAGをFTA(故障木解析)の故障木解析(FTA)を題材とした精度検証を通じて、GraphRAGの真価が「要素と関係の構造化」と「関係性の追跡」にあることを確認しました。個々の事実抽出では差が小さい一方で、間接的推論や全体構造の把握ではGraphRAGが優位でした。実務適用にあたっては、精度だけでなく、インデックス構築・運用コスト、更新頻度、レスポンス速度といったビジネス上のトレードオフを踏まえ導入することが重要です。
次回は、昨今話題の「AIエージェント」をRAGに応用し、自律的な推論と反復を繰り返すことができるような「Agentic RAG」について解説していく予定です。
あなたにオススメの記事

2023.12.01
生成AI(ジェネレーティブAI)とは?ChatGPTとの違いや仕組み・種類・活用事例

2023.09.21
DX(デジタルトランスフォーメーション)とは?今さら聞けない意味・定義を分かりやすく解説【2024年最新】

2023.11.24
【現役社員が解説】データサイエンティストとは?仕事内容やAI・DX時代に必要なスキル

2023.09.08
DX事例26選:6つの業界別に紹介~有名企業はどんなDXをやっている?~【2024年最新版】

2023.08.23
LLM(大規模言語モデル)とは?生成AIとの違いや活用事例・課題

2024.03.22
生成AIの評価指標・ベンチマークとそれらに関連する問題点や限界を解説
















