



メルマガ登録
-
テーマから探す
-
技術から探す
-
業界・事例から探す
-
関連トレンドから探す
テーマから探す
技術から探す
業界・事例から探す
関連トレンドから探す

「Microsoft Fabric」の技術検証を基に、Microsoft Fabricの魅力や各種ポイントを解説していきます。
今回は Microsoft Fabric の機能である Azure SQL Database のミラーリングをご紹介します。
Microsoft Fabric のミラーリングは、さまざまな Azure データベースや外部データソースから Fabric の OneLake に継続的に直接レプリケートできる機能です。レプリケートはニアリアルタイムで実行されるため、常に最新データを使って分析・可視化できる点が魅力です。ETL を作成せずに最新データが取得できることで、データ活用のハードルも低くなるのではないでしょうか。
以前の記事“Microsoft Fabric への移行:Azure SQL Database から レイクハウスへ”(以下、以前の記事)と合わせて検証した内容です。そのため、以前の記事と手順が重複する部分があります。
ミラーリングの手順については公式ドキュメント「チュートリアル: Azure SQL Database から Microsoft Fabric ミラー化データベースを構成する」にある手順の通りとなりますが、ポイントとなる点や検証で躓いた点も含めご紹介します。
Azure SQL Database のミラーリングを実施する前に、前提条件を紹介します。
ミラーリング元となる Azure SQL Database にいくつかの制約があることにご注意ください。
参考:前提条件|チュートリアル: Azure SQL Database から Microsoft Fabric ミラー化データベースを構成する
<2025年3月現在>

特に、ミラーリング元となる Azure SQL Database が仮想ネットワーク、または、プライベートネットワーク内にある場合、ミラーリングの設定を行うことができない点に注意が必要です。現状、ミラーリングにはパブリックネットワークアクセスが必須となります。
次に、ミラーリング元となる Azure SQL Database の購入モデルにも注意が必要です。
今回の検証でも費用節約のため、最初はいつものように DTU 購入モデルの Basic サービスレベルで実施しようとしたところ下図のようなエラーとなり、ミラーリングが実施できませんでした。
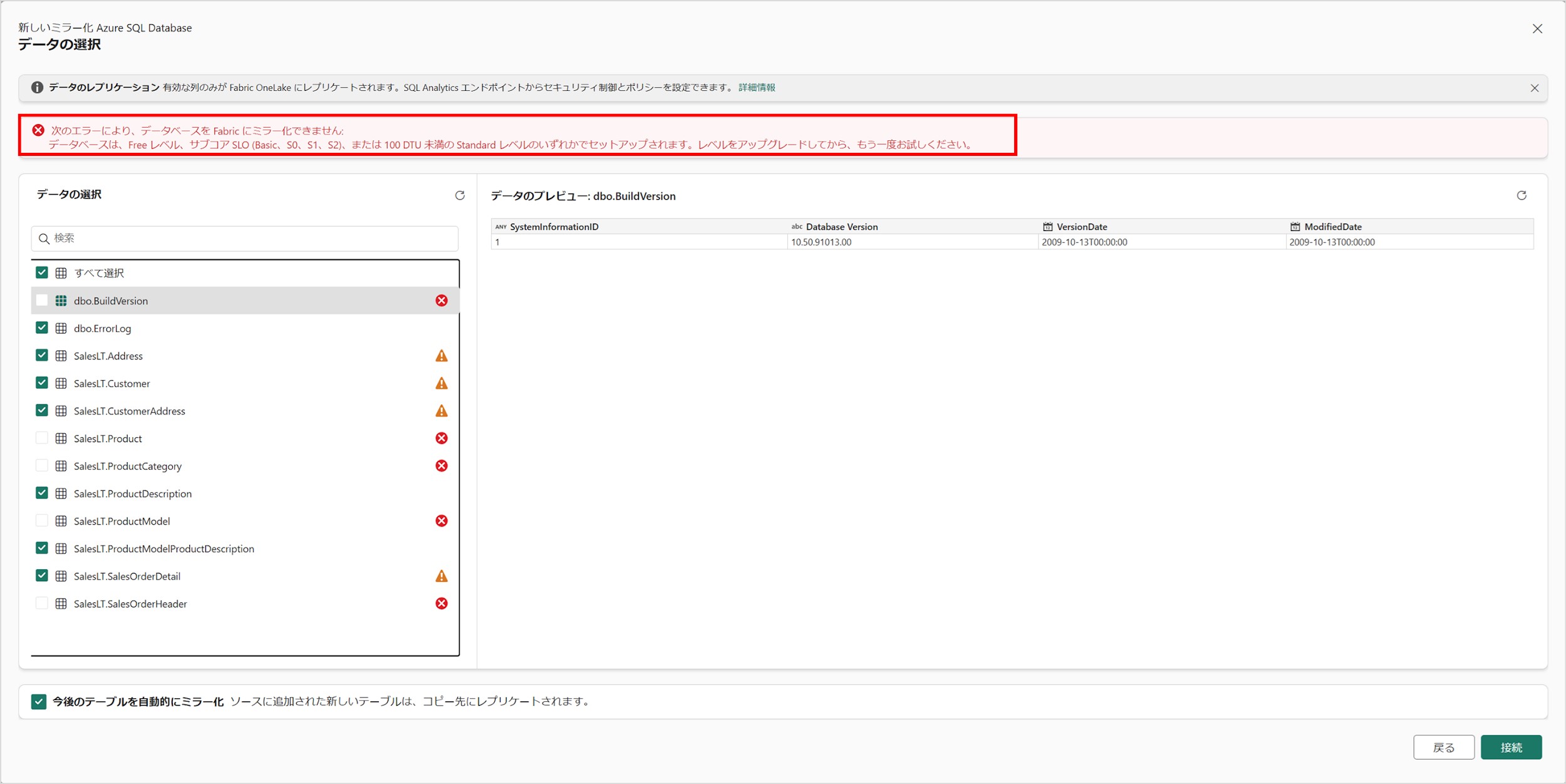
公式ドキュメントをよく読んでみると、DTU 購入モデルではサポートされていないサービスレベルがあるようです。
参考:階層と購入モデルのサポート|Azure SQL Database のミラーリング
<2025年3月現在>

そのため、Standard S3: 100 DTU にサービスレベルを上げて検証を実施しました。
やはり公式ドキュメントはよく読む必要がありますね。
また、現状では Azure SQL Database の実テーブルのみがレプリケートの対象となります。
ビュー、一時テーブル、外部テーブルはレプリケートされないのでご注意ください。
参考:Microsoft Fabric Azure SQL Database のミラーリングに関してよくあるご質問
Azure SQL Database と Microsoft Fabric とのミラーリング設定手順について、Azure 側と Fabric 側に分けて順を追って解説します。
まずは Azure 側の設定を行います。Azure 側の設定内容は大きくふたつあります。
いずれも以前の記事と重複している部分があります。
なお、今回、検証した際の Azure 権限は「共同作成者」権限で実施しています。
レプリケート元の Azure SQL Database に関する設定内容は4つあります。
レプリケート元の Azure SQL Database を準備します。既にレプリケート可能な Azure SQL Database がある場合は、次の「ネットワーク設定」に進んでください。
新規に作成する場合は以前の記事を参照してください。
今回の検証では、DTU 購入モデル(Standard S3: 100 DTU)、かつ、新規にサンプルデータベースを持った Azure SQL Database を作成しています。
Azure SQL Database のサーバー側ネットワーク設定を確認します。
以前の記事と同様、Azure SQL Database が動いているサーバー(SQL Server)の「セキュリティ」→「ネットワーク」より「Azure サービスおよびリソースにこのサーバーへのアクセスを許可する」にチェックを入れる必要があります。
詳細は以前の記事を参照してください。
Fabric OneLake にデータを公開するため、Azure SQL Database のサーバー側にあるシステム割り当てマネージド ID (SAMI) を有効にします。
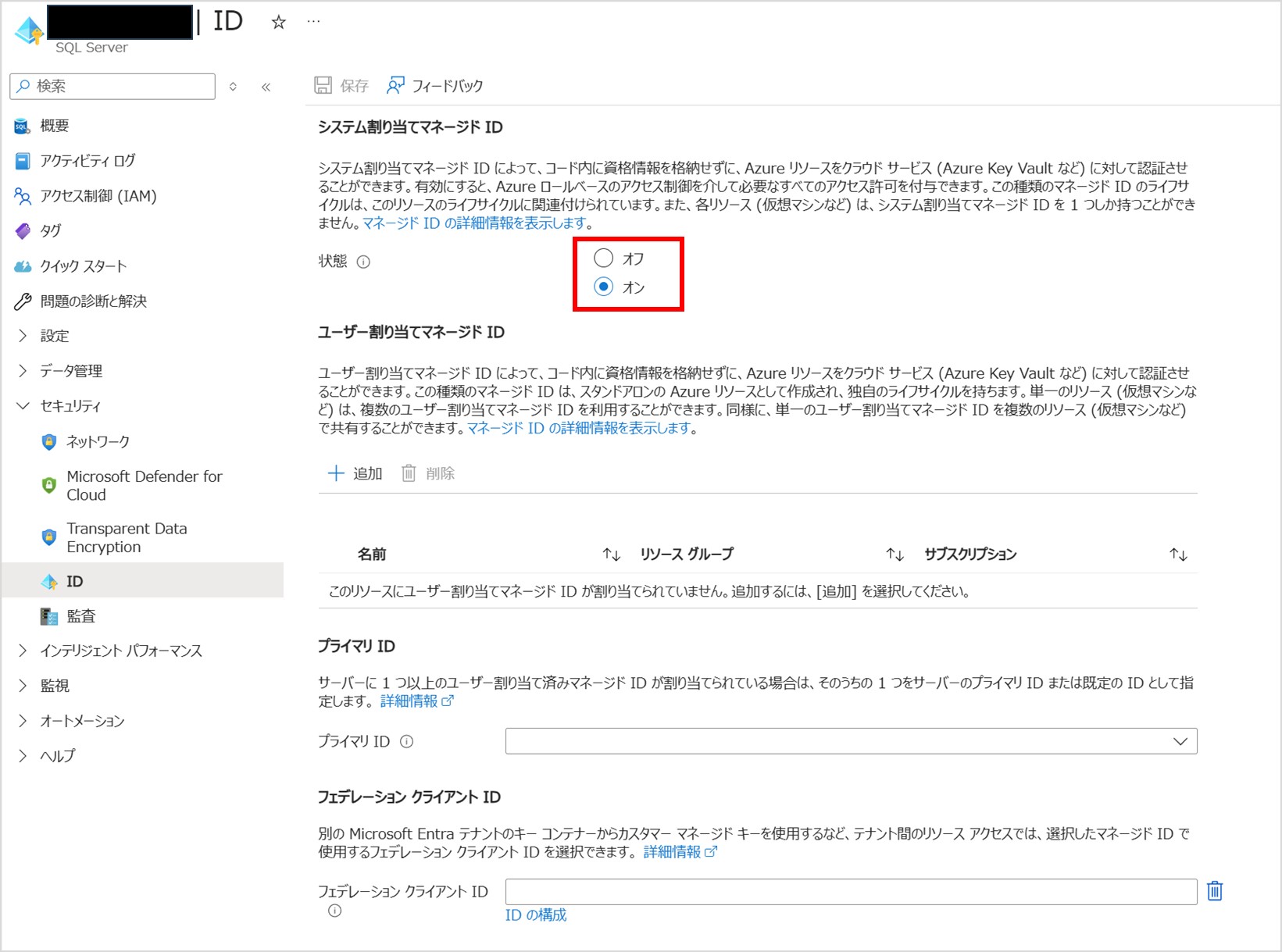
ミラーリングを実施する場合、システム割り当てマネージド ID (SAMI)がプライマリ ID になっていることが必要となります。
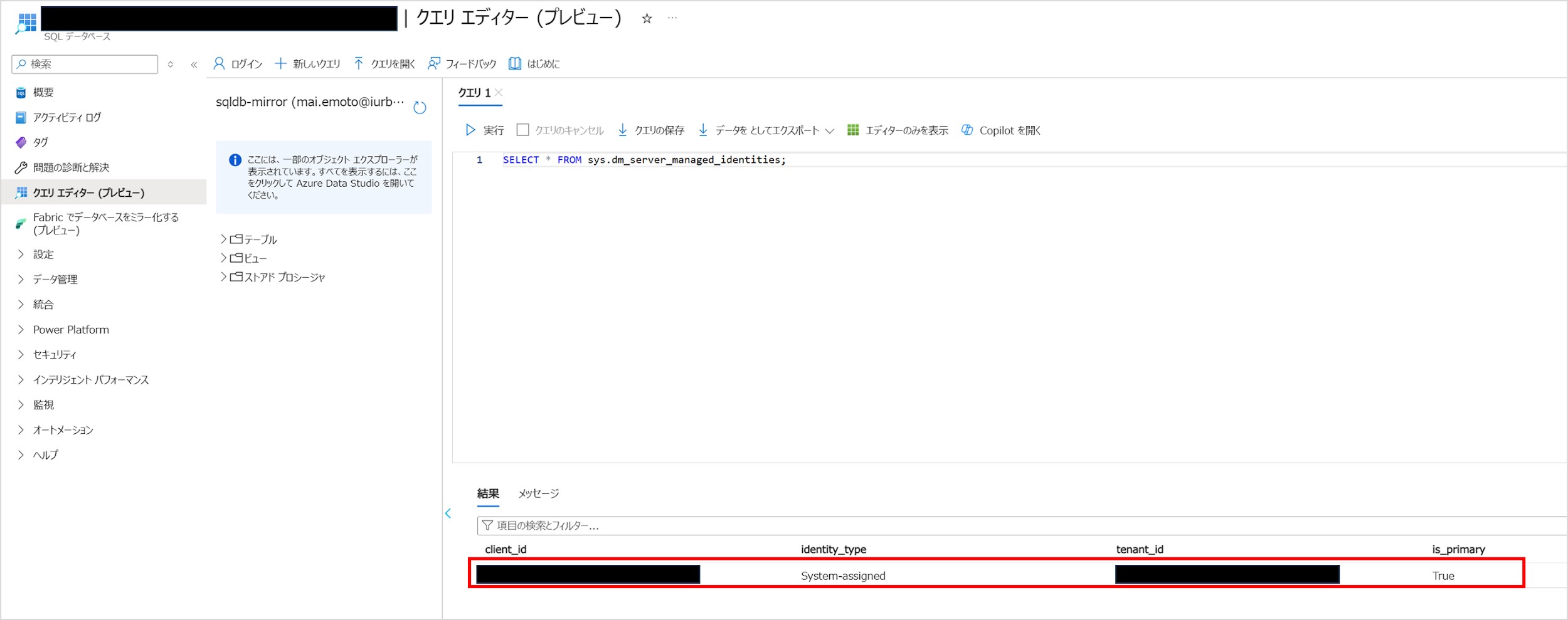
システム割り当てマネージド ID (SAMI)がプライマリ ID になっているかどうかは、Azure SQL Database に以下の SQL を実行することで確認できます。
SELECT * FROM sys.dm_server_managed_identities;「identity_type」が「System-assigned」かつ「is_primary」が「True」になっていたら OK です。
「Azure SQL Database の準備」で Azure SQL Database を新規に作成した場合は下図のような結果になっていると思います。
Microsoft Fabric 用にデータベースユーザーを作成します。
Microsoft Fabric が Azure SQL Database にアクセスする際に使用するユーザーの作成については以下を参照してください。
参考:ログイン ユーザーとマップされたデータベース ユーザーの使用|チュートリアル: Azure SQL Database から Microsoft Fabric ミラー化データベースを構成する
Azure SQL Database のユーザー作成と同様、サーバーログインを作成した後、サーバーログインに紐づいたデータベースユーザーを作成します。
SQL Server Management Studio(以降、SSMS と表記)よりレプリケート元の Azure SQL Database に接続し、master データベースでサーバーログインを作成します。
サーバーログインは SQL 認証ログインと Microsoft Entra ID 認証ログインのいずれかが作成できます。今回の検証では「fabric_login」という名前の SQL 認証ログインを作成しました。
CREATE LOGIN fabric_login WITH PASSWORD = '<strong password>';
ALTER SERVER ROLE [##MS_ServerStateReader##] ADD MEMBER fabric_login;※<strong password> の部分を変更してください。
次に、ミラーリングを行いたいデータベースでデータベースユーザーを作成します。
今回の検証では、前述した「fabric_login」という名前の SQL 認証ログインと紐づいた「fabric_user」という名前のデータベースユーザーを作成しました。
CREATE USER fabric_user FOR LOGIN fabric_login;
GRANT CONTROL TO fabric_user;次に Azure 内に Fabric 容量を作成します。
こちらについても詳細は以前の記事を参照してください。
Azure 側の設定が完了したら、Fabric 側の設定を行います。Fabric 側の設定内容は大きく3つあります。
なお、今回、検証した際の Fabric 権限は「Fabric 管理者」権限で実施しています。
検証内でワークスペースを新規で作成したため、自動的に「ワークスペース管理者」の権限も所有した状態で実施しています。
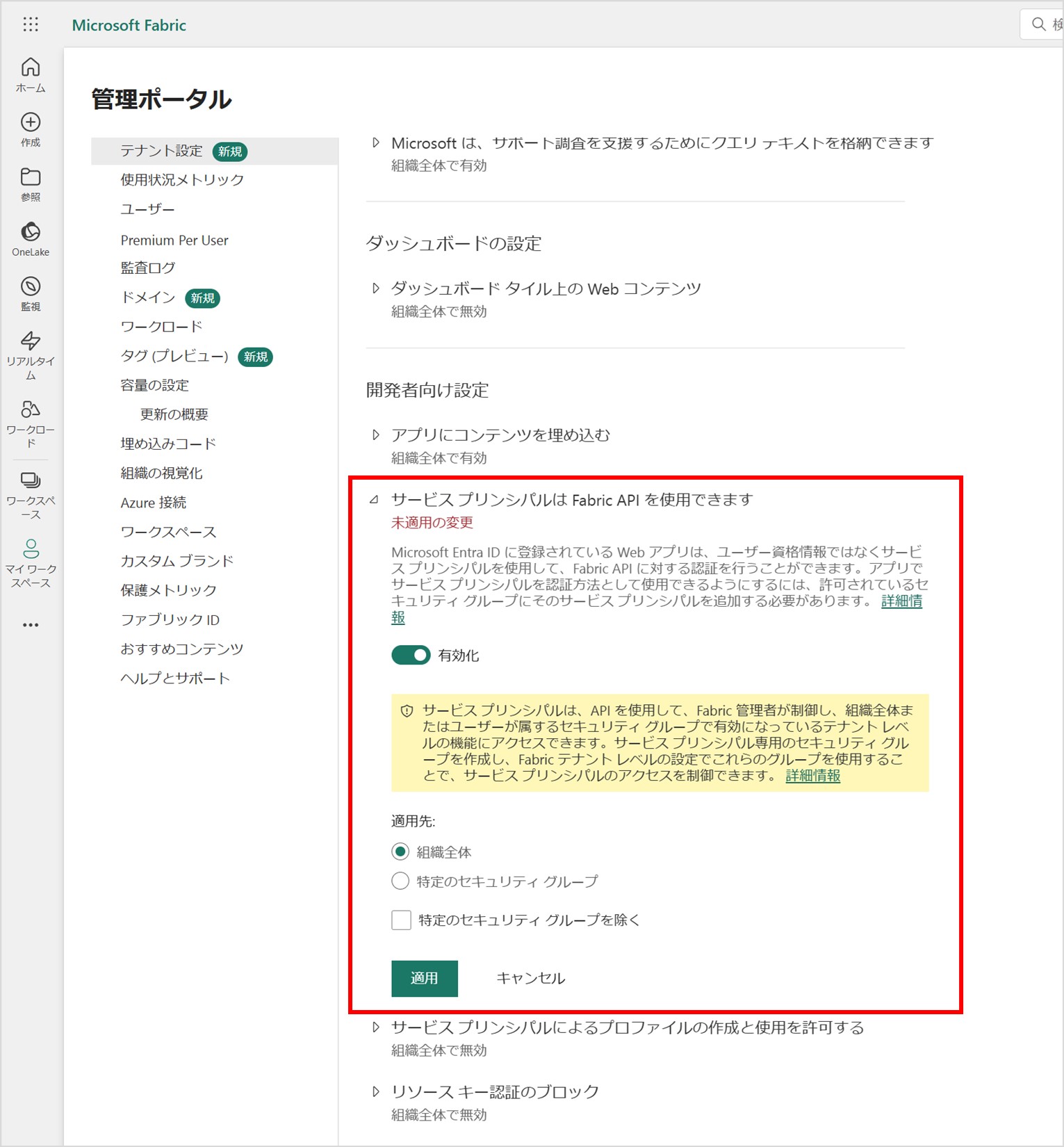
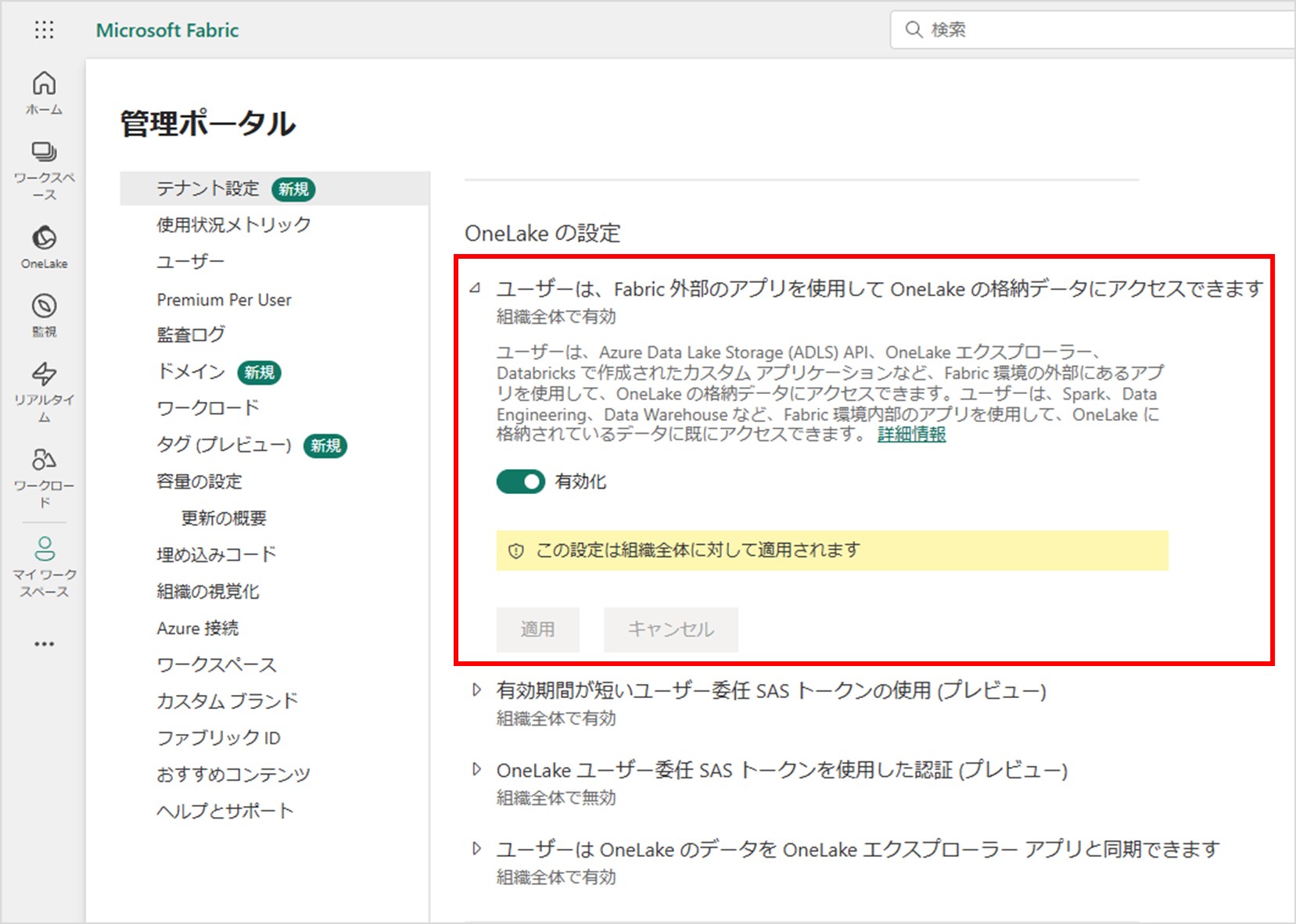
最初に、Microsoft Fabric のテナント設定を実施します。実施する内容は、ドキュメントの前提条件に記載のある以下の項目となります。
Microsoft Fabric ポータル画面の右上にある歯車のアイコンから「管理ポータル」をクリックすると、テナント設定の画面に遷移します。テナント設定の画面で上記項目を設定してください。
ワークスペースの作成を行います。既にワークスペースが存在する場合は、次の「ミラー化 Azure SQL データベースの作成」に進んでください。
新規に作成する場合は以前の記事を参照してください。
ここからがミラーリングの設定となります。
ワークスペースを作成後、ワークスペースの「新しい項目」より「ミラー化された Azure SQL データベース」を選択します。
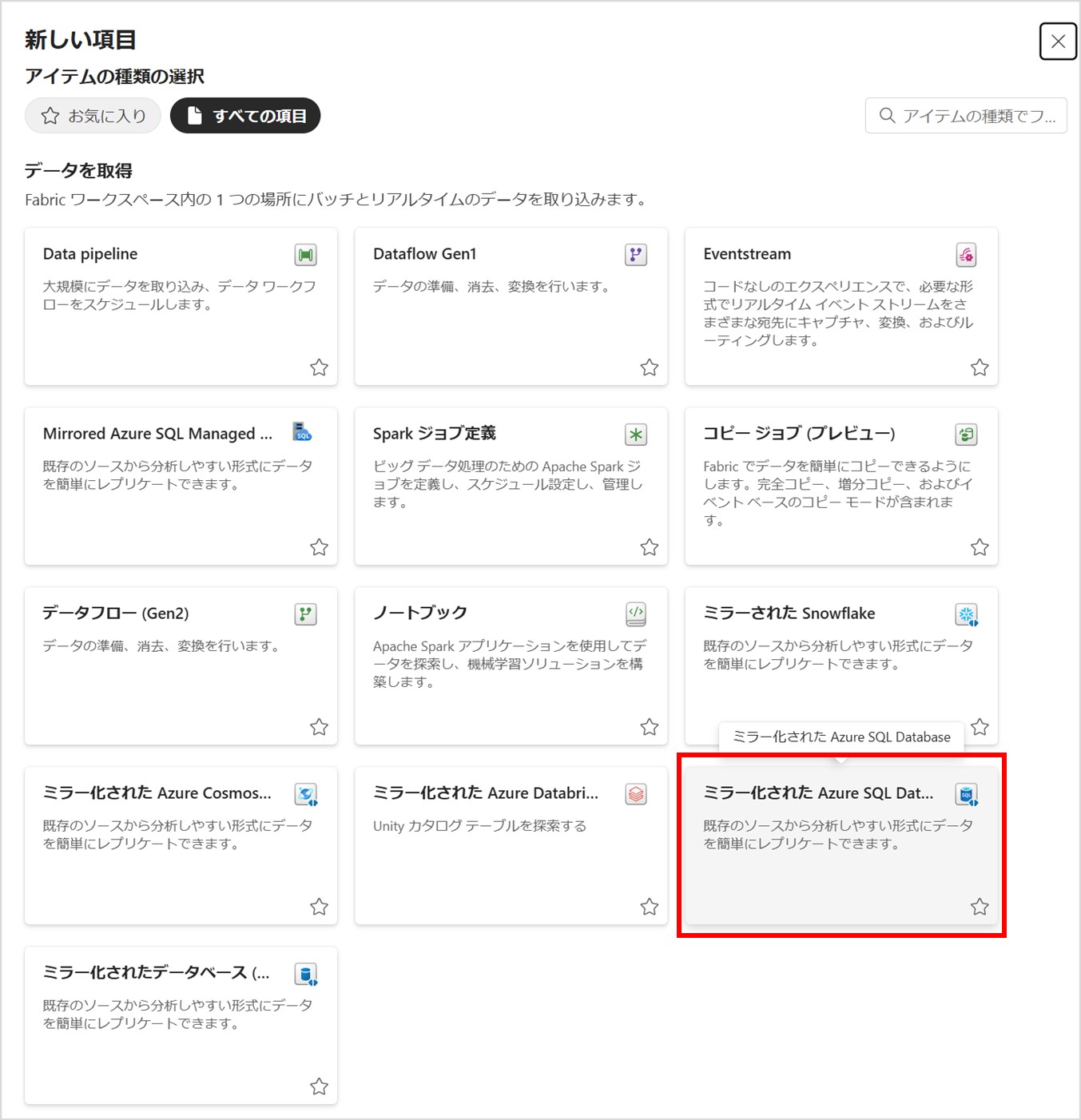
下図のような画面が出てくるので、「新しいソース」にある「Azure SQL Database」を選択します。

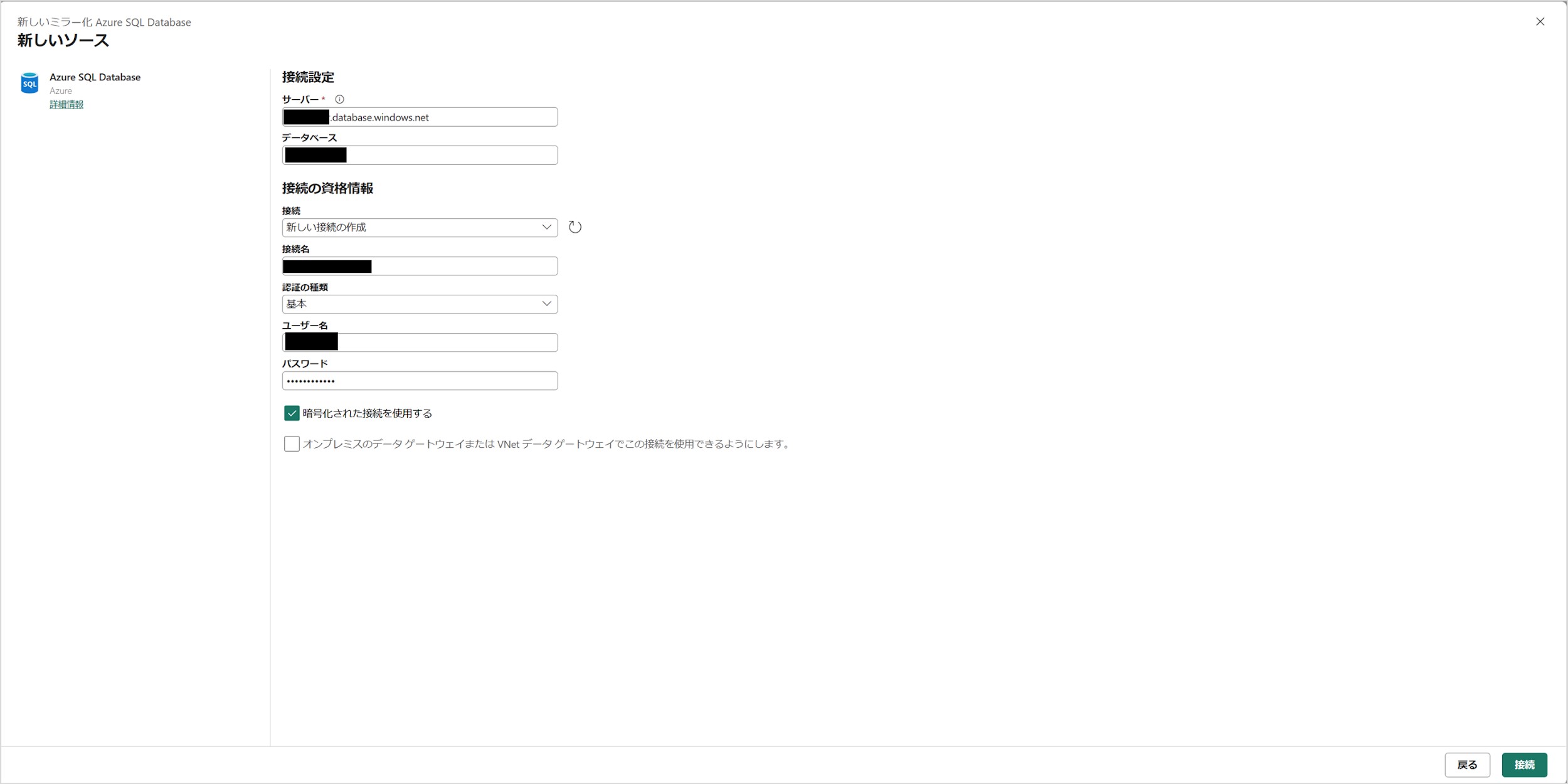
「新しいソース」の画面が出てくるので、「Azure SQL Database の準備と必要な設定」で作成した Azure SQL Database の接続情報を入力して、「接続」をクリックします。
こちらの設定は、以前の記事にある「コピーウィザードの設定」とほぼ同じ設定となっています。
<入力項目>
| カテゴリ | 入力項目 | 値 |
|---|---|---|
| 接続設定 | サーバー | Azure SQL Database のサーバー名 |
| データベース | Azure SQL Database のデータベース名 | |
| 接続 | 「新しい接続の作成」で OK | |
| 接続名 | 任意で設定可能。 サーバーとデータベースを入力すると、デフォルトで以下のように自動入力される。 <サーバー>;<データベース> | |
| 認証の種類 | 以下 3 つから選択。 基本:SQL 認証(ID とパスワード入力) 組織アカウント:ユーザーアカウント サービスプリンシパル | |
| 暗号化された接続を使用する | チェックを入れる | |
| オンプレミスのデータゲートウェイまたは VNet データゲートウェイでこの接続を使用できるようにします | チェックを外す |
「接続」をクリックすると、Microsoft Fabric が設定した Azure SQL Database に接続してテーブル情報を取得し、ミラーリング可能かどうかのアセスメントを行います。
アセスメントが完了した後、「データの選択」画面に遷移し、下図のようなミラーリング可能なテーブルを選択できるようになります。ミラーリングを実施したいテーブルをチェックし「接続」をクリックします。
今回はアセスメント結果でチェックがついているテーブルと、検証のためエラーになったテーブルひとつ(dbo.BuildVersion)にチェックを入れました。
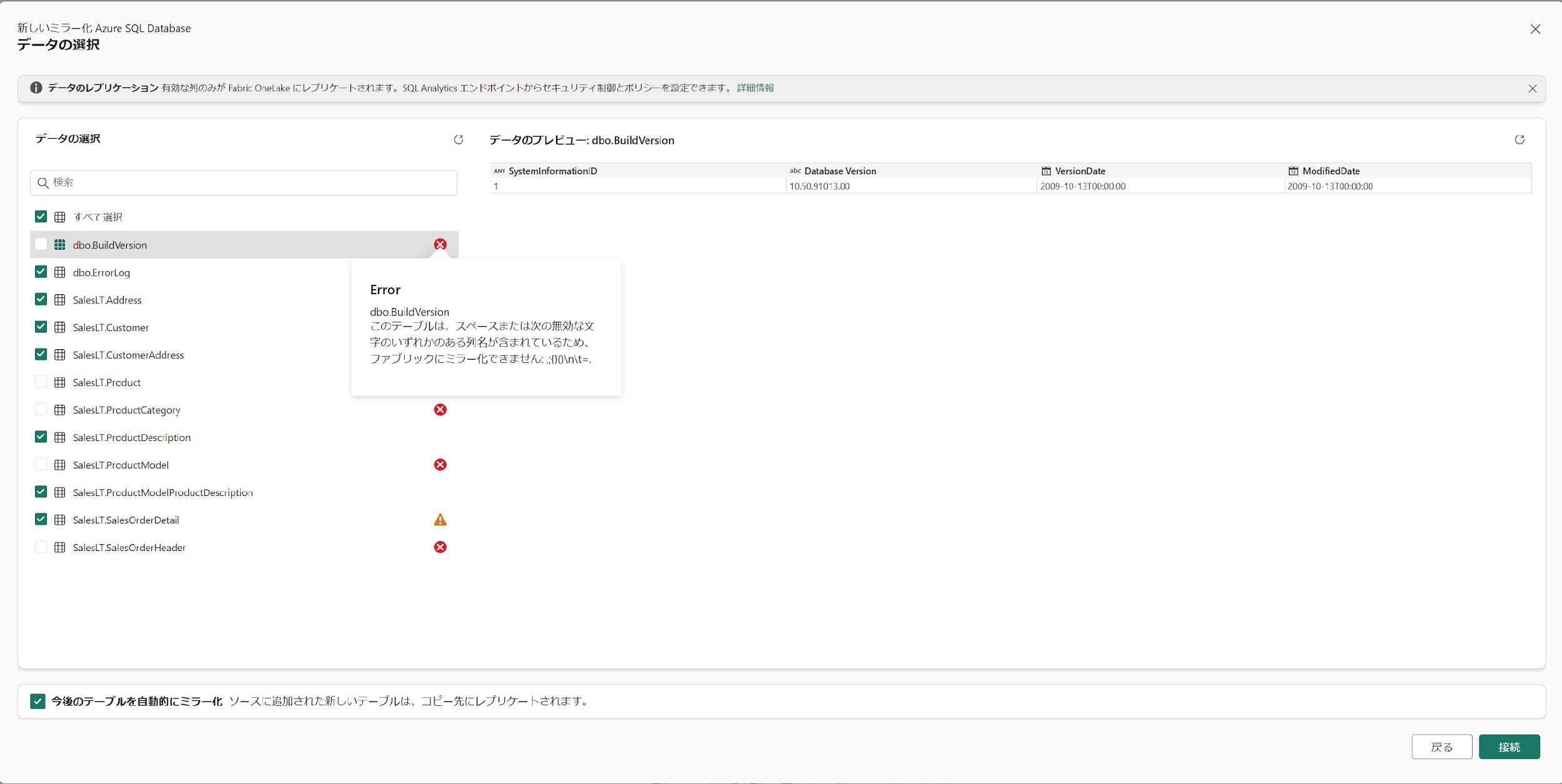
補足事項:
Azure SQL Database のサンプルデータベースのミラーリングでは、上図の通りいくつかのエラー、警告が出てきました。レプリケート元の Azure SQL Database におけるテーブル・カラムの型・桁数に注意する必要があります。
<エラー、警告の内容>
| 種別 | 内容 | ミラーリングへの影響 |
|---|---|---|
| エラー | このテーブルは、スペースまたは次の無効な文字のいずれかのある列名が含まれているため、ファブリックにミラー化できません: ,;{}()\n\t=. | ミラーリング不可能。 |
| 主キー列で次のいずれかのデータ型が使用されているため、このテーブルを Fabric にミラー化できません: 計算型、ユーザー定義型、geometry、geography、階層 ID、SQL バリアント、datetime2(7)、datetimeoffset(7)、time(7) またはタイムスタンプ。 | ||
| 警告 | テーブルにサポートされていない列 (列名(型<桁数>)) が含まれています。これらの列はレプリケートされません。 ※サポートされていない列:nvarchar<UDT>, nvarchar<Computed>, xml, money<Computed>,bit<UDT>,numeric<Computed> | テーブルのミラーリングは可能だが、該当の列はミラーリングされない。 (不完全な状態でのミラーリング) |
ミラーリングを実施したいテーブルをチェックし「接続」をクリック後、「宛先」の画面に遷移します。ここでミラーリング先(= Microsoft Fabric の「ミラー化されたデータベース」)の名前をつけます。名前を入力したら「ミラー化されたデータベースを作成する」をクリックします。
クリック後、ミラー化されたデータベースが作成され、レプリケートが開始されます。
「レプリケーションの監視」からミラーリングの状況を確認できます。
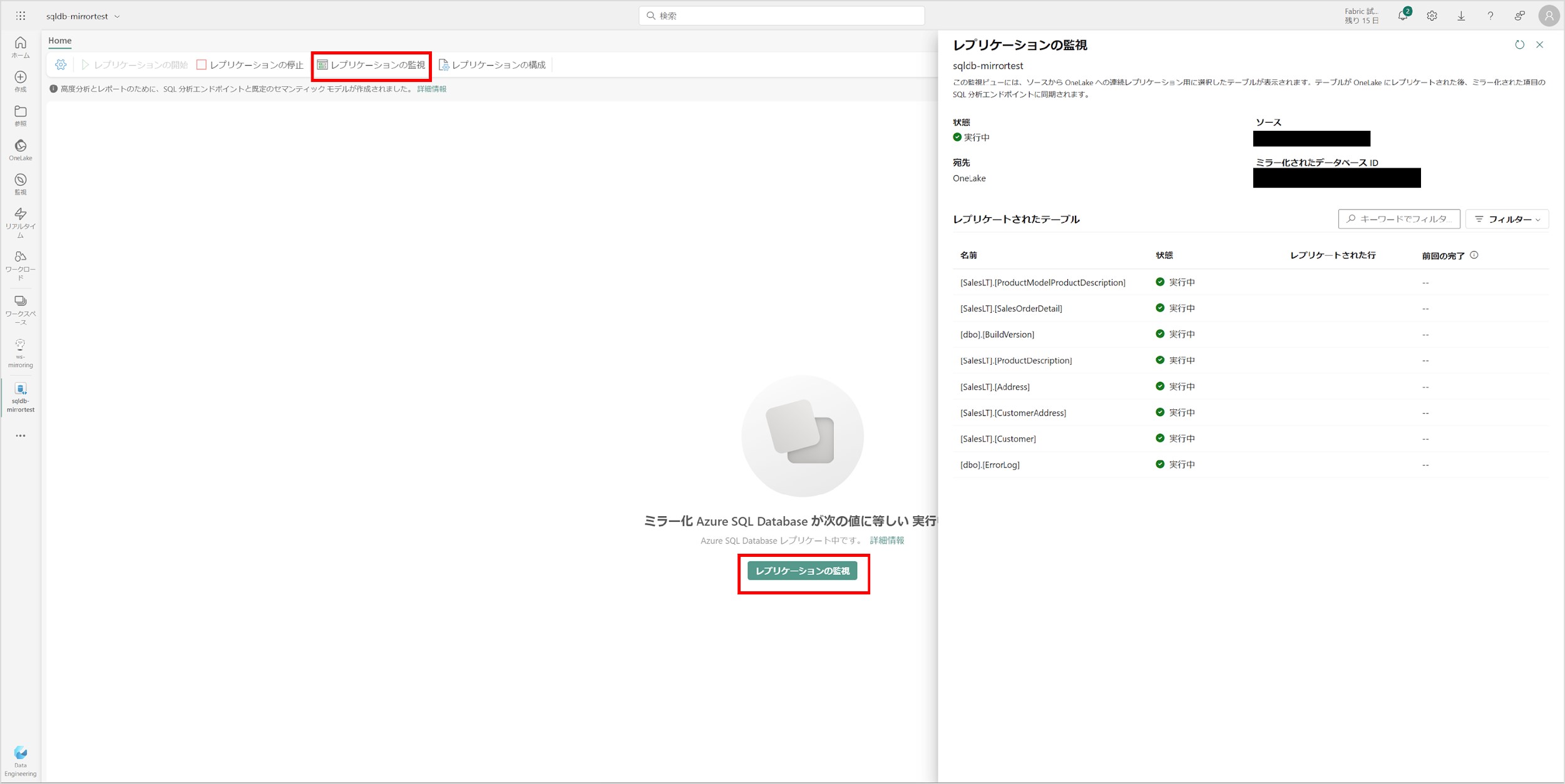
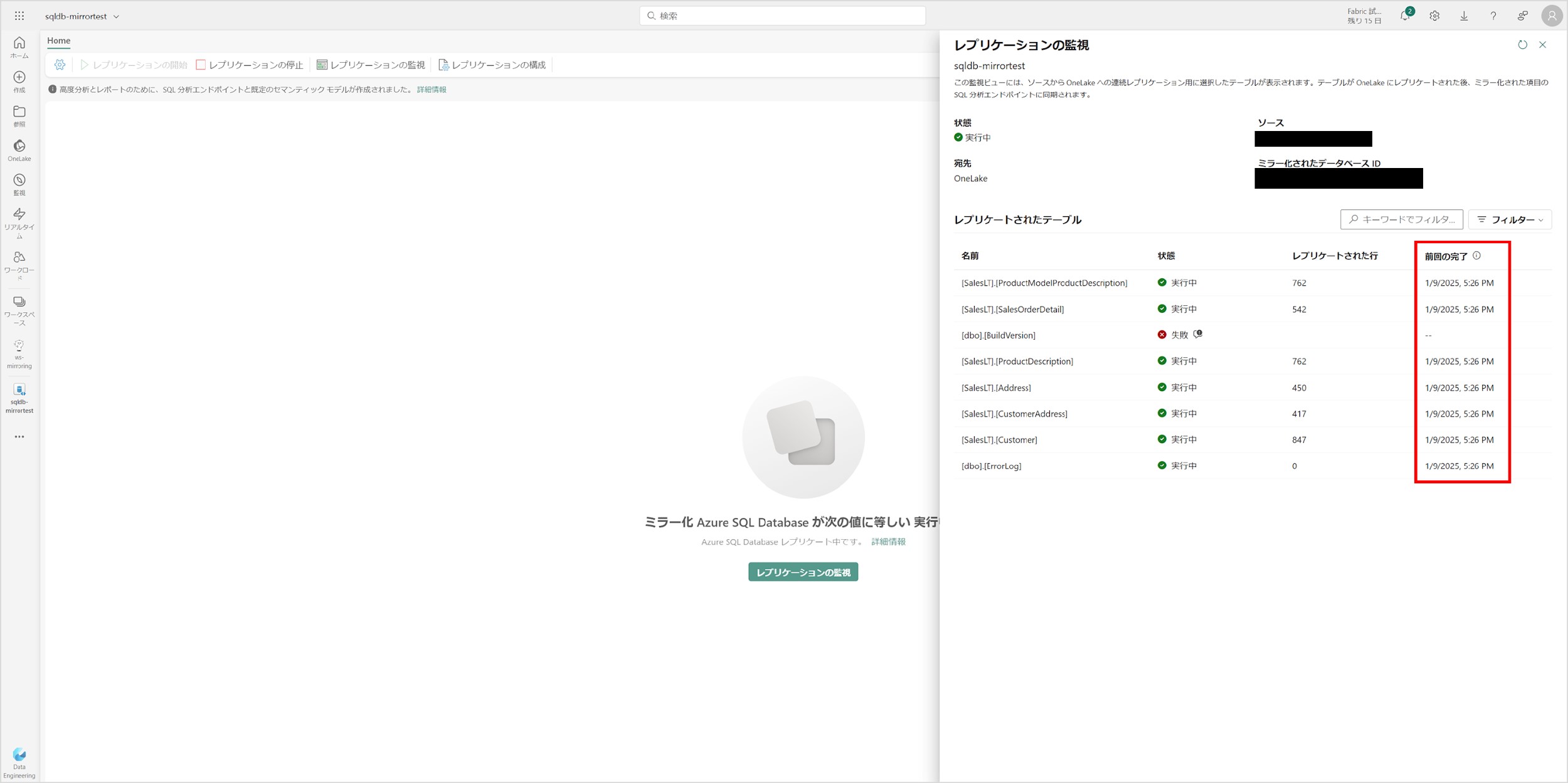
「レプリケーションの監視」にある「前回の完了」列に日時が表示されたら、レプリケート完了となります。これで Azure SQL Database のミラーリング設定が完了しました。
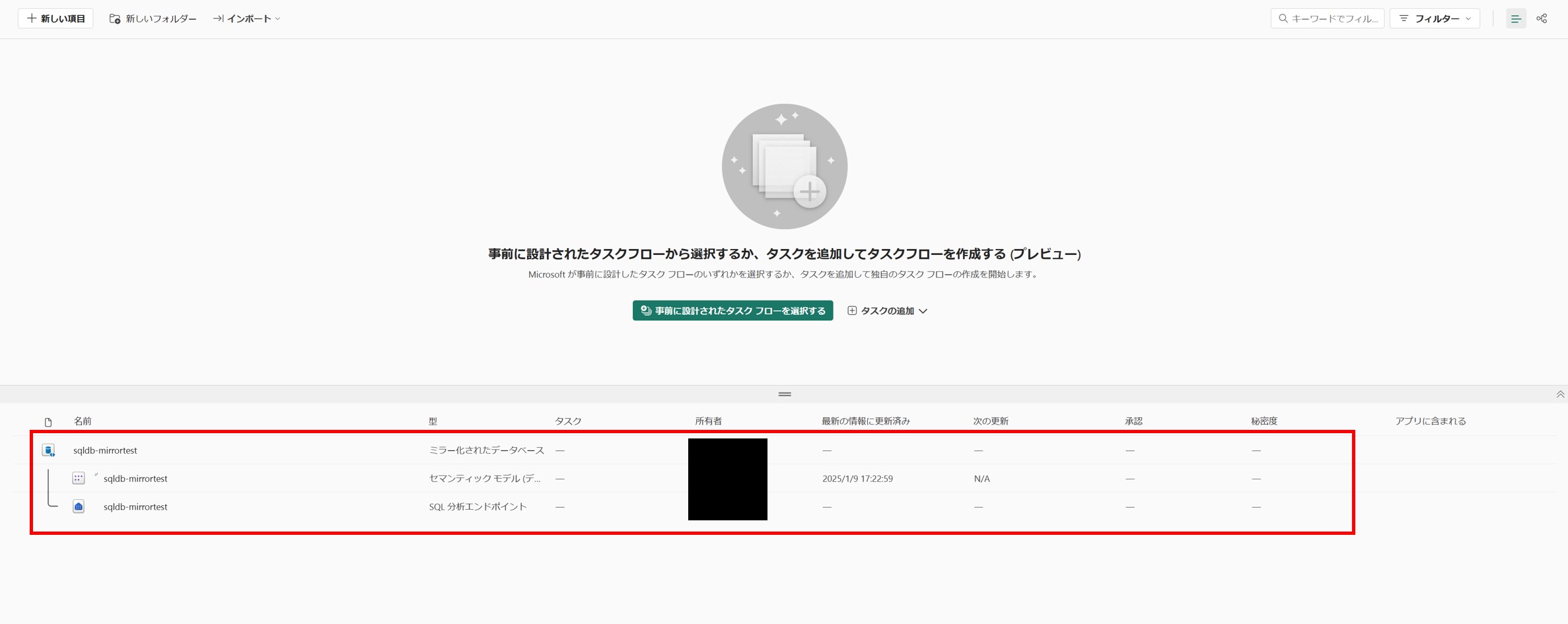
ワークスペースには下図のような形で表示されます。
アイコンが通常のウェアハウスのアイコンと少し異なるのがポイントです。
補足事項:
今回の検証では、Azure SQL Database のサンプルデータベースを使ってミラーリングの設定を実施したところ、サンプルデータベースで初回のレプリケート完了までに5分程度かかりました。
テーブル数、カラム数、レコード数が多い場合、ミラーリング設定の実施タイミングも考慮する必要がありそうです。
ミラーリングの設定が完了したので、ミラーリングの挙動を調査してみました。
<レプリケート直後・レプリケーション成功したテーブル>
Azure SQL Database のテーブルの内容がすべて Microsoft Fabric にレプリケートされていました。
<レプリケート直後・アセスメント結果でエラーが出たテーブル>
Microsoft Fabric にテーブルは存在しますが、警告が出た列はレプリケートされないため、部分的なレプリケートになっていました。
<レプリケート直後・アセスメント結果で警告が出たテーブル>
レプリケートに失敗するため、該当テーブルは Microsoft Fabric 内には存在しません。
<Azure SQL Database でのデータ追加・更新・削除>
レプリケート元である Azure SQL Database のテーブルレコードを追加・更新・削除すると、問題無く Microsoft Fabric 側にも反映されました。
Microsoft Fabric 側に反映されるのに1~2分程度のラグがあったため、「ニアリアルタイムでのデータ同期」を実感できました。
<ミラーリングの停止>
ミラーリングの停止は簡単に実行できます。Microsoft Fabric ワークスペースより作成した「ミラー化されたデータベース」を開き、画面上部にある「レプリケーションの停止」をクリックします。ポップアップが出てくるので、「停止」をクリックするとミラーリングが停止されます。
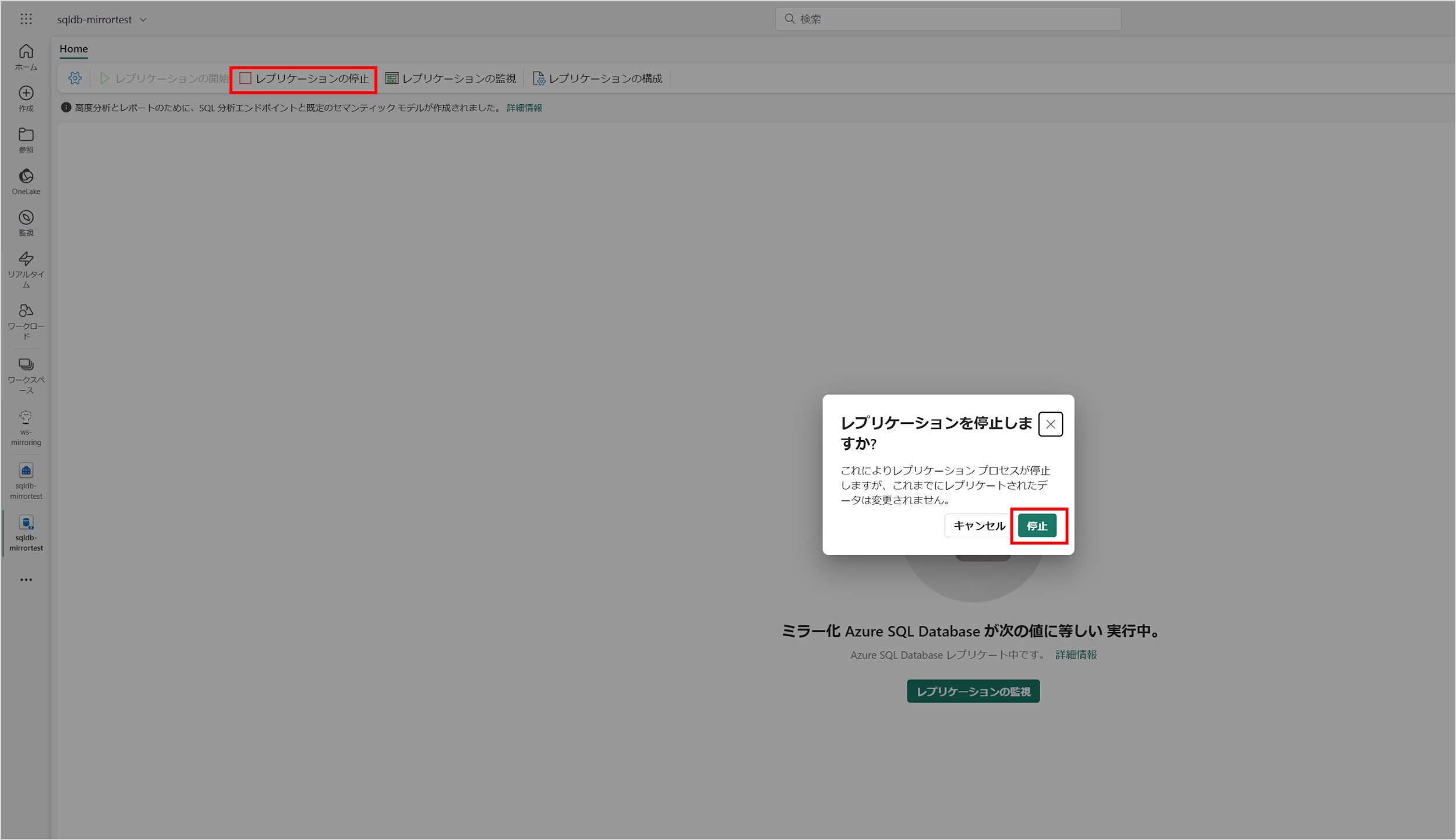
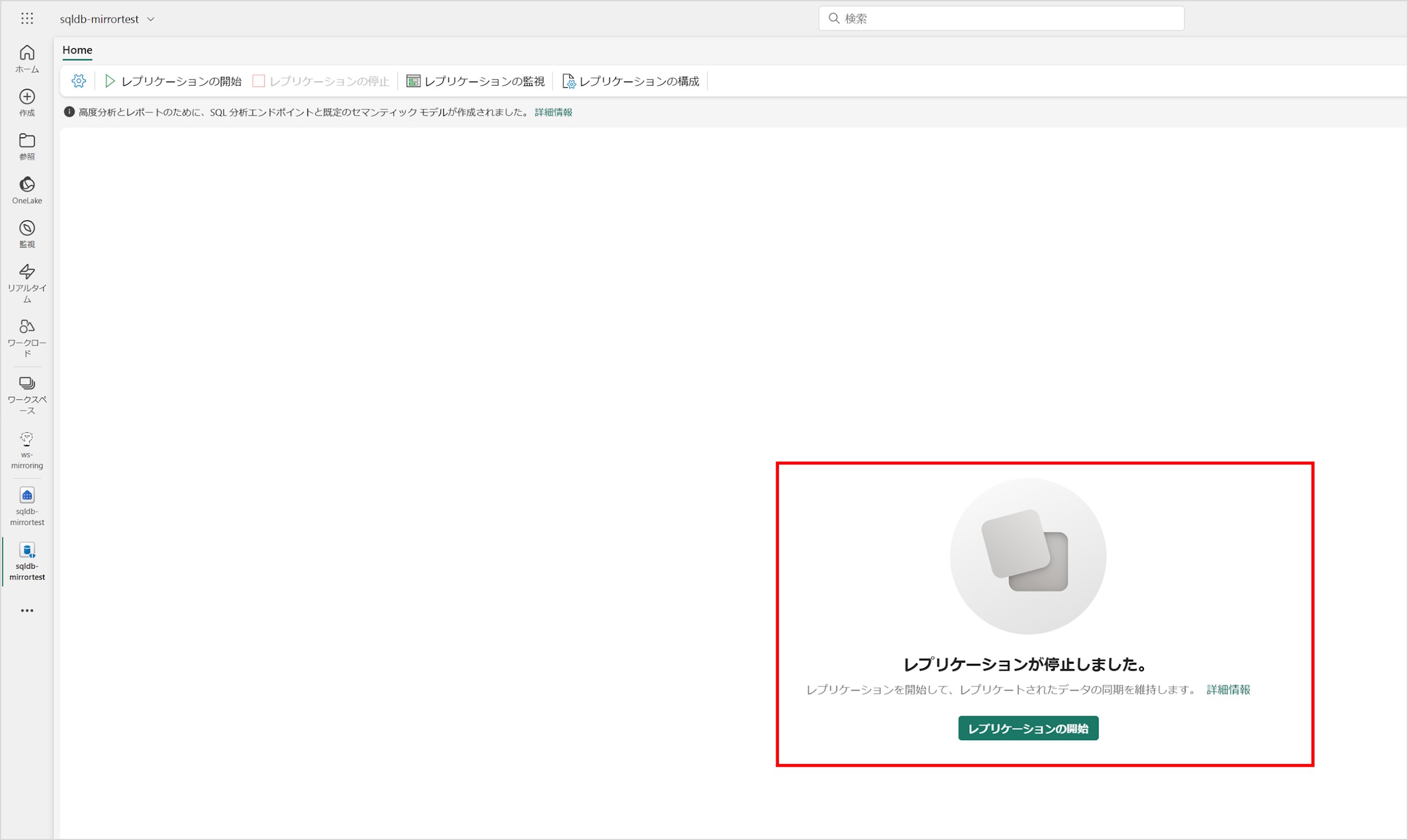
下図のような画面になったら、ミラーリングが停止されています。
ミラーリングを再度実施したい場合は、画面上部にある「レプリケーション開始」をクリックすると再実行されます。その際、すべてのデータが最初からレプリケートされます。
参考:Fabric ミラーリングを停止または一時停止する|Microsoft Fabric Azure SQL Database のミラーリングに関してよくあるご質問
今回は Azure SQL Database のミラーリングについてご紹介しました。
制限事項がいくつかありますが、ETL の実装無しで簡単な設定で Azure SQL Database から Microsoft Fabric へデータを連携できることがわかったかと思います。
本検証を通じて、現状、ミラーリングは以下のような場面で活用できそうだと感じました。
<ミラーリングの活用方法>
迅速なデータ活用を実施できる一案として、検討してみてはいかがでしょうか。
あなたにオススメの記事

2023.12.01
生成AI(ジェネレーティブAI)とは?ChatGPTとの違いや仕組み・種類・活用事例

2023.09.21
DX(デジタルトランスフォーメーション)とは?今さら聞けない意味・定義を分かりやすく解説【2024年最新】

2023.11.24
【現役社員が解説】データサイエンティストとは?仕事内容やAI・DX時代に必要なスキル

2023.09.08
DX事例26選:6つの業界別に紹介~有名企業はどんなDXをやっている?~【2024年最新版】

2023.08.23
LLM(大規模言語モデル)とは?生成AIとの違いや活用事例・課題

2024.03.22
生成AIの評価指標・ベンチマークとそれらに関連する問題点や限界を解説
















