



メルマガ登録
-
テーマから探す
-
技術から探す
-
業界・事例から探す
-
関連トレンドから探す
テーマから探す
技術から探す
業界・事例から探す
関連トレンドから探す


深層学習を使った音声データによる楽曲分類を実施しました!楽曲の特徴を表すメル周波数スペクトログラムを用いて、その楽曲のアーティストを推定します。
こんにちは、アナリティクスサービス本部の井出です。
今回のブログは、音声データをテーマとして取り上げ、
についてご紹介します。
ブレインパッドでは、深層学習の技術を駆使した活用事例が増えてきています。特に、画像認識の分野における活用事例は多く、当社の公開されている事例だけでも以下のようなものがあります。
一方で、音声データを扱う事例はなかなか珍しい印象です。
筆者は音楽を聞くことが好きだということと、音声データをテーマとした深層学習に以前から興味があり、勉強の一環として自宅で楽曲分類をテーマとして取り組んでいました。今回はその結果についてご紹介させていただきます。
また、音声データについて不慣れな人も多いと思いますので、ブログの前半で基礎的な内容をご紹介しています。
基礎的な内容は必要無いという方は、後半から読んでいただければ幸いです。
【関連記事】音楽をデータサイエンスで解き明かす
音は波として考えることができます。普段、私たちが聞いている音というのは発生した音が空気中に波として伝わり、この波が人間の耳の鼓膜を揺らすことで音として感知します。この音の波が振れる幅(振幅)が大きいほど私たちには大きい音として聞こえ、揺れているスピード(波長)が早いほど、高い音として聞こえます。 音の波を見える形で表すと、概ね周期的な以下のような波形となります。
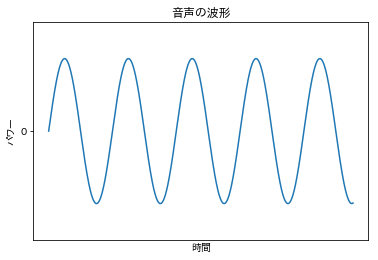
しかし、この音の波は連続信号(アナログ)であるため、コンピュータではこの音の波をそのまま扱うことはできません。コンピュータで音の波をデータとして扱うためには、一定の間隔で測定することにより離散信号(デジタル)に変換する必要があります。これをアナログ-デジタル(AD)変換といいます。
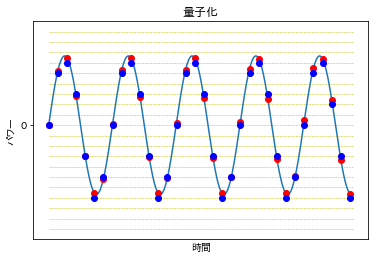
音声をAD変換するためには、標本化(サンプリング)と量子化が必要となります。標本化(サンプリング)とは時間的に連続する信号を離散化することであり、量子化とは信号の大きさを離散化することをいいます。 先程の音の波を例とすると、下図における標本化の結果が赤点、標本化に加えて量子化を行った結果が青点に該当します。

以上のようにして得られる音声データは、正弦波として数式化することができます。
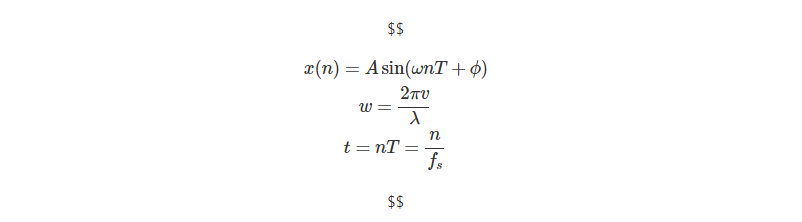

実際の音声データは、通常、複数の周波数の波が重なったものであり、このような波形となります。


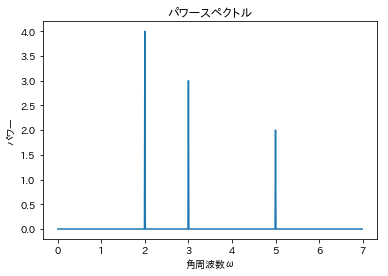
音声データの特徴量として、メル周波数スペクトログラムというものがあります。
メル周波数スペクトログラムは、以下の手順で算出することができます。
音声データを解析する場合、一般に一定の時間間隔で特徴量を出力します。その際、間隔ごとに分割された対象を音声フレームと呼び、その間隔をフレーム周期と呼びます。フレーム周期と信号の周期が一致しない、つまり、両端が不連続な波形は、そのまま周波数分析をすると高周波に雑音がのります。そこで、波形に対し、この時刻を中心に両端が減衰するように窓関数をかけます。 代表的な窓関数であるハミング窓は以下のように表されます。N�は窓内のサンプル数です。
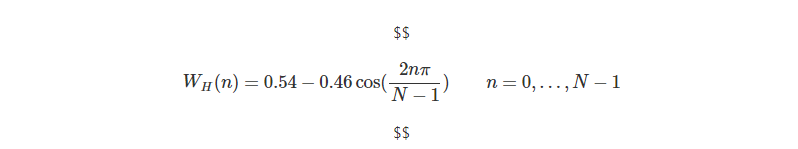

実際に音声データに対して窓関数を適用する際は、連続する音声フレームに対して窓関数を少しずつずらしながら、その都度、離散フーリエ変換を適用していくことになります。また、この一連の処理を短時間フーリエ変換といいます。これは、重み付き移動平均をとっていることに相当し、特徴量の急激な変化を抑える一方で、連続するフレーム間の相関はより大きくなります。 これにより、音声データから一定の時間間隔でパワースペクトルを抽出することができます。

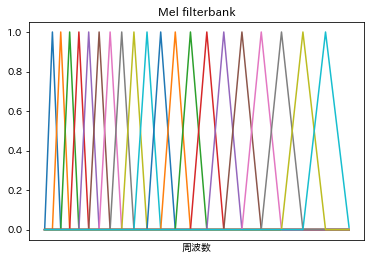
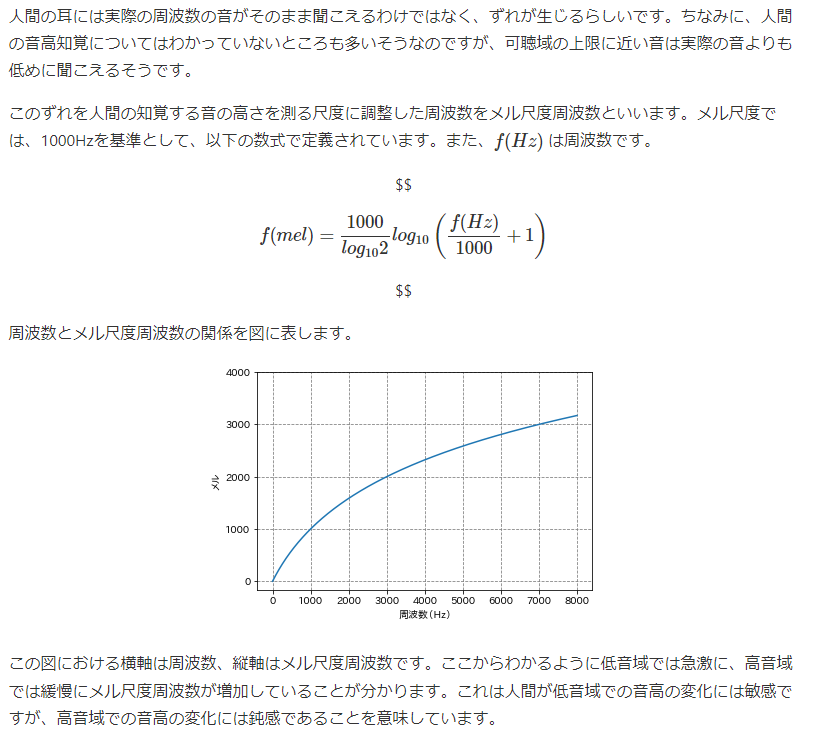
パワースペクトルに対して得られたメルフィルタバンクの各フィルタをかけ、フィルタ後のパワーを足し合わせて対数を取ることで、音圧レベル(dB)スケールのN�次元のデータとしてスムージングします。これにより任意の時間ごとに得られる人間の音高知覚に調整した特徴量をメル周波数スペクトログラムといいます。
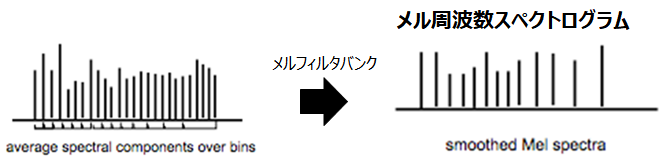
また、今回は使用しませんが、このメル周波数スペクトログラムを離散コサイン変換した結果から低次元成分を取り出したものを、メル周波数ケプストラム係数(MFCC)といいます。
深層学習を使って音声データを活用してみるため、楽曲分類に取り組みました。内容としては、楽曲の特徴を表すメル周波数スペクトログラムを用いて、その楽曲のアーティストを予測するという内容です。
学習した深層学習モデルを用いて2つの実験を実施しました。
ここから、上記の取り組みに関してご紹介します。
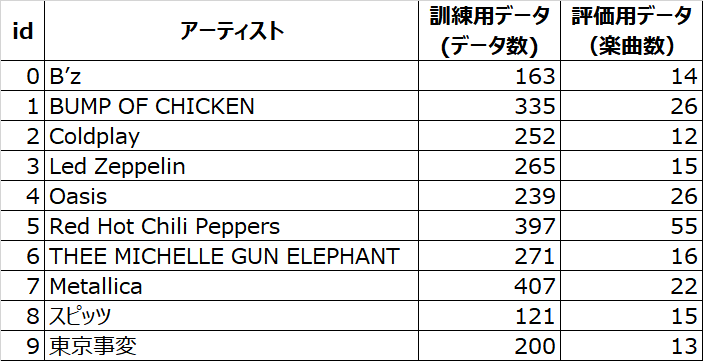
今回はランダムに10組のアーティストを選別し、楽曲分類の対象としました。 これらの楽曲をデータとしてモデルが学習することになるのですが、楽曲には限りがあり、一番多くてもRed Hot Chili Peppersの179曲と、学習データとしては少ないです。
そのため、楽曲を1分ごとに区切ることでデータの水増しをしました。(これでもデータとしては少ないですが・・・)
モデルに学習させる訓練用データとモデルの精度を検証する評価用データを用意する際には、発表された年が古いアルバムの楽曲を訓練用データ、新しいアルバムの楽曲を評価用データとしました。使用したデータ数は以下のとおりです。
実際に楽曲「ロビンソン/スピッツ」の特徴量を最初の60秒分だけ可視化してみました。サンプリング周波数にもよるのですが、データの波形は非常に細かくなっています。これだけでは、何もわかりませんね。
import librosa.display
# Load a flac file from 0(s) to 60(s) and resample to 4.41 KHz
filename = 'ロビンソン.flac'
y, sr = librosa.load(filename, sr=4410, offset=0.0, duration=60.0)
librosa.display.waveplot(y=y, sr=sr)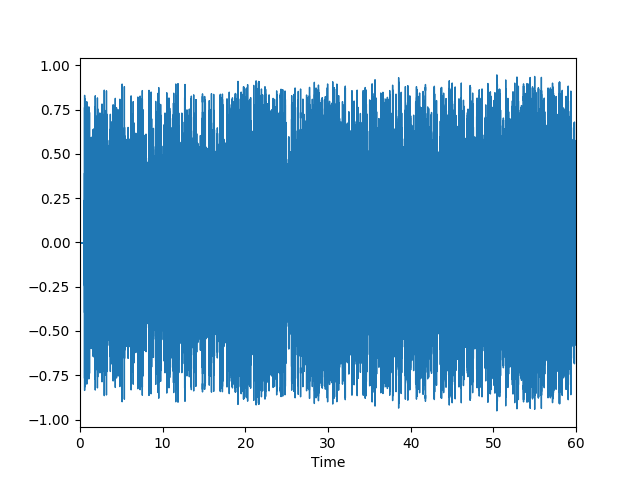
ロビンソン / スピッツ
次に、このデータのメル周波数スペクトログラムを可視化しました。各種パラメータは適当に決めていますが、こちらは各時間帯における周波数ごとの音の強さが濃淡として表現されており、視覚的にも楽曲の特徴を表している感じがしますね。
# n_mels is number of Mel bands to generate
n_mels=128
# hop_length is number of samples between successive frames.
hop_length=2068
# n_fft is length of the FFT window
n_fft=2048
# Passing through arguments to the Mel filters
S = librosa.feature.melspectrogram(y=y, sr=sr, n_mels=n_mels, hop_length=hop_length, n_fft=n_fft)
log_S = librosa.power_to_db(S, ref_power=np.max)
print(log_S.shape)
plt.figure(figsize=(12, 4))
librosa.display.specshow(data=log_S, sr=sr, hop_length=hop_length, x_axis='time', y_axis='mel')
plt.colorbar(format='%+2.0f dB')
plt.title('Mel spectrogram')
plt.tight_layout()(128, 128)
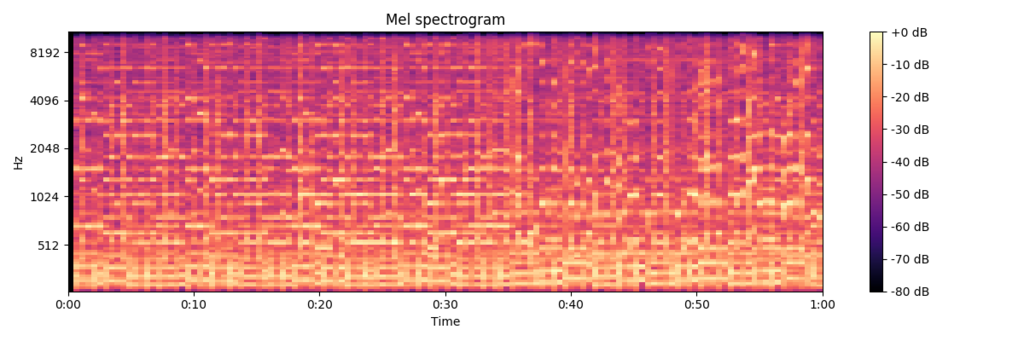
ロビンソン / スピッツ
上記のように、可視化された画像自体がその楽曲の特徴を表しているといえます。これは、時系列と周波数ごとに音圧レベル(dB)が並んでいるためです。つまり、音声データの分類は、画像の分類問題と似た捉え方ができます。そのため、今回使用するモデルは画像分類の分野で成功を収めている、CNN(Convolutional Neural Network)を採用しました。
音声データから楽器を分類するという論文でも、CNNが用いられており、高い精度が得られています。今回のモデルでも本論文のように下記のようなシンプルなアーキテクチャとしました。
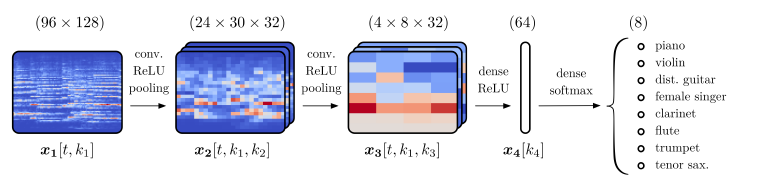
本モデルの出力層では、softmaxを用いていることから、入力した音声データに対するアーティストごとの確率が出力されます。モデルがある楽曲のアーティストを分類する際には、1分区切りした各音声データに対して、確率を算出し、これらの確率の平均を取ることで、最も高い確率となるアーティストを予測結果としました。
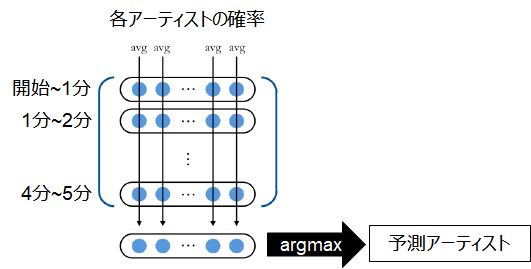
訓練用データで学習したモデルの精度を評価用データ(楽曲)に対する適合率、再現率、F値で評価しました。結果は以下のようになりました。
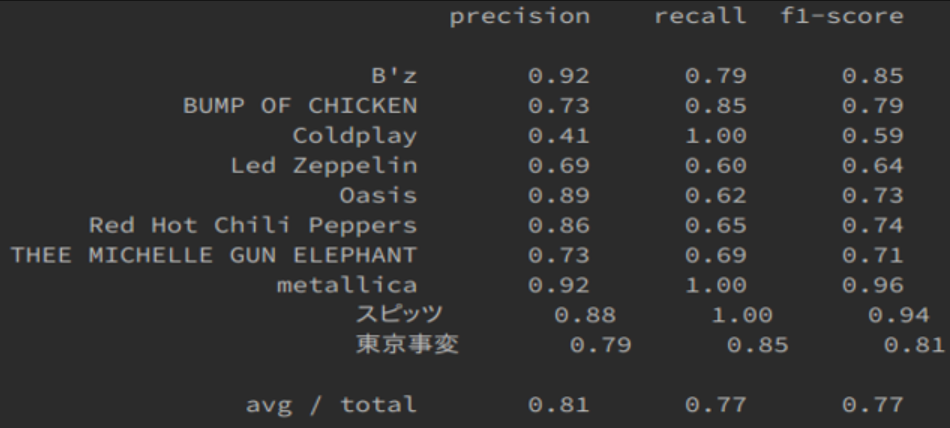
F値は平均で0.77という結果が得られました。
特にスピッツとMetallicaはどちらも再現率1.0であり、F値も0.9以上という結果が得られました。一方で、Coldplayは再現率は1.0であったにも関わらず適合率が0.41と低く、F値も0.59と最も低い結果となりました。つまり、Coldplayの楽曲は全て正しく予測することが出来ましたが、それ以外のアーティストの楽曲をColdplayと誤って予測してしまったということになります。
これは筆者の主観的な考察になるのですが、Coldplayの初期はアコースティックギターを使ったロックサウンドの曲が多い印象ですが、近年は多彩な音を入れ込んだ壮大なポップサウンドの曲が増えてきています。このため、モデルが学習した楽曲の中にはこれらのジャンルが混合していたことから、ロックサウンドな曲やポップサウンドな曲は比較的、Coldplayと予測されやすいモデルになっているのかもしれません。実際、Coldplayと予測された楽曲のアーティストを確認すると、Red Hot Chili PeppersやOasisなど、ロックバンドの楽曲を誤分類する傾向がありました。

Yellow / Coldplay (初期の曲)
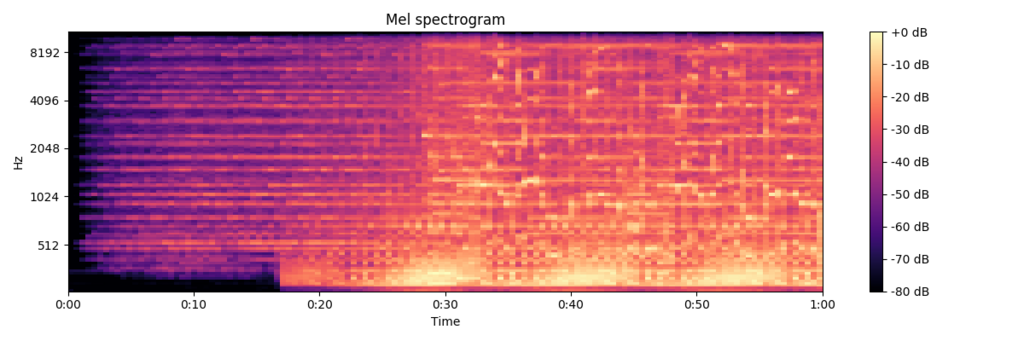
A Head Full Of Dreams / Coldplay (最近の曲)

Dark Necessities / Red Hot Chili Peppers(モデルがColdplayと予測した曲)
次に、学習で使用していないアーティストの楽曲を用意し、上記の学習済みモデルによるアーティスト分類を行ってみました。つまり、モデルは、入力されたある楽曲が選別した10組のアーティストのうち、どれに近いのかを出力するということになります。この実験では、学習で使用した10組のアーティストのいずれかと、著者が似ていると感じていたアーティスト5組を選別して評価しました。選別したアーティストと選別理由は以下のようになります。

得られた結果は以下のようになりました。

ここでは縦軸が予測対象の楽曲のアーティスト、横軸がモデルで用意した10組のアーティストのidを表しており、それぞれの値は予測された楽曲数です。 赤枠で囲った箇所が、個人的に似ていると感じていたアーティストの組み合わせになるのですが、概ね想定通りの結果が得られています。 特にThe Birthdayは43.6%の楽曲がボーカルが同じTHEE MICHELLEGE GUN ELEPHANTと分類されたことから、声の特徴を捉えていることが分かります。

ローリン / The Birthday (モデルがTHEE MICHELLE GUN ELEPHANTと予測した曲)

赤毛のケリー / THEE MICHELLE GUN ELEPHANT
BABYMETALは唯一の女性ボーカルである東京事変と予測されやすいとも考えていたのですが、実際は2曲のみが予測されただけでした。一方で、同じジャンルであるMetallicaと予測された楽曲が9曲と最も多かったことから、声の特徴だけでなく、演奏の特徴も考慮した予測がされていることがわかります。
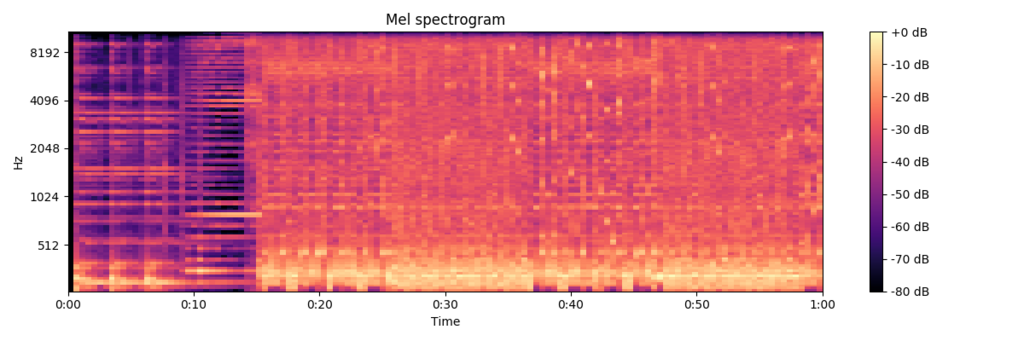
Catch me if you can / BABYMETAL (モデルがMetallicaと予測した曲)
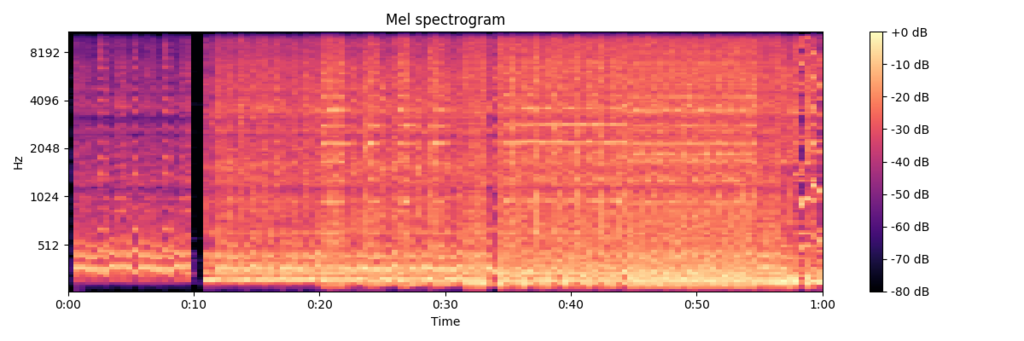
St. Anger / Metallica
学習した深層学習モデルは、楽曲のアーティスト検索等のように、アーティストを直接予想したいタスクへの応用を考えると精度は低い印象です。
一方で、類似アーティストの分類においては、概ね想定通りの結果が得られていたため、類似アーティストのレコメンド等のような、高い精度を求められていないタスクに対しては応用ができそうです。
また、今回はアーティストの分類というモデルを作成したのですが、これを音楽ジャンルの分類に変更することで、用意できる学習データ数も増え、精度の向上が期待できます。これにより、楽曲への音楽ジャンルの自動付与などにも応用できそうです。
楽曲に限らず、例えば、機械が発する音をデータとして扱うことで、機械の故障に繋がる異常音を検知するなど、ビジネスのさまざまな課題に対しても応用が期待できそうですね。
今回は音声のデータとしての扱い方と、深層学習モデルによる楽曲のアーティスト分類への個人的な取り組み内容について、紹介させていただきました。
ブレインパッドでは、データの活用を推進しています。データといっても、リレーショナルデータベースなどで扱う表形式の構造化データに限らず、今回取り扱った音声や、画像、言語等のように様々な種類のデータがあります。 そして、なんとなく集めているだけのデータであっても、それを活用することで何らかの課題の解決に繋がるかもしれません。
本ブログで、データ分析の取り組みについて興味を持っていただけたら幸いです!
あなたにオススメの記事

2023.12.01
生成AI(ジェネレーティブAI)とは?ChatGPTとの違いや仕組み・種類・活用事例

2023.09.21
DX(デジタルトランスフォーメーション)とは?今さら聞けない意味・定義を分かりやすく解説【2024年最新】

2023.11.24
【現役社員が解説】データサイエンティストとは?仕事内容やAI・DX時代に必要なスキル

2023.09.08
DX事例26選:6つの業界別に紹介~有名企業はどんなDXをやっている?~【2024年最新版】

2023.08.23
LLM(大規模言語モデル)とは?生成AIとの違いや活用事例・課題

2024.03.22
生成AIの評価指標・ベンチマークとそれらに関連する問題点や限界を解説


















