



メルマガ登録
-
テーマから探す
-
技術から探す
-
業界・事例から探す
-
関連トレンドから探す
テーマから探す
技術から探す
業界・事例から探す
関連トレンドから探す

こんにちは、アナリティクスサービス本部の金田です。
現在私は、自然言語処理の研究開発チームにいます。直近では、文書間の類似度や文書クラスの判別について、最新の知見をキャッチアップして、社内に共有しています。本ブログでは、自然言語処理手法の一つであるDoc2VecとDANを使った論文の質の予測をご紹介します。
今回は、私が大学で専攻した素粒子理論の論文データを使い、重要度クラスで分類しました。なお、簡単化のために、対象の論文の著者は1人に絞り、評価は被引用論文数と発表年を元に作成したクラスを使用します。
物理分野では、インターネットが使われだした初期から、論文投稿と同時に、[arXiv](https://arxiv.org)というプレプリントサーバー(未査読論文用サーバー)にも投稿して、論文の蓄積・配布を行っています。このarXivはコーネル大学図書館が運営するもので、現在は物理分野以外に、数学や統計学、コンピューターサイエンス等の未査読論文も蓄積・配布しています。
今回は高エネルギー物理学に特化したプレプリントのオープンソースサーバーである[INSPIRE-HEP](http://inspirehep.net)から論文の概要情報をクローリングし取得しました。INSPIRE-HEPではarXivに投稿された高エネルギー物理学の論文に、いくつかの背景情報を付与した上で、以下の概要情報を表示します。
論文の重要さを測る指標は様々ですが、「被引用数」は重要な指標と考えています。また、著名な研究者が書いた論文はどうしても注目され、被引用数は伸びることが考えられます。そこで今回は、総論文数の多い特定の一人の研究者に関して分析しました。これによって著者の影響が出ないようにしました。
今回調べたところ、存命でかつ最も論文数が多い研究者はJohn Ellis氏の1,083本(2019年1月1日時点)でした。John Ellis氏の最も被引用数の多い論文である「Supersymmetric Relics from the Big Bang」を例にとると、以下の図1のように赤く塗りつぶした部分を今回取得しています。
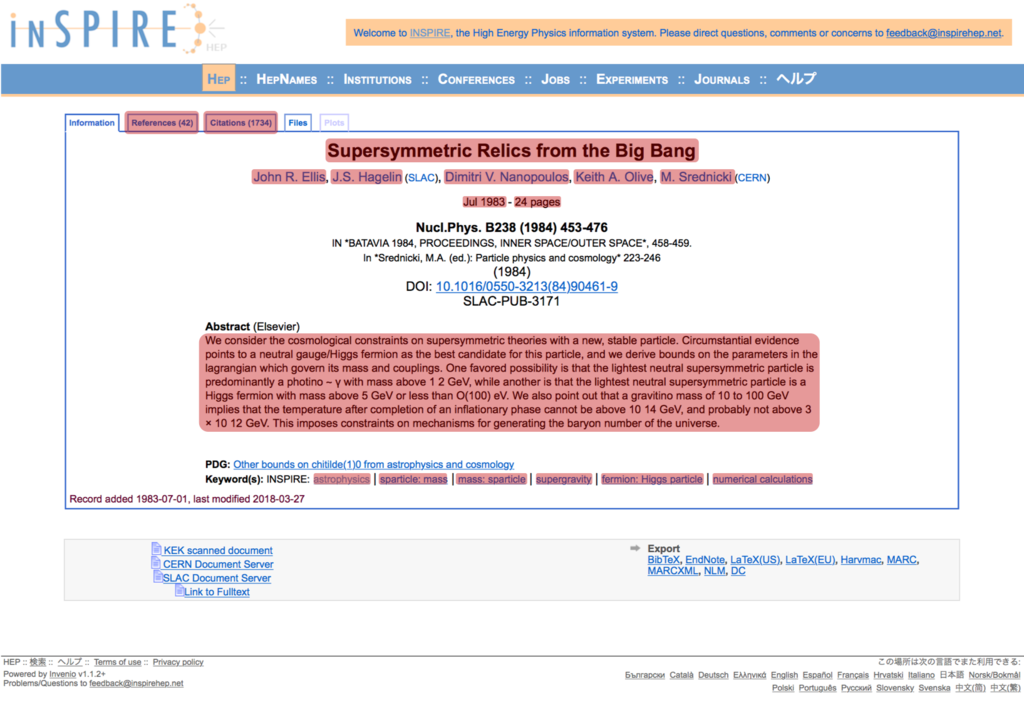
図1 : INSPIRE-HEPのページ例。赤く塗りつぶしている箇所を今回クローリングしている。
John Ellis氏の総論文1,083本に対して、同様の概要情報をINSPIRE-HEPからクローリングしました。今回は、1ページ取得するごとに十分な時間(5秒間隔、参考[1])を空けて、データの取得を行いました。
今回の取り組みでは、論文の重要度が予想できるかを確かめます。John Ellis氏の論文をモデル作成用:評価用=9:1に分割し、モデル作成用データで特徴量を作成した上で、評価用にも適用します。モデル作成はLightGBMで行い、評価用データで評価します。論文の重要度は、引用元の評価や引用年を利用せず、2019年1月時点での引用数としました。評価指標は、昔の論文でも最近の論文でも、評価指標の分布が大きく変わらないようにするため、下記式を用いました。
経過年数の長い論文の被引用数がどうしても伸びてしまうことを考慮して自然対数で割っています。ここで定めた評価指標を四分位に分割し、高い順に「秀」「優」「良」「可」としました。本分析では、この4クラスを目的変数としています。
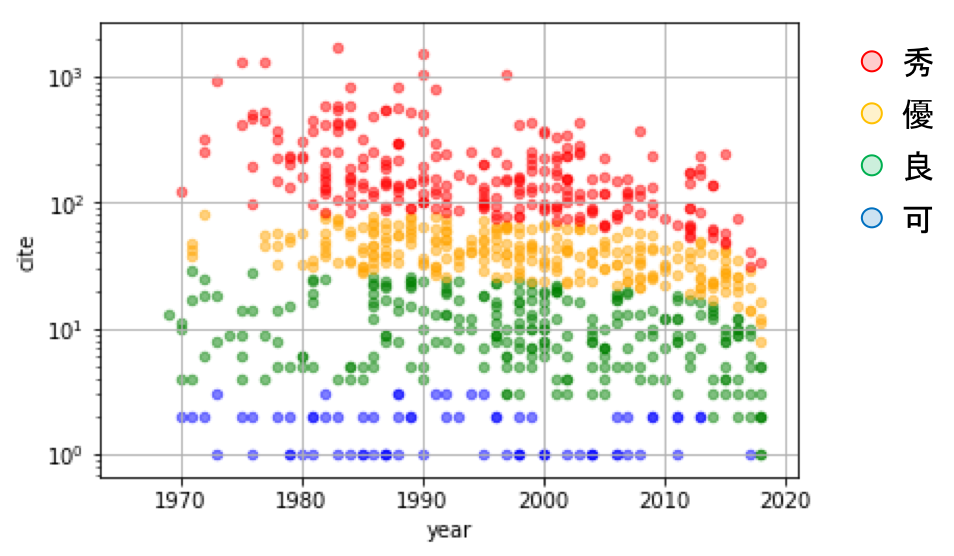
図2 : 被引用数と経過年数の関係。評価指標の高い順に「赤」「オレンジ」「緑」「青」でクラス分けしました。
上記図2では、被引用数を縦軸、発表年数を横軸として、John Ellis氏の個々の論文をプロットしています。色は評価クラスとなっており、「赤」「オレンジ」「緑」「青」はそれぞれ「秀」「優」「良」「可」となっています。ここで、過去の論文でも、最近の論文でも、評価値でおおよそ4分割出来ており、良さそうな指標となっています。
今回作成した特徴量は以下です。
以下では前処理の実施内容と、深層学習を使った自然言語処理であるDoc2VecとDANについて紹介します。
クローリングで取得してきたデータの前処理を行いました。具体的には以下の4つの前処理を行なっています。
共著者数が多い論文では、John Ellis氏自身はタイトルやアブストラクトを書かないでしょう。また実験の論文である可能性も高く(John Ellis氏は理論物理学者)、実験の論文は著者も被引用数も非常に多く、外れ値となります。そのため共著者数に上限を設けました。発表年の情報がない論文に関しても、分析の対象から除きました。この結果、分析対象は1,083件から1,007件になりました。ストップワードとは、a、the等の冠詞、at、of等の前置詞、I、He等の代名詞等、頻度が高い単語です。これも論文の特徴にはなり辛いため除外します。概要情報のソースはtexで書かれていますが、tex特有の記号も除外します。
また、データの配布元であるINSPIRE-HEPが付与しているkeywordsの項目をみると「TALK」や「Lecture」などプロシーディングスである事を読み取る事はできますが、
という2つの観点から分析対象から除くことをしていません。
1,007件のデータをモデルに学習させる訓練用のデータとモデルの精度を検証する評価用のデータに事前に分けました。それぞれのクラスのデータ数は以下の通りです。
| クラス | 訓練用のデータ | 評価用データ | 合計 |
| 秀 | 226 | 26 | 252 |
| 優 | 226 | 26 | 252 |
| 良 | 226 | 26 | 252 |
| 可 | 225 | 26 | 251 |
以降の学習には全てモデル作成用データのみを使用しています。また評価用データは学習済みモデルの評価のためだけに使用しています。データ分割は乱数を使っており、発表年などの情報に偏りがないことも確認しています。
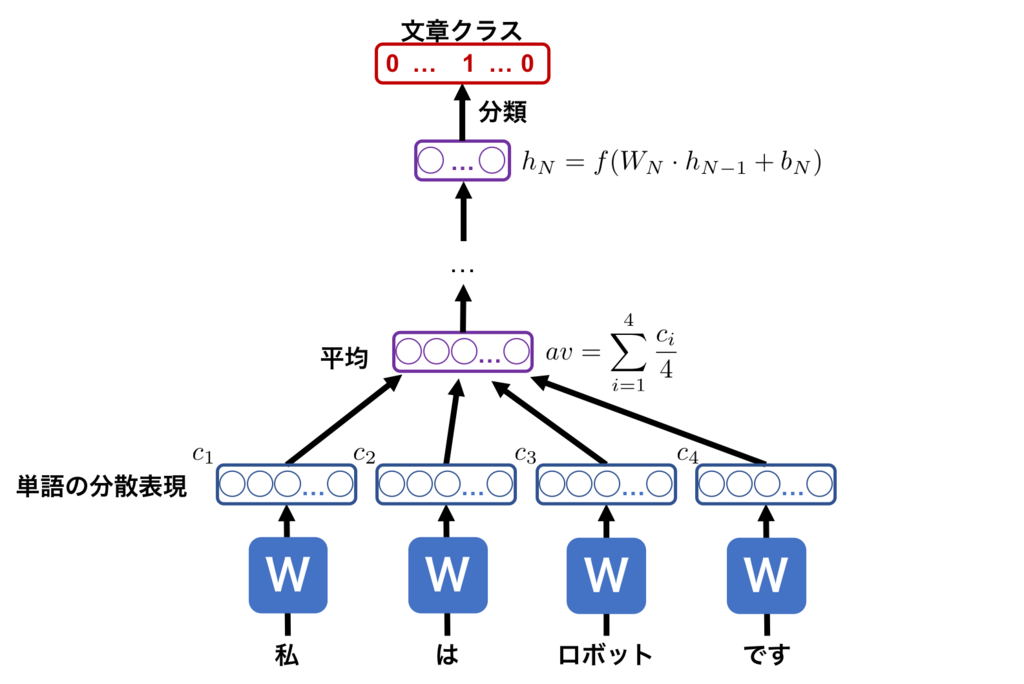
ここでは文・文章の分散表現を得るための著名な手法であるDoc2Vecを紹介します。自然言語処理に特化したモジュールであるgensimなどでDoc2Vecという名前で使われているためDoc2Vecとして知られていますが、原論文ではParagragh Vectorと呼んでいます。Word2Vecを開発したTomas Mikilov氏によって提案されたこともあり、基本的にはWord2Vecを文章単位に拡張した考え方から構成されています。論文でも
> Our approach for learning paragraph vectors is inspired by the methods for learning the word vectors.
と言ったような記述があります。論文中でDoc2Vecの学習方法には下記の2手法が提案されています。
今回は、PV-DMで英語版のwikipediaを学習させ、学習済みモデルから論文のアブストラクトの分散表現を得ました。また分散表現をt-SNEとk-meansを用いて10クラスに分類して特徴量としました。今回の分析の対象とはしませんが、文章間の分散表現同士のコサイン類似度を測定し近い文章を抽出することが可能です。
以下ではDoc2Vecのそれぞれの学習手法を説明します。
PV-DMでは、文書ベクトルと連続する単語ベクトルから、直後の単語を予測するように文書ベクトルを学習します。下記の様に学習ステップで4段階の学習を行い、推論ステップで新規文書に対する推論を行います。
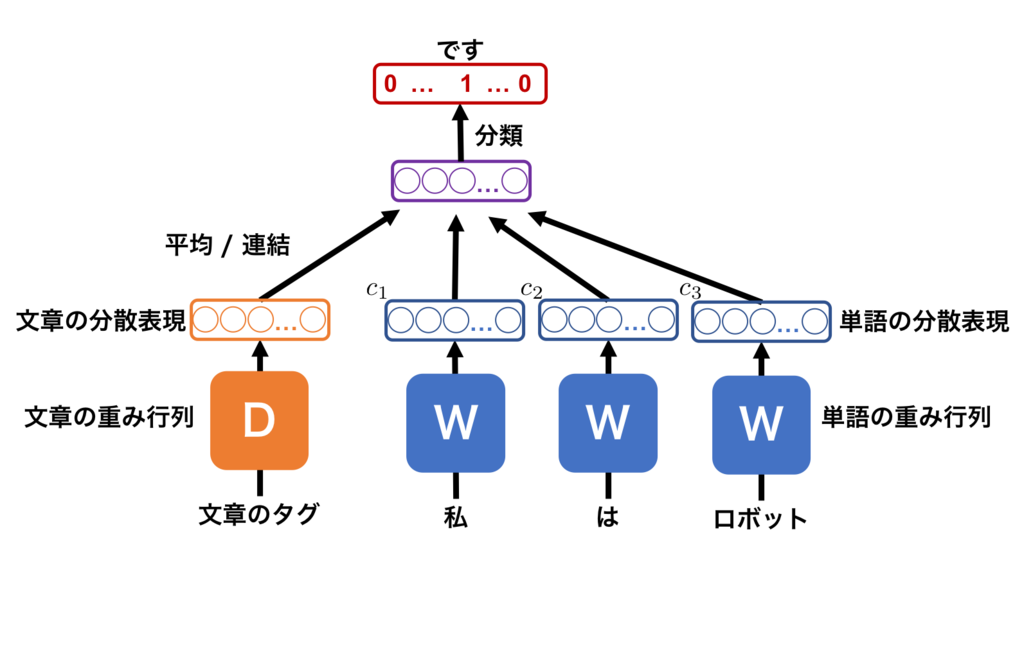
PV-DBOWでは、語順を無視した上で、文章に含まれる単語を当てるように文章ベクトルを学習します。この手法での文の分散表現化は、PV-DMよりも簡単ですが、精度は劣ると紹介されています。次の3ステップで分散表現化の学習を行い、これを4ステップ目で新規文章に適用します。
1. 学習
1. 同一文章から任意の個数の単語をサンプルしてくる
2. サンプルした単語を予測するように文章ベクトルと中間層→出力層の重みを最適化する。
文章行列の全体は行列Dですが、文章を特定するとベクトルとなります。
3. 学習が進むまで2を繰り返す。
2. 推論
新規の文に対して、中間層→出力層の重みを固定して、文章ベクトルを最適化します。学習の方法は下記図を参照してください。
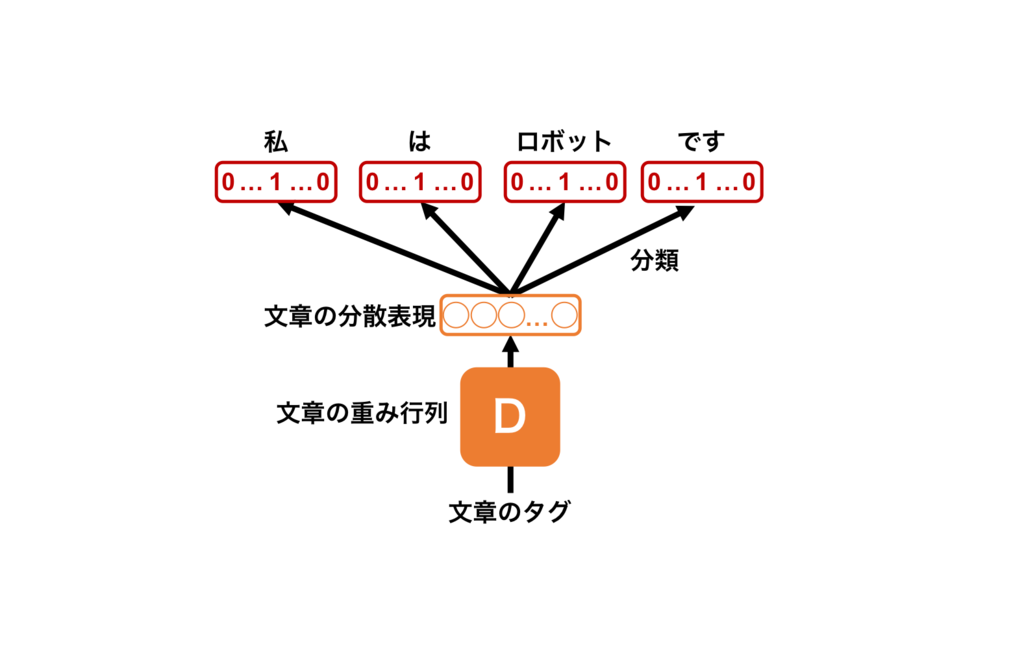
図4 : PV-DBOWの学習手順。上記の学習手順で学習をする。
PV-DBOWはPV-DMに対して単語の分散表現行列Wを要しないため、少ないメモリで学習することができるメリットがあります。PV-DMで得たベクトルは様々なタスクに対応できるのに対して、PV-DBOWで得たベクトルのみでは良い精度を出せない様です。そのため、PV-DBOWベクトル単独ではなく、PV-DMのベクトルと連結して使用するように論文では推奨されています。
DANは深層学習を用いた自然言語処理モデルで、文もしくは文章に対する文章分類や質疑応答システムで高い性能を発揮します。文法的な知識を使わないモデルであり、そのため学習にかかる時間は短くなっています。このモデルは、隠れ層を用意することと、ドロップアウトを利用することで精度が高くなります。文法的な知識を使う文法的な知識を使うモデル[4, 5, 6, 7]と比較して、構文的なばらつきが大きいデータでも高い精度となります。
また、DANでは文法知識を使うモデルと同様な間違いをおかすことが分かっています。これは、DANは文法を考えていないモデルですが、文法情報と同等の情報を、単語分散表現と中間層から取り込んでいる、ということでしょう。
分類タスクに対しては、モデルは図5の構成となります。
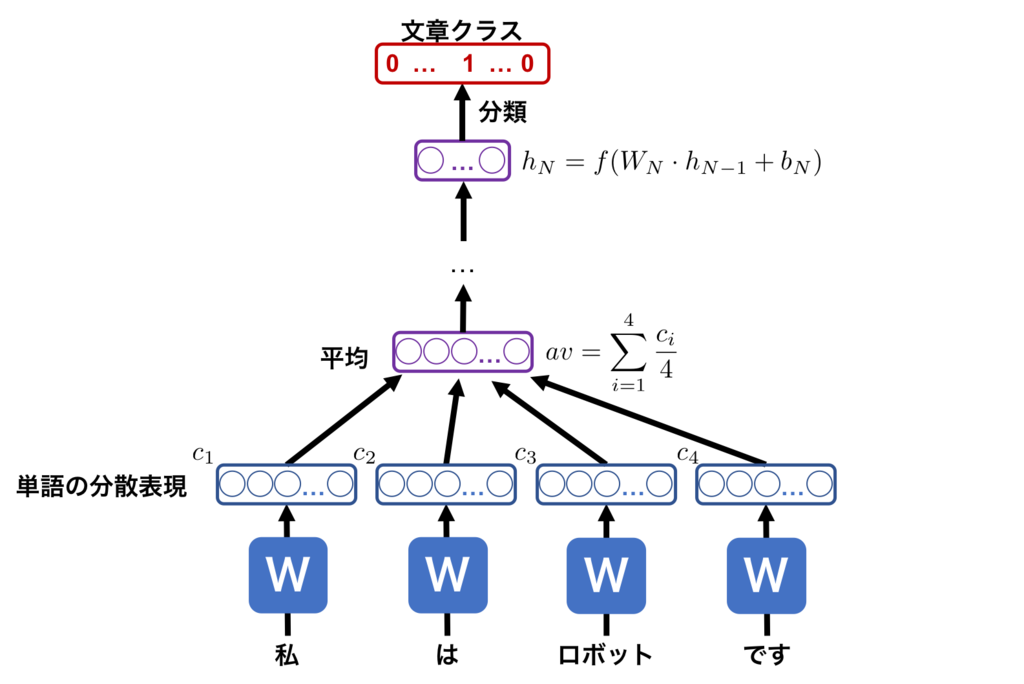
図5 : DANの学習手順。下記の学習手順で学習をする。
このモデルは、次の3ステップで機能します。
今回の分析ではGloVeでの学習済み分散表現リンクを使用し、単語分散表現の平均化を行いました。gensimでは以下の変換が必要です。
python -m gensim.scripts.glove2word2vec –input glove.840B.300d.txt –output glove.840B.300d.w2vformat.txt
変換した分散表現は非常に重く読み込みにも時間がかかるため、注意してください。
本分析では、論文のタイトルとアブストラクトの単語を入力しています。その際、平均化のための単語数が多すぎると文・文章ごとの差が現れにくくなってしまいます。一方、単語数が少なすぎても文・文章の特徴を捉えにくくなってしまいます。そのため本分析では平均化する単語数に上限を設けました。上限を超える単語数の文では、対象の文から乱数を用いて、利用する単語を決めました。本分析では4クラスの多値分類を行うため、DANの最終層はsoftmaxを利用してます。
目的変数と特徴量の作成の章の通り、単純集計の結果以外に、単語分散表現や深層学習モデルを利用して特徴量を作成します。深層学習モデルの内DANについては、DANでの予測確率を最終的な学習器として用いるLightGBMの変数とします。式(1)で定義した評価指標のクラスを目的変数として多値分類を行います。本章ではDANの学習結果と最終的なLightGBMでの学習結果を紹介します。
まず、DANモデルでの予測結果を紹介します。タイトルとアブストラクトの単語分散表現を平均化したベクトルを元に、3層の中間層を通して、softmaxで多値分類を行います。DANモデルのみで高い精度を出すことが出来ています。
今回モデルとしては以下のようなパラメータセットを使用しました。原論文で言及されているパラメータセットを参考に、一部調整しています。
| 活性化関数 | ReLU |
| 層数 | 5 |
| ドロップアウト | 0.4 |
| 正則化 | L2正則化(1e-5) |
| 最適化アルゴリズム | Adam |
| 学習率 | 2.5e-5 |
| 損失関数 | categorical_crossentropy |
| 総エポック数 | 1,000 |
| 入力単語の分散表現次元数 | 300次元 |
| 単語数の上限 | 80 |
モデルはkerasを使って構築しました。中間層は徐々に次元を小さく圧縮して、重要な情報のみを取り出せるよう工夫しています。
from keras.layers import Input, Dense, Dropout
from keras.models import Model
from keras.optimizers import Adam
from keras import regularizers
def dan_model(model_glove):
# This returns a tensor
inputs = Input(shape=(model_glove.vector_size, ))
# a layer instance is callable on a tensor, and returns a tensor
x = Dropout(0.4)(inputs)
x = Dense(250, kernel_regularizer=regularizers.l2(1e-5), activation=’relu’)(x)
x = Dense(200, kernel_regularizer=regularizers.l2(1e-5), activation=’relu’)(x)
x = Dense(100, kernel_regularizer=regularizers.l2(1e-5), activation=’relu’)(x)
x = Dense(50, kernel_regularizer=regularizers.l2(1e-5), activation=’relu’)(x)
x = Dense(10, kernel_regularizer=regularizers.l2(1e-5), activation=’relu’)(x)
x = Dropout(0.4)(x)
predictions = Dense(4, activation=’softmax’)(x)
model = Model(inputs=inputs, outputs=predictions)
model.compile(
optimizer=Adam(lr=2.5e-5),
loss=’categorical_crossentropy’,
metrics=[‘accuracy’])
return model
単語の分散表現を得るための関数を以下のように定義しました。
import gensim
import numpy as np
model_glove = gensim.models.keyedvectors.Word2VecKeyedVectors.load_word2vec_format(‘path/to/glove.840B.300d.w2vformat.txt’)
def my_word2vec(word, model_glove):
try:
vec = model_glove[word]
except:
vec = [0.] * model_glove.vector_size
return np.array(vec)
この関数を使用して分散表現の平均化は
def sampling_ave(word_list, model_glove, sample_size=80):
sum_vec = np.zeros(model_glove.vector_size)
if len(word_list) > sample_size – 1:
word_list = np.random.choice(word_list, sample_size, replace=False)
for word in word_list:
sum_vec += my_word2vec(word, model_glove)
ave_vec = sum_vec / len(word_list)
return ave_vec
と定義して学習させました。このベクトル平均化の関数は、タイトルクラスを求める際のタイトル単語の平均化でも使用しています。
今回構築したモデルでは、普段業務で使用しているノートパソコンで学習が10分弱しか掛かっていません。上記にもあるように、モデル構造が非常にシンプルで計算コストがかからない点が最大の長所であると思います。
学習曲線は以下のようになりなりました。少々過学習が起こり始めていますが、 `val_loss` が最小の時の重みを保存しているので720エポックの値をモデルとして採用しています。
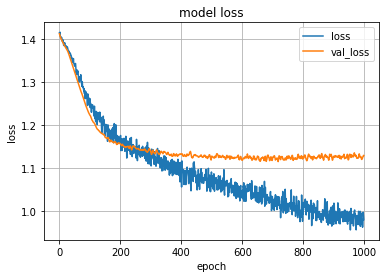
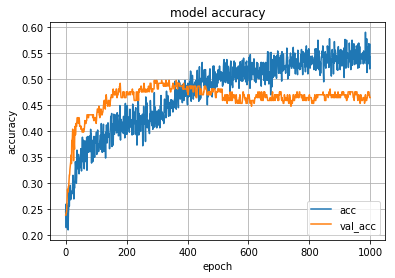
図6 : 左図は損失関数の値とエポック数、右図は精度とエポック数
DANのみでの学習では、評価用データの混同行列は以下のようになりました。
| 真値 予測値 | 可 | 良 | 優 | 秀 |
| 可 | 19 | 1 | 3 | 3 |
| 良 | 6 | 3 | 9 | 8 |
| 優 | 0 | 1 | 11 | 14 |
| 秀 | 0 | 2 | 5 | 19 |
今回は4クラスに均等にデータを分配しているため、完全にランダムで予測すると正答率は25%のはずです。一方、DANモデル単体では正答率が50%程度になりました。タイトルとアブストラクトの単語の情報のみ、かつノートパソコンによる10分程度の学習としては良い結果が得られたと考えています。
今回、平均化する単語数の上限を80単語に限定しましたが、タイトルとアブストラクトは論文全体の情報が短い文にまとめられており、DANモデルに適したタスクでした。DANモデルでは、含まれる単語の分散表現を平均化するため、特徴は微小となります。そのため、長い文章(極端な例だと、1冊の本)はDANモデルに適さないと考えています。
さらに、2019年1月10日にJohn Ellis氏の[1,084本目の論文](http://inspirehep.net/record/1713396)が報告されました。
学習済みのDANで予測した結果は
array([[0.03076923, 0.15278426, 0.40129492, 0.4151516 ]], dtype=float32)
左から `[‘可’, ‘良’, ‘優’, ‘秀’]` の確率を指し、最も評価用データの正答率も高い「秀」クラスの確率が最も高くなりました。今後どうなるのか楽しみです。
LightGBMに入力する特徴量は137個になりました。学習のための主要なパラメータは以下の表の通りです。
| パラメータ | 内容 |
|---|---|
| min_data_in_leaf | 90 |
| max_depth | 3 |
| learning_rate | 0.01 |
| lambda_l1 | 0.1 |
| lambda_l2 | 0.3 |
| n_estimators | 200 |
最終的なLightGBMを用いた学習での評価用データの混同行列は以下のようになりました。
| 真値予測値 | 可 | 良 | 優 | 秀 |
| 可 | 19 | 4 | 3 | 0 |
| 良 | 6 | 12 | 4 | 4 |
| 優 | 0 | 7 | 11 | 8 |
| 秀 | 0 | 3 | 9 | 14 |
DANモデルでは、タイトルとアブストラクトの単語分散表現の平均ベクトルのみを使ったのに対して、LightGBMのモデルでは独立な情報が追加されています。そのためDANモデルから精度の向上が見られます。混同行列から計算される精度(overall accuracy)は0.5から0.54に改善しています。特に、DANモデルで精度のあまり高くなかった『良』『優』クラスの精度が向上しているのがわかりました。 今回の分析では、多値分類を行っているためmulticlassを利用しています。そのため、順序の効果は特に考慮されていません。しかし間違った予想の場合でも隣り合うクラスが多く、『可』と『秀』の間での誤答はありませんでした(図7)。
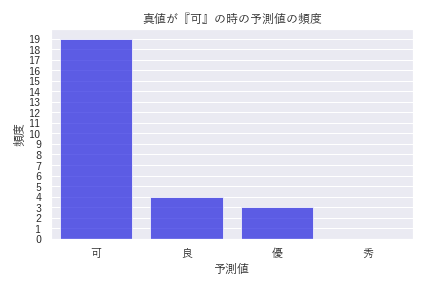
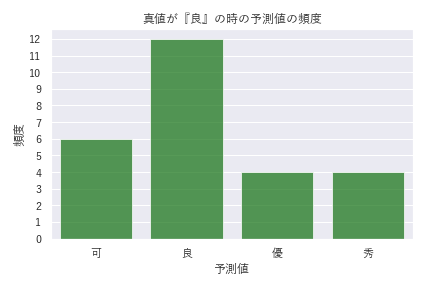
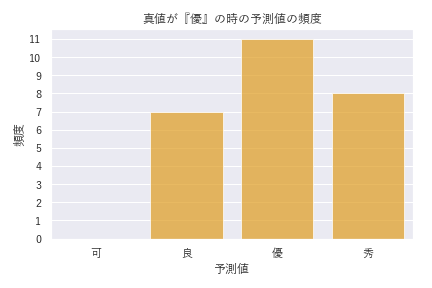
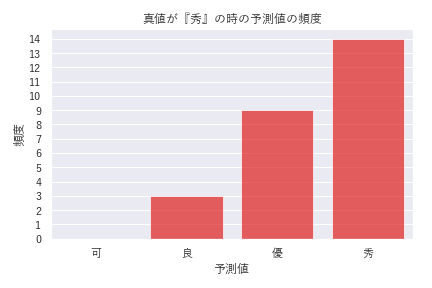
図7 : 左から評価データの真値が「可・良・優・秀」であるときのモデルの予測値
自然言語処理技術には、本ブログで紹介した論文の質の予測以外でも様々な活用方法があり、世の中の注目を集めています。例えば、総務省が組織する次世代人工知能社会実装WGでは、我が国の自然言語処理技術の現状が言及されています[8]。
> 我が国においても、総務省、文部科学省、経済産業省が連携し、人工知能技術の研究開発を推進していくことが示されるとともに、様々な民間企業が、自然言語処理を含む様々なサービスを市場に投入・展開しつつある状況。
また、下記のように自然言語処理技術の活用に言及があります。
> 我が国ならではの社会課題の解決や社会貢献を目的とした自然言語処理アプリケーションの開発に取り組むことが有効と考えられ、本WGでは、特に医療、防災、対話や翻訳等の生活支援等の分野に着目した。
現在、ブレインパッドの研究開発チームで研究を行なっている文書間の類似度も、病気の症例や裁判の判例、技術書類の検索などに活用することができると考えています。実際に、自然言語技術を使って質問者が知りたい内容を推測して候補となる症例や論文を提示する他社の事例もあります[9]。さらに、本ブログで扱ったDANは質問応答システムと親和性が高く、世界でも有力なクイズプレイヤーに早押しクイズで勝利(Studio Ousia社)した自然言語処理技術はチャットボットなどにも応用されています[10]。
今回の取り組みでは、論文の重要度が予想できるかを確かめました。取り組むにあたり
を説明しました。被引用論文数と発表年を元に作成した4クラスを予測しました。その結果、評価用データに対し0.54の精度を達成できました。一定の精度で論文の重要度を予測することはできたと考えています。
また、今回は研究開発を通して得た知見を活かした個人的な取り組みをご紹介しましたが、弊社ではこのような積極的な課外活動が推奨されています。最近では「MSゴシック絶対許さないマン」や「オフトゥンフライングシステム」など面白い活動が生まれてきています。このような自分磨きの時間が推奨されていることは、データサイエンティストとして非常にありがたい環境だと感じています。
本ブログに限らず、弊社には勉強会や社内プロジェクトなど、お客様への分析サービスの提供以外にも個人のスキルアップを支援する様々な活動があります。これらの取り組みに「面白いことができる会社なんだな」と思っていただけたら幸いです。
1 [岡崎市立中央図書館事件](https://ja.wikipedia.org/wiki/岡崎市立中央図書館事件)
2 原論文 : [Distributed Representations of Sentences and Documents](https://arxiv.org/abs/1405.4053v2) / Tomas Mikolov
3 原論文 : [Deep Unordered Composition Rivals Syntactic Methods for Text Classification](http://www.aclweb.org/anthology/P15-1162) / Nohit Iyyer, Varun Manjunatha, Jordan Boyd-Graber, Hal Daume III
4 Sepp Hochreiter and Ju ̈rgen Schmidhuber. 1997. Long short-term memory. Neural computation.
5 Kyunghyun Cho, Bart van Merrienboer, Caglar Gulcehre, Fethi Bougares, Holger Schwenk, and Yoshua Bengio. 2014. Learning phrase representations using rnn encoder-decoder for statistical machine translation. In Proceedings of Empirical Methods in Natural Language Processing.
6 Ilya Sutskever, Oriol Vinyals, and Quoc VV Le. 2014. Sequence to sequence learning with neural networks. In Proceedings of Advances in Neural Information Processing Systems.
7 Kai Sheng Tai, Richard Socher, and Christopher D. Manning. 2015. Improved semantic representations from tree-structured long short-term memory networks.
8 総務省, 「次世代人工知能社会実装WG 報告書(案)」2017.5.30, <http://www.soumu.go.jp/main_content/000492170.pdf>
9 日経BP社, 2018, AI・IoT・ビッグデータ総覧2019-2019, pp.4-16
10 [Studio OusiaのAIがクイズチャンピオン達と対戦し勝利](https://www.qaengine.ai/articles/studio-ousia-vs-ai-champions/)
—
ブレインパッドは、さまざまな取り組みを積極的に実施しています。実際のビジネスで自分の知識・技術を活用してみたいという方、ぜひエントリーください![http://www.brainpad.co.jp/recruit/:embed:cite]
あなたにオススメの記事

2023.12.01
生成AI(ジェネレーティブAI)とは?ChatGPTとの違いや仕組み・種類・活用事例

2023.09.21
DX(デジタルトランスフォーメーション)とは?今さら聞けない意味・定義を分かりやすく解説【2024年最新】

2023.11.24
【現役社員が解説】データサイエンティストとは?仕事内容やAI・DX時代に必要なスキル

2023.09.08
DX事例26選:6つの業界別に紹介~有名企業はどんなDXをやっている?~【2024年最新版】

2023.08.23
LLM(大規模言語モデル)とは?生成AIとの違いや活用事例・課題

2024.03.22
生成AIの評価指標・ベンチマークとそれらに関連する問題点や限界を解説













