



ブレインパッドは、LLM/Generative AIに関する研究プロジェクトを立ち上げ、この「Platinum Data Blog」を通じてLLM/Generative AIに関するさまざまな情報を発信をしています。
今回は、LLMの学習・推論の高速化・効率化をテーマに3つの論文をご紹介します。
今回は、LLMの学習・推論の高速化・効率化をテーマに3つの論文をご紹介します。
テーマから探す
技術から探す
業界・事例から探す
関連トレンドから探す

こんにちは、アナリティクスコンサルティングユニット所属の金です。
前回の記事にもあるように、現在ブレインパッドではLLM関連の論文の調査を行っています(LLM論文レビュー会)。
今回は、その中でも、LLMの学習・推論の高速化・効率化のトピックで取り上げた3つの論文についてご紹介します。
【生成AI・LLM解説記事】
生成AI(ジェネレーティブAI)とは?ChatGPTとの違いや仕組み・種類・活用事例
LLM(大規模言語モデル)とは?生成AIとの違いや活用事例・課題
LLMの学習や推論の高速化・効率化に関する論文をご紹介させていただきます。
近年、自然言語処理タスクにおける大規模言語モデル(LLM)の進歩が著しい一方で、その大きなサイズと計算要求は、リソース制約のある環境での導入に課題を生じさせています。これに対応するため、モデル圧縮技術の重要性が高まっています。
この背景を考慮した上で本論文を選定しました。特に、現代の技術環境において、エッジデバイスやモバイルデバイスでのAIモデルの適用が増加している中、モデルの効率的な展開が不可欠となっています。
モデル圧縮技術は、これらのデバイス上での高品質なモデルの実行を可能にする鍵となるため、その最新の研究動向や技術を深く理解することは、今後の技術開発や適用において極めて価値があると判断しました。
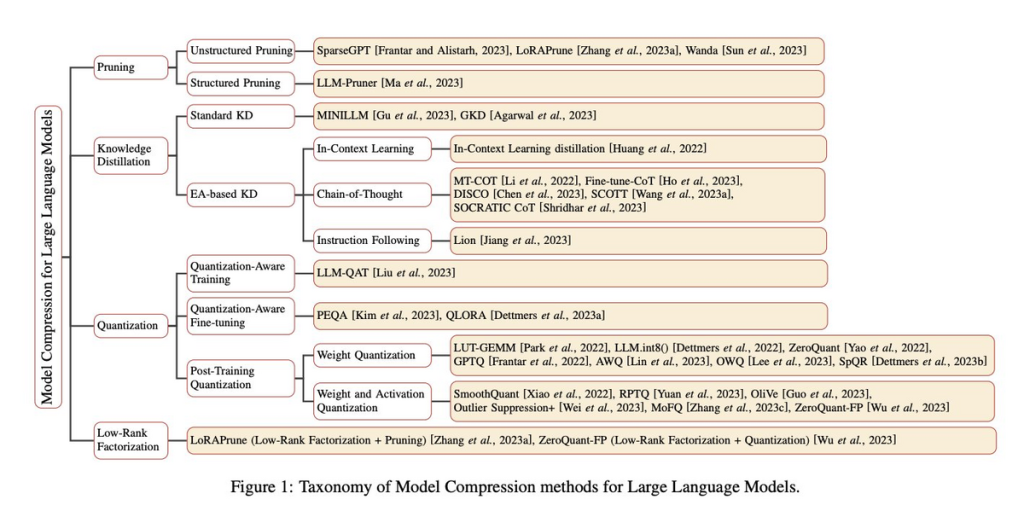
– 大規模言語モデル(LLM)のモデルサイズと計算コストの増加に伴い、モデルの圧縮技術が重要となっている
– プルーニング、知識蒸留、量子化、低ランク因子分解など、さまざまな圧縮技術が提案されている
– 論文は、LLMに焦点を当てた圧縮技術の分類のフレームワークを提供している
本論文は、大規模言語モデルのモデル圧縮技術に焦点を当てたサーベイ論文となっています。
モデル圧縮とは、モデルのサイズや計算コストを効果的に削減しつつ、性能を維持または向上させるための技術のことを指します。
論文内では、各圧縮技術の基本的な概念や、それらがLLMのサイズと計算コストをどのように削減するのか、さらには各技術の特性や課題について詳細に解説されています。
このサーベイ論文は各手法を包括的に解説していますが、すべてのアプローチを詳しく説明するのは範囲を超えていますので、紹介されている手法を表で整理しました。
詳細に興味を持たれた手法がございましたら、本論文を直接参照していただければと思います。
| 手法(英語名) | 特徴 | 種類 |
|---|---|---|
| プルーニング(Pruning) | モデルの重みの中で重要度が低いものを削除することで、モデルのサイズを小さくする技術 | ・非構造化プルーニング(Unstructured Pruning):個々の重みやニューロンをモデルの構造を考慮せずにターゲットとする方法(e.g. SparseGPT、LoRAPrune) ・構造化プルーニング(Structured Pruning):ニューロンやレイヤーなどの全体的な構造要素を削除する方法(e.g. LLM-Pruner) |
| 知識蒸留(Knowledge Distillation;KD) | 複雑な「教師」モデルからシンプルな「生徒」モデルへ知識を移転する技術 | ・標準的な知識蒸留(Standard KD):生徒モデルにLLMが持つ共通の知識、例えば出力分布や特徴情報などを転移する方法 ・Emergent Abilities-based KD:生徒モデルにLLMのユニークな振る舞いや能力を転移する方法 |
| 量子化(Quantization) | 浮動小数点数を整数や他の離散形式に変換することで、モデルのストレージと計算のオーバーヘッドを軽減する技術 | ・Quantization-Aware Training(QAT):モデルのトレーニングプロセス中に量子化を適用する方法 ・Quantization-Aware Fine-tuning(QAF):事前トレーニングされたモデルの微調整中に量子化を適用する方法 ・Post-Training Quantization(PRQ):モデルがトレーニングを完了した後に量子化を適用する方法 |
| 低ランク因数分解(Low-Rank Factorization) | 与えられた重み行列を2つ以上の小さな行列に分解することでモデルを圧縮する技術 |
大規模言語モデル(LLM)の圧縮技術は急速に進展していますが、多くの課題と未来の方向性が存在します。より進んだ圧縮方法の必要性、性能とサイズの間のトレードオフ、動的な圧縮方法の探求、そして圧縮技術の説明可能性など、多岐にわたる課題が浮き彫りになっています。以下の表は、これらの主要な課題と方向性を概観するものです。
| カテゴリ | 主な課題・方向性 |
|---|---|
| より進んだ圧縮方法の必要性 | ・LLMのモデル圧縮技術の研究はまだ初期段階である ・圧縮されたLLMは、非圧縮のLLMと比較して、まだ大きな性能のギャップを示している ・LLMのためのより進んだモデル圧縮方法に深く取り組むことで、非圧縮LLMの性能を向上させる可能性がある |
| 性能・サイズのトレードオフ | ・LLMの性能とモデルサイズの間の微妙なバランスが以前の研究で強調されている ・このトレードオフを分析することで、ハードウェアの制約内での最適な性能を実現する ・現在の研究は、このトレードオフに関する理論的および経験的な洞察に欠けている |
| 動的LLM圧縮の探求 | ・現在の圧縮方法の進歩にもかかわらず、まだLLMの圧縮サイズと構造を決定するための手動設計に依存している ・入力データやタスク要件に基づいて試行錯誤のアプローチを採用することが多い ・手動の努力は、実用的な障壁を提示する |
| 圧縮技術の説明可能性 | ・ 以前の研究では、言語モデルを小さくする技術が「どのように動作するのか」を説明するのが難しいと指摘されていた ・例えば、ある技術がどうやって良い結果を出しているのかの説明が不足している ・この「説明の難しさ」は、モデルを実際に使う際の信頼性や予測の正確さに影響を与える可能性があるため、圧縮技術を使う際には、それがどのように動作するのかを理解しやすくすることが重要である |
Q: 圧縮技術を適用した結果、特定の分野での性能が低下することはあるか?それとも、全体的に性能が悪化する傾向にあるか?
– 論文によれば、モデルのサイズと性能の間にはトレードオフが存在します。量子化などの圧縮技術を適用することで、わずかな精度の低下が生じる可能性が示されています。
一方で、圧縮技術を適用した後の特定の分野での性能低下に関する具体的なケースの記述は見当たりませんでした。
| タイトル | 概要 |
|---|---|
| A Survey of Quantization Methods for Efficient Neural Network Inference | 紹介された手法の一つである量子化手法に関するサーベイ論文。基本的な手法から応用手法までを幅広くサーベイしています。 |
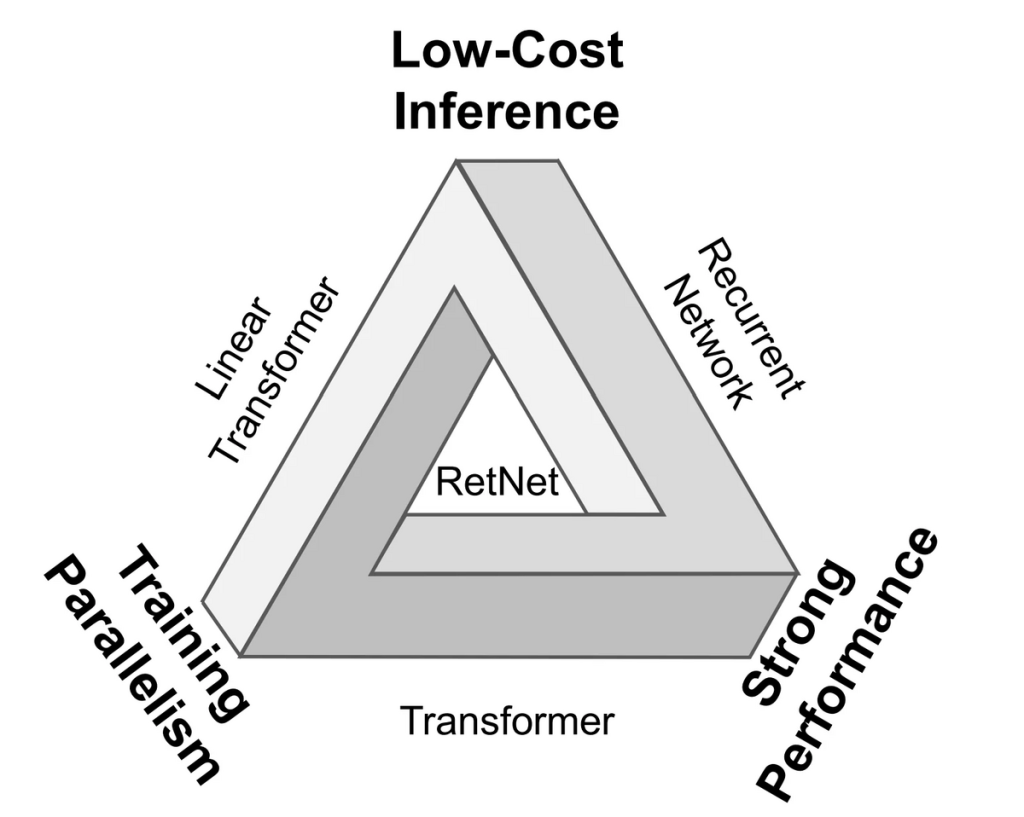
Transformerは、機械翻訳、文章生成、質問応答などの多くのNLPタスクで革命的な成功を収めてきました。しかし、長いシーケンスの処理に関するメモリと計算の制約や、トレーニングと推論のコストの問題など、いくつかの制約も明らかになってきました。この論文は、これらの制約に対する新しいアプローチとしてRetNetを紹介しており、その点で非常に興味深いと感じました。
– RetNetは、トランスフォーマーの効率性の問題を解決するための新しいアーキテクチャとして提案されている
– 並列、再帰、およびチャンクごとの再帰の3つの計算パラダイムを提供し、効率的なトレーニングと推論を可能にする
– 実験結果は、RetNetが特定のシナリオでトランスフォーマーよりも優れている可能性があることを示唆している
本論文では、大規模言語モデルの基盤として**RetNet**という新しいアーキテクチャが紹介されています。
RetNetの目的は、学習においての並列性、推論においての低コスト、および良好な性能を達成することです。再帰性(recurrence)とアテンション(attention)の間の関連性を導き出し、シーケンスモデリングのための保持メカニズム(retention mechanism)を導入しています。このアーキテクチャは、並列、再帰、チャンクごとの再帰(chunkwise recurrent)の3つの計算パラダイムをサポートしており、多尺度の保持メカニズム(multi-scale retention mechanism)を導入してトランスフォーマーとの主な違いを持っています。
言語モデリングの実験を通じて、モデルのサイズが2Bより大きい場合、RetNetがトランスフォーマーよりも優れている可能性があることが示されています。
近年、NLPの分野でのブレークスルーは、Transformerアーキテクチャの登場によってもたらされました。しかし、その成功にもかかわらず、Transformerにはいくつかの制約が存在します。この制約を克服し、さらなる進化を遂げるための新しいアーキテクチャ、**RetNet**が提案されました。
Transformerの既存の制約と、RetNetがそれをどのように克服したのかを以下にまとめました。
Transformerの制限:
1. 推論の非効率性: ステップごとのO(N)の複雑さにより、シーケンスが長くなると推論速度が低下
2. キー値キャッシュの問題: シーケンスの長さが増加すると、GPUメモリの消費が増加し、レイテンシが増加し、全体的な推論速度が低下
RetNetの特徴:
1. 効率的なO(1)の推論: 再帰的な表現を導入することで、メモリと計算の観点から効率的な推論を実現。これにより、デプロイメントのコストとレイテンシが大幅に削減
2. 長いシーケンスのモデリング: チャンクごとの再帰的な表現を導入することで、各ローカルブロックを並列にエンコードし、グローバルブロックを再帰的にエンコードして、効率的な長いシーケンスのモデリングを実現
3. multi-scale retention mechanism: multi-head attentionの代わりに採用し、parallel、recurrent、chunkwise recurrentの3つの計算パラダイムをサポート

論文では、RetNetがさまざまな軸においてTransformerに優位を示しました。このセクションでは、その具体的な性能比較の結果を紹介します。
Perplexity比較
[f:id:bp-writer:20230925050657p:plain]
RetNetはin-domainの検証セット(モデルが主にトレーニングされたデータセット)と他のout-of-domainのコーパス(モデルがトレーニングされていない異なるデータセット)でのperplexityで他のモデルを上回っています。特に、RetNetはin-domainだけでなく、いくつかのout-of-domainのデータセットでも低いperplexityを達成しています。
また、トレーニングと推論の効率に関して、RetNetは先行研究であるRWKVやHyenaと比較しても効率的であり、特に大きなモデルサイズやシーケンスの長さにおいても効率的に動作します。推論時の複雑さも、他のアーキテクチャと比較して競争力があります。
トレーニングコスト
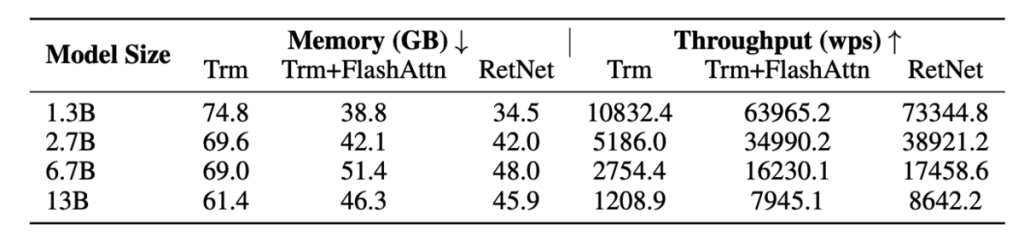
上記の表において、TransformerとRetNetのトレーニング速度とメモリ消費が比較されています。
実験結果から、RetNetはTransformerよりもメモリ効率が良く、スループットも高いことが示されています。FlashAttentionと比較しても、RetNetは速度とメモリコストの面で競争力があります。特に、特定のカーネルに依存せずに他のプラットフォームでのトレーニングが容易であり、さらなる最適化の可能性があることが注目されます。
推論コスト
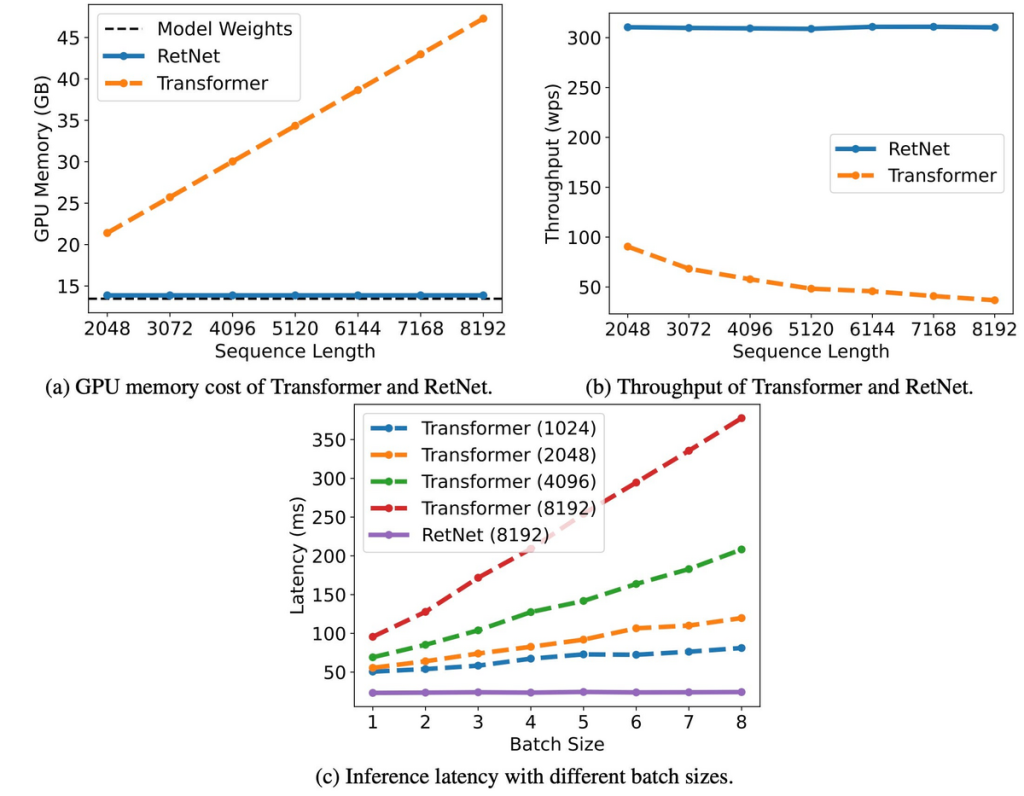
6.7Bのモデルサイズを持つRetNetとTransformerを比較すると、以下の点でRetNetが上回る性能を示しています。
– (a) GPUメモリコスト: RetNetとTransformerのメモリ消費を比較。TransformerのメモリコストはKVキャッシュのために増加しますが、RetNetは長いシーケンスでも一定のメモリ消費を保ちます。RetNetの追加のメモリ消費は約3%で、モデルの重みが主なメモリ使用量を占めます。
– (b) スループット: RetNetとTransformerのスループットを比較。Transformerのスループットはデコードの長さが増加するにつれて低下します。一方、RetNetはデコード中に一定の高いスループットを維持します。
– (c) 異なるバッチサイズでの推論レイテンシ: バッチサイズや入力長が増加すると、Transformerのレイテンシは増加します。しかし、RetNetは異なるバッチサイズや入力長にわたって安定したレイテンシを示します。
| タイトル | 概要 |
|---|---|
| RWKV: Reinventing RNNs for the Transformer Era | この論文では、Transformerの時代にRNNを再考するアプローチについて述べられています。RWKVは、トークンの混合の複雑さを介してトレーニングのFLOPSを削減する方法として紹介されています。 |
| Hyena Hierarchy: Towards Larger Convolutional Language Models | Hyenaは、Fast Fourier Transformの加速を使用してO(dn log n)の複雑さでトレーニングを行う方法として紹介されています。この論文では、より大きな畳み込み言語モデルに向けたアプローチについて説明されています。 |
この論文は、Rotary Position Embeddings(RoPE)を使用したトランスフォーマーベースのモデルの文脈ウィンドウを拡張するための新しい手法「YaRN」を紹介しています。この手法は、言語モデルの一般化能力を向上させる可能性があります。
– YaRN(Yet another RoPE extensioN method)は、RoPE(Rotary Position Embeddings)を使用した大規模言語モデルの文脈ウィンドウを効率的に拡張する新しい方法を提案
– 既存の方法よりも10倍少ないトークンと2.5倍少ないトレーニングステップで文脈ウィンドウを拡張
本論文では、大規模言語モデルの文脈ウィンドウを拡張するための新しい手法「YaRN(Yet another RoPE extensioN method)」が紹介されます。この手法は、Rotary Position Embeddings(RoPE)を基盤としており、従来の方法と比較して顕著な効率性を持っています。
Rotary Position Embeddings(RoPE)は、トランスフォーマーベースのモデルにおいてトークンの位置情報を効果的にエンコードするための手法です。従来の位置エンコーディングとは異なり、RoPEは位置情報を回転させることでエンコードし、モデルのスケーラビリティと一般性を向上させます。
YaRNの拡張手法は、RoPEの特性を活かしつつ、文脈ウィンドウを効率的に拡張するための方法を提供します。具体的には、10倍少ないトークンと2.5倍少ないトレーニングステップで文脈ウィンドウを拡張することが可能です。この結果は、大規模なデータセットでのトレーニングの効率性を大幅に向上させるものとして注目されています。
この研究は、自然言語処理の分野における大規模言語モデルの文脈ウィンドウ拡張技術の新たな方向性を示しており、今後の研究や実用化において重要な参考となるでしょう。
大規模言語モデルは、トランスフォーマーベースのモデルにおいてトークンの位置情報をエンコードするためのRotary Position Embeddings(RoPE)を使用しています。しかし、これらのモデルは、トレーニング中に見られる文脈ウィンドウの長さを超えて一般化するのが難しいという問題があります。既存の方法、特にPosition Interpolation (PI)は、すべてのRoPE次元を均等に伸ばすことでこの問題を解決しようとしていますが、理論的な補間境界が不十分であることが示されています。
1. “NTK-aware” 補間:
「NTK-aware」補間は、RoPEの埋め込みを補間する際の高周波情報の損失の問題を解決するために開発されました。この手法は、高周波を少なく、低周波を多くスケーリングすることで、複数の次元にわたって補間の圧力を分散させます。また、すべてのRoPE次元を等しくスケーリングする代わりに、特定の変換を行うことでこの補間を実現しています。
2. “NTK-by-parts” 補間:
「NTK-by-parts」補間は、RoPE埋め込みの中で、事前トレーニング中に見られる最大の文脈長よりも波長が長いいくつかの次元が存在するという観察に基づいています。この手法は、一部の次元が他の次元とは異なる方法でネットワークによって扱われていることを考慮しています。具体的には、波長が文脈サイズよりも小さい場合は補間せず、波長が文脈サイズと等しいかそれ以上の場合は、外挿を避けるためにのみ補間を行います。
「PI」と「NTK-aware」補間は、Rotary Position Embeddings(RoPE)の隠れた次元を一律に扱うアプローチを採用しています。これは、すべての次元が同じようにモデルに影響を与えるという前提に基づいています。
しかし、実験的な結果から、ネットワークは一部の次元を他の次元とは異なる方法で解釈・利用していることが示されています。これは、特定の次元がモデルの学習や予測において他の次元よりも重要な役割を果たしている可能性があることを示しています。
この観察は、提案された手法がまだ最適な状態にはないという指摘として捉えられます。そのため、これらの特定の次元を適切に扱うための最適化や改良が今後の研究の方向性として考えられます。
Q. RoPEの導入によってコンテキスト長を拡張する能力は向上したのですか、それともNTK補完の導入によるものですか?
「コンテキスト長を長くする」能力は、RoPEとNTK補完の組み合わせに起因しています。RoPEは、トランスフォーマーベースのモデルにおいてトークンの位置情報を効果的にエンコードする手法として導入されました。しかし、RoPEだけでは、トレーニング中に見られる文脈ウィンドウの長さを超えて一般化するのが難しいという問題がありました。
ここでNTK補完が役立ちます。NTK補完は、RoPEの埋め込みを補間する際の高周波情報の損失の問題を解決するために開発されました。これにより、RoPEの持つ文脈ウィンドウの制約を効果的に拡張することが可能となりました。
したがって、YaRNの主張としては、RoPEの持つ問題点をNTK補完で解決し、文脈ウィンドウを効果的に拡張することが強調されています。
| タイトル | 概要 |
|---|---|
| Rotary Position Embedding | RoPEは、トランスフォーマーベースのモデルにおいてトークンの位置情報を効果的にエンコードする手法として導入されました。 |
今回は、LLMの効率化や高速化に関連する技術論文を3つご紹介させていただきました。
今後も、社内で実施しているレビュー会での発表内容をブログで発信させていただくつもりですので、ご期待ください。
あなたにオススメの記事

2023.12.01
生成AI(ジェネレーティブAI)とは?ChatGPTとの違いや仕組み・種類・活用事例

2023.09.21
DX(デジタルトランスフォーメーション)とは?今さら聞けない意味・定義を分かりやすく解説【2024年最新】

2023.11.24
【現役社員が解説】データサイエンティストとは?仕事内容やAI・DX時代に必要なスキル

2023.09.08
DX事例26選:6つの業界別に紹介~有名企業はどんなDXをやっている?~【2024年最新版】

2023.08.23
LLM(大規模言語モデル)とは?生成AIとの違いや活用事例・課題

2024.03.22
生成AIの評価指標・ベンチマークとそれらに関連する問題点や限界を解説













