



メルマガ登録
-
テーマから探す
-
技術から探す
-
業界・事例から探す
-
関連トレンドから探す
テーマから探す
技術から探す
業界・事例から探す
関連トレンドから探す

ABテストは、ウェブサイトの改善やマーケティング施策の効果測定に不可欠な手法です。しかし、適切な知識なしにテスト結果を解釈すると、実際の効果を過大評価してしまうことがあります。この記事では、ABテストで真の効果を見極めるための正しい知識を習得することを目指します。なお本記事は、厳密性より、初学者の過大評価についての全体像把握を優先して記載しております。

まずは、ABテストがどんなテストなのかを見てみます。
インターネット上の商品販売サイトでABテストを実施したケースを考えてみます。まずはABテストの結果を仮説検定を用いて分析することを考え、その後でベイズ統計的な見方を取り入れます。
既存の仕組みであるA群・ウェブ画面の変更を適用したB群それぞれ10万人のサンプルで、標本CV率がそれぞれ\(5.0\%\)、\(5.1\%\)だったとします。この時、標本ではなく、その背後にある母集団に差があるか否かを考えます。母集団のCV率はA群、B群それぞれで、\(p_A\)、\(p_B\)とします。B群の母比率\(p_B\)はA群の母比率\(p_A\)と等しく、差は偶然の誤差であるという帰無仮説\(H_0\)と、母比率\(p_B\)は\(p_A\)とは異なる、つまり差には意味がある対立仮説\(H_1\)のどちらが妥当かを判定する枠組みが、統計的仮説検定によるABテストとなります。便宜上、母比率\(p_A=5.0\%\)として進めます。
表1がABテストの設定です。例えば\(H_0\)の元での標本平均は
\(5.0\%\pm\sigma/\sqrt{n}\simeq5.0\%\pm\sqrt{0.0475/100000}\simeq5.0\%\pm0.069\%\)
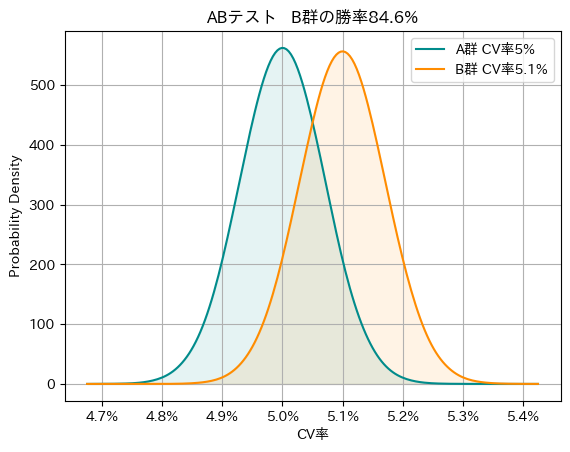
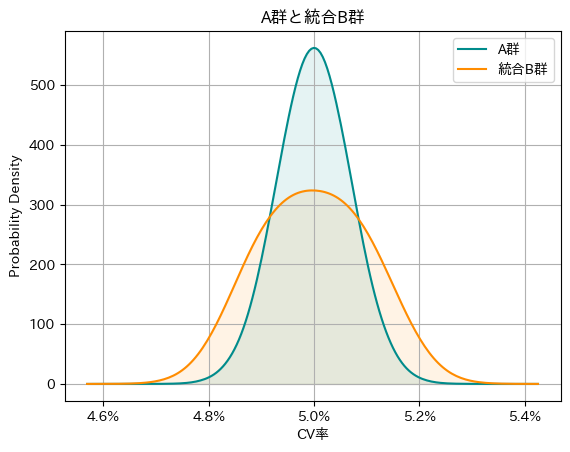
の範囲に収まります。ここで、\(\sigma\)は標準偏差、\(n\)はサンプルサイズです。そして図1は、A群の母比率が\(5.0\%\)、B群の母比率が\(5.1\%\)だった時に、10万人分のサンプル取得して標本平均を集計する操作を無限に繰り返した時に標本平均が従う分布となります。コントロール群の標本平均は図1の青線の様に分布します。同様に、施策群母集団がコントロール群母集団と異なり、その平均CV率を\(5.1\%\)とした時は、標本平均は\(5.1\%\pm0.070\%\)の範囲に収まり、図1のオレンジ線の様に分布します。このような条件の元で、施策群の母集団はコントロール群と同じなのか、それとも差があるのかを統計的に判定するのが仮説検定でのABテストです。
| \(H_0/H_1\) | 詳細 | 母数団CV率 | 標本サンプルサイズ | 標本分数 | 図1での見え方 |
| \(H_0\) | A群とB群の母平均は同じ | 5.0% | 10万 | 0.0475 | 青線 |
| \(H_1\) | A群とB群の母平均は異なる | 5.1% | 10万 | 0.0484 | オレンジ線 |
ここまでは、頻度論的な仮説検定の視点で解説してきました。これをベイズ統計的な視点で捉え直します。サンプルサイズなどの実務的な結論は大きく変わりませんが、結果の解釈がより直感的かつ柔軟になります。
大きな違いは、母比率の扱いです。従来の仮説検定では、母比率は未知だが固定された定数であると考えます。一方、ベイズ統計では、母比率を確率変数として扱います。つまり、母比率の真の値がどこにあるかという我々の確信度を確率分布として表現するのです。たとえば今回のCV率の例では、母比率の事後分布はベータ分布に従います。なお、本記事では、サンプルサイズが十分に大きいため、計算の便宜上、正規分布で近似して扱います。母比率を確率分布として可視化することで、B群のCV率がA群よりも高い確率は何%か?といった、ビジネス現場で求められる直接的な確率計算が容易になります。図1の例において、B群の分布がA群の分布を上回る確率を計算すると、\(84.6\%\)となります。なお、無情報事前分布を用いた場合は、\(1-\)片側検定のp値、となります。本記事では、以降はこのベイズ統計的な見方をベースに進めていきます。
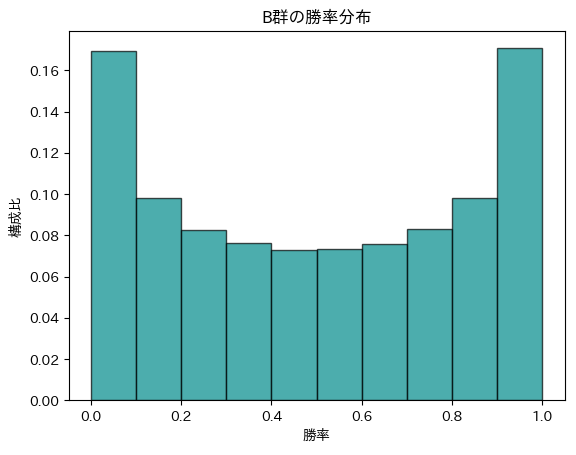
次に、A群の母平均が\(5.0\%\)、B群の母平均が\(5.1\%\)として、A群B群各10万人分のサンプルを集めて比較します。この設定でABテストを何度も繰り返し行った時、どのような結果になるでしょうか。この設定を考える場合は、図1を使うのが適切です。標本集団は母集団の周りに分布します。この時、観測される結果は表2の様になります。ここから言えることは下記の通りです。
| 勝率範囲 | 割合 |
| 0-20% | 3.1% |
| 20-40% | 7.0% |
| 40-60% | 12.0% |
| 60-80% | 20.8% |
| 80-100% | 57.1% |
| 99-100% | 9.6% |
このように、ABテストには誤差があり、誤差が大きい状況では間違った判断を引き起こしやすくなります。この例の様に、元々一定の効果があった場合、更に誤差で上振れすることもあります。また、本来効果があるはずなのに、B群が負ける確率も一定量発生してしまいました。では、正しく判断するためにはどうすれば良いのでしょうか。
過去のABテスト結果から、典型的なABテスト効果を見積もり、必要なサンプルサイズを用意する。必要なサンプルサイズがどうしても足りない場合は、足りなくても済むように工夫をする、というのが正しく判断する方法の一つとなります。次章では、各企業での典型的なABテスト結果を推定するときにも必要となる、AAテストについて考えます。
ABテストを正しく理解するには、その基礎となる全く差が無い状態での比較であるAAテストの理解が必須です。この章ではp値や勝率の分布を確認し、何が読み取れるかを解説します。
AAテストとは、同一のコントロール群を2つに分けて比較し、ABテストの仕組み自体が正しいかを検証するテストです。
AAテストでのp値は、偶然発生する確率と同じであり、p値が0.05未満になる確率は\(5\%\)となります。また勝率についても、「一定量の真の効果がある場合に観測される差」の節で記載した勝率とp値の関係を用いると一様分布となります。
つまり、AAテストを大量に行い、p値や勝率が綺麗な一様分布になれば、そのテスト環境や集計ロジックは正常であると判断できます。
p値が一様分布しているか否かを正確に確認するためには、非常に多くの試行回数が必要となります。
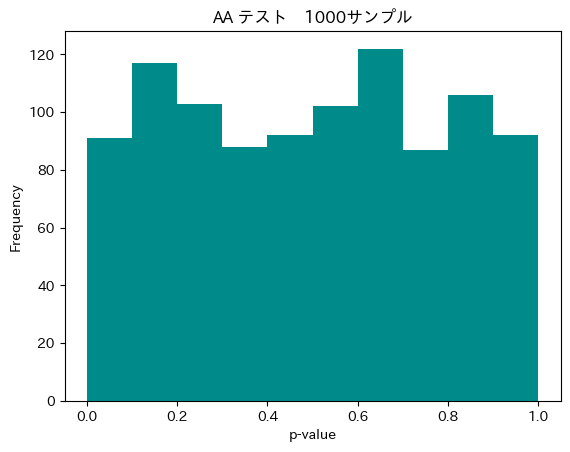
試行回数が1000回の場合が図2です。AAテストにおいて検出したい一様分布からの乖離は、p値が小さい領域において数割程度の偏りとして現れる場合があります。しかし、自然なばらつきが大きいため、微細な偏りはノイズに埋もれて判別できません。
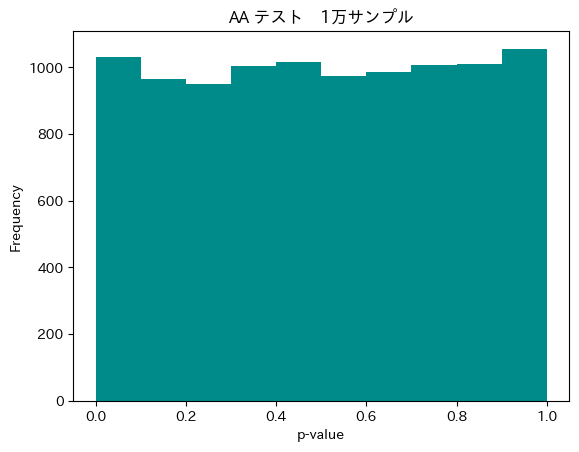
ノイズと異常を明確に区別するには、最低でも1万回程度のテスト(図3)、理想的には10万回以上の試行が推奨されます。
AAテストを実施することで、主に以下の2つの重要な点を確認できます。
ABテストで観測される結果が、実際にどれほどの真の効果を伴っているのかを理解することは非常に重要です。ここでは、AAテストの知識を応用し、過去のABテスト事例から真の効果を見積もる考え方について掘り下げていきます。
AAテストでは、理論上、p値や勝率が一様分布します。つまり、両群に差が無くても、確率的に勝率\(80\%\)以上という結果は5回に1回の頻度で偶然発生し得ます。
このため、個別のABテストで高い勝率となった場合でも、それが偶然なのか、真の効果なのかを断定するのは困難です。確信度を高めるためにサンプルサイズを増やす手もありますが、時間とコストが掛かります。
そこで有効なのが、同一企業同一システムでの過去ABテスト事例の蓄積と活用です。過去事例を分布として捉えることで、ある施策で観測された勝率\(80\%\)が偶然で発生している事象なのか、それ以上の頻度で発生している事象なのかを客観的に評価できます。更に偶然の効果を割り引くことにより、売上改善効果等を精緻かつ現実的に見積もることも可能となります。
現実の施策効果は連続的に分布しますが、ここではメカニズムを直感的に理解するため、真の効果を、負・無・正の3パターンに単純化したモデルで考えます。
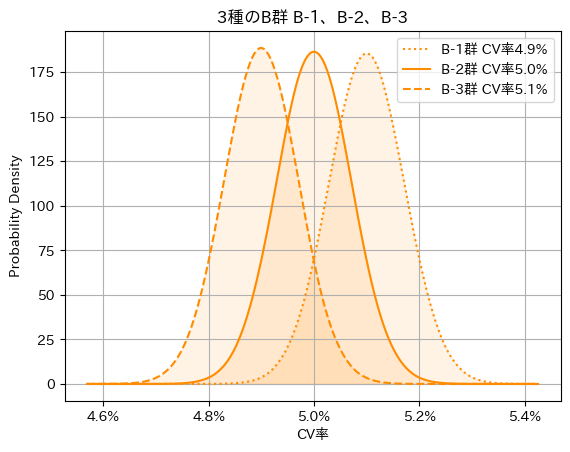
まずA群のCV率を\(5\%\)とします。比較対象のB群は、表3の性質を持ったサブグループ(B-1、B-2、B-3)が等確率で現れると仮定します。各サブグループの観測結果が図4、統合して、A群と比較した全体像が図5です。
| 群 | 詳細 | 群内比率 | CV率 | サンプルサイズ | CV数 |
| A群 | 既存の仕組み | 1 | 5.0% | 10万 | 5000 |
| B-1群(負) | ウェブ画面の変更を適用 | 1/3 | 4.9% | 10万 | 4900 |
| B-2群(無) | ウェブ画面の変更を適用 | 1/3 | 5.0% | 10万 | 5000 |
| B-3群(正) | ウェブ画面の変更を適用 | 1/3 | 5.1% | 10万 | 5100 |
このとき、B群に全く効果の無い場合はp値、および勝率は一様分布となります。しかし、今回は一定量の効果(サブグループB-1とB-3)を仮定したため、勝率およびp値の分布はそれぞれ図6-7の様になります。
ABテストに効果がある場合には、p値分布は0寄りになり、勝率分布は\(0\%\)もしくは\(100\%\)に寄っていき、V字型になります。更に施策の効果が強い場合、分布は両端に強く貼りつき、U字型へと変化します。勝率分布は単なる差の有無だけでなく、勝ち負けの方向性の情報も保持しているため、より多くの示唆を含んでいると言えます。
ここで図6に注目してください。分布は両端だけに極端に張り付くのではなく、勝率\(50\%\)付近を含めて全体になだらかに広がっています。これは、実施した施策の中に効果がない、または極めて小さい施策が相当数混ざっていることを示唆しています。
重要なのは、この図において勝率\(80\%\)として観測される部分の中身です。ここには、本当に効果がある施策(B-3)が実力で勝ったケースだけでなく、効果がない施策(B-2)が偶然勝ってしまったケースも混在しています。つまり、真の実力と偶然のラッキーが重ね合わせの状態になっているのです。この偶然の勝ちの割合を見積もらず、すべてを実力と捉えることが、ABテストの結果を過大評価してしまう大きな原因となります。
ここまで、ABテスト結果の解釈方法を見てきました。また、前章では、サンプルサイズを10万として、施策効果が\(\pm0.1\)程度の時の勝率分布やp値分布を確認しました。本章では、真の効果を仮定した時に、必要なサンプルサイズを算出します。
前提として、施策群とコントロール群のサンプルサイズは同数とし、データはベルヌーイ分布に従うものとします。表2、図1と同様の設定(施策群のCV率\(5.1\%\)、コントロール群のCV率\(5.0\%\))において、有意差を検出するにはどの程度のサンプルサイズが必要になるかを、仮説検定の枠組みを用いて計算します。
計算を単純化するため、コントロール群と施策群の母分散は\(\sigma^2\)は既知で同一だとします。\(n\)個のデータが溜まっていたとすると、それぞれの母平均から分散\(\sigma^2/n\)の分布となります。施策群の平均値を\(\bar{x}\)、有意水準\(\alpha\)としたとき、下記の条件で\(H_0\)は棄却されます。
サンプルサイズ\(n\)のABテストを実施した際、標本平均\(\bar{x}\)は、中心極限定理により母平均を中心とした分散\(\sigma^2/n\)の正規分布に従います。ここで、コントロール群の母平均を\(\mu_0\)、施策群の母平均を\(\mu_1\)とし、有意水準を\(\alpha\)と置きます。片側検定において、施策群とコントロール群の母平均に差がないとする帰無仮説\(H_0:\mu_1-\mu_0=0\)が棄却される(=有意差ありの)条件は以下の通りです。
\(\bar{x}>\mu_0+Z_{1-\alpha}\sigma/\sqrt{n}\)
ここで、\(Z_\alpha\)は標準正規分布の\(100\alpha\%\)点であり、\(\Phi\)を標準正規分布の累積分布関数として、\(\Phi(Z_\alpha)=\alpha\)とします。
更に、施策群側の分布が帰無仮説を棄却する確率(検出力\(1-\beta\))を考えます。この値は、平均\(\mu_1\)の施策群側の分布で、上記の棄却限界値\(\mu_0+Z_{1-\alpha}\sigma/\sqrt{n}\)よりも右側(\(+inf\)まで)の積分値となります。
この確率を\(\Phi\)を用いて表すために、平均0、分散1に正規化(標準化)を行います。上式から\(\mu_1\)を引いて平均を0にして、標準偏差\(\sigma/\sqrt{n}\)で割ることで割ると、標準正規分布に対する下限値は
\(下限値=\frac{\mu_0+Z_{1-\alpha}\sigma/\sqrt{n}-\mu_1}{\sigma/\sqrt{n}}\)
となり、この下限値からから\(+inf\)までの積分が検出力となります。\(\Phi\)を用いるために、\(-inf\)からの積分に直すと下記のようになります。
\(1-\beta=\Phi(\frac{\mu_1-\mu_0-Z_{1-\alpha}\sigma/\sqrt{n}}{\sigma/\sqrt{n}})\)
\(=\Phi(Z_\alpha+\frac{(\mu_1-\mu_0)\sqrt{n}}{\sigma})\)
ここで、\(Z_{1-\alpha}=-Z_\alpha\)を使いました。ここから\(1-\beta=\Phi(Z_{1-\beta})\)を使うと
\(\Phi(Z_{1-\beta})=\Phi(Z_\alpha+\frac{(\mu_1-\mu_0)\sqrt{n}}{\sigma})\)
関数\(\Phi\)の中身同士が両辺で等しいので
\(Z_{1-\beta}=Z_\alpha+\frac{(\mu_1-\mu_0)\sqrt{n}}{\sigma}\)
更に\(n\)について解くと
\(n=\frac{(Z_{1-\beta}+Z_{1-\alpha})^2\sigma^2}{(\mu_1-\mu_0)^2}\)
となります。
例として、コンバージョン率\(5.1\%\)の施策群と\(5.0\%\)のコントロール群に対して、同数のサンプルを用意します。この時に\(\alpha=0.05\)、\(\beta=0.2\)を満たすサンプルサイズを考えます。\(Z_{0.95}=1.6449\)、\(Z_{0.8}=0.8416\)、分散に関してはCV率から求めた値を入れると、下記のようになります。
\(n=\frac{(1.6449+0.8416)^{2*}0.0505^*(1-0.0505)}{(0.05-0.051)^2}\)
\(=296,458\)
となり、およそ30万人いると、条件が満たされることが分かります。実際に図を書いてみると図8の様になります。
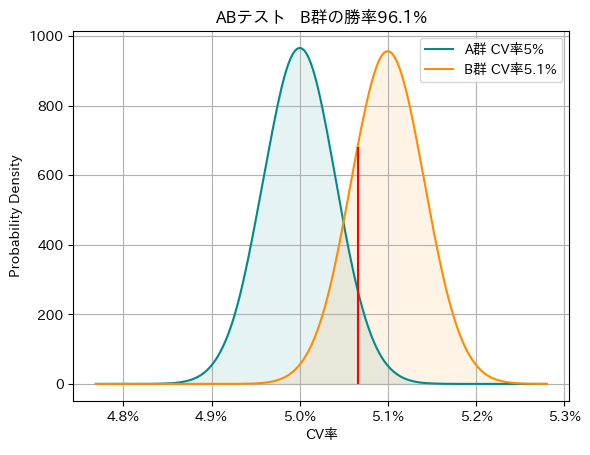
ここで、コントロール群(青の正規分布)に対して、赤線は積分値を\(95\%\)と\(5\%\)で分けます。この時施策群(オレンジの正規分布)に対して、赤線の右側は全体の\(80\%\)となっており、丁度条件が満たされていることが分かります。
ABテストでのサンプルサイズを決めるのには、統計的な設定である\(\alpha\)、\(\beta\)の値の他に、その施策でどれくらいの効果差が出そうか(典型的な施策効果)を見積もる必要があります。これを事前に知るのは非常に困難です。もし、毎回誰が見ても明らかな差が出るような強力な施策ばかりなら問題ありませんが、現実はそうではありません。そのため、当該企業での過去施策の勝率分布から推定する作業が必要になります。
ABテストでは、十分なサンプルサイズが集まらないという問題が常につきまといます。しかし、これはどの指標で比較するかという設計次第で、解決できるケースがあります。
売上を最大化したいという目的を考えると、ABテストの指標としてCV数や売上総額(例:課金額)を選びがちです。しかし、これには大きな落とし穴があります。
CV率は優れた指標ですが、それでも最終的なCV(購入完了など)まで到達するユーザーが少ない場合、差を見るためにはやはり膨大なサンプルサイズが必要になります。
そこで、遷移率(=CVまでの中間ステップの突破率)を指標にするという手があります。
施策Bがカートに商品を入れることを促すものだった場合、最終的な購入完了率で比較するより、カート投入率で比較する方が合理的です。
カート投入は、購入完了よりも多くのユーザーが実行するはずです。より多くのデータ(サンプル)で比較できるため、施策の効果をより正確に、早く把握できる可能性が高まります。この中間ステップ(遷移率)の改善は、最終的なCV率の向上に貢献すると考えられます。
※カート投入率はあくまでも例です。
ABテストを実施しているのに、知らずに運任せになっていませんか。サンプルサイズが不十分なままたまたま出た数字だけで一喜一憂するのは、単におみくじを引いているのと同じです。せっかくの工数や費用をかけても、貴重なリソースを浪費することになりかねません。
このブログでは、ABテストの基本、効果の推定方法、そして適切なサンプルサイズの設計までを解説してきましたが、ここでは改めてなぜ過大評価が起きるのかというメカニズムと、それを避けるための原則をまとめます。
全く差がないAAテストの挙動から分かる通り、真の効果がゼロの施策であっても、勝率\(80\%\)という良さそうな結果は\(20\%\)の確率で偶然発生します。過去のテスト結果の分布が\(0\%\)や\(100\%\)に偏らず、\(50\%\)付近を含めて平坦に広がっているなら、その企業が行っている施策には効果がない、もしくは小さいテストが一定割合で混ざっています。この状況下で、たまたま勝率が高かった結果だけを選抜して意思決定を行うことは、ノイズ部分も含んだ結果を実力だと勘違いし、施策効果を過大評価することになります。
サンプルサイズが小さいと、仮に真の効果があったとしても、そこに標本誤差による上振れが加わることで、結果として\(99\%\)を超えるような異常に高い勝率が表示されてしまうことも確認しました。高い勝率が出たからといって、実際の売上インパクトがそれに比例して大きいとは限りません。
こうした過大評価や偶然の罠を避け、統計的に意味のある意思決定を行うためには、以下の観点が不可欠です。
ノイズを減らし、真の効果を見極めるための大前提です。\(\alpha\)、\(1-\beta\)の値を決め、当該企業でのABテスト効果を見積もることにより、適切なサンプルサイズの見積もりが可能となります。
サンプルサイズを増やすのが難しい場合でも諦める必要はありません。まず検討すべきは、代替指標への切り替えです。比較する指標そのものを、より分散の小さいものや感度の高いものに見直すことで、統計的に有意な差を検出できるテストへと設計し直すことが可能です。もしくは、効果の無い施策が一部混じることを許容した上で、偶然の効果を差し引いて、売上改善効果等を堅実に見積もる方針も有効な手段です。
偶然の結果に惑わされず、データから真の実力を正しく読み解く姿勢が、ABテストの成功には不可欠です。
あなたにオススメの記事

2023.12.01
生成AI(ジェネレーティブAI)とは?ChatGPTとの違いや仕組み・種類・活用事例

2023.09.21
DX(デジタルトランスフォーメーション)とは?今さら聞けない意味・定義を分かりやすく解説【2024年最新】

2023.11.24
【現役社員が解説】データサイエンティストとは?仕事内容やAI・DX時代に必要なスキル

2023.09.08
DX事例26選:6つの業界別に紹介~有名企業はどんなDXをやっている?~【2024年最新版】

2023.08.23
LLM(大規模言語モデル)とは?生成AIとの違いや活用事例・課題

2024.03.22
生成AIの評価指標・ベンチマークとそれらに関連する問題点や限界を解説
















