



メルマガ登録
-
テーマから探す
-
技術から探す
-
業界・事例から探す
-
関連トレンドから探す
テーマから探す
技術から探す
業界・事例から探す
関連トレンドから探す

第8回(前回)は生成AIのひとつである拡散モデルの既存研究の再現をしつつ、実際の活用について議論・考察をしました。取り上げた研究は表形式データの生成でしたが、今回は因果推論の研究を取り上げます。前回同様、当該研究に関わった社員を交えて今後の発展性について考えていきたいと思います。


株式会社ブレインパッド・角谷 督(以下、角谷)今回は、拡散モデルの応用研究に携わった弊社の若手社員を交えて、応用研究の結果やそこから示唆される活用方法や将来の課題について議論していきたいと思います。まずは、今回の研究では、ふたつのテーマを扱っています。ひとつがテーブルデータの生成精度の検証であり、ふたつ目が因果推論に関する適用事例の実証研究です。ここで、ふたつ目の研究に携わった弊社の若手データサイエンティストを紹介します。西巻さん、簡単に自己紹介をお願いします。
株式会社ブレインパッド・西巻(以下、西巻)2024年に入社いたしましたデータサイエンティストの西巻です。 入社後は、製品のセンサーデータを活用した要件定義用ダッシュボードの構築や、設備画像の腐食度判定モデルの開発などに従事しておりました。 本日はよろしくお願いいたします。
株式会社ブレインパッド・山崎 清仁(以下、山崎)西巻さん、因果推論が研究のテーマになっていますが、これを採用した理由は何でしょうか?
西巻 はい。身近な例として、マーケティング施策を例に説明しますね。例えば、マーケティング施策の場合、ある顧客に対して施策を実施すれば、その効果がどうであったかを知ることは可能ですが、施策を実施しなかった場合、結果は未知です。逆に当該顧客に施策を施さなかった場合、施策の効果を知ることが出来なくなります。施策の有無によって、結果がどのように変わるかを知りたいと考えたとしても、その両方の結果を同時に知ることは出来ません。因果推論は、データをもとにして原因(ここではマーケティング施策)と結果の関係性を分析して明確にすることを目的とするものです。よって、例にあげたマーケティング施策効果の測定にも利用されますし、医学・薬学・品質管理などの多様な応用分野があることが当該テーマを選んだ理由です。
角谷 因果推論では、原因と結果に影響を及ぼしている外部要因(交絡因子と呼ばれる)の存在が問題となりますよね。
西巻 そうですね。特定の属性の人が選ばれて施策がなされ、当該属性の人が特に施策に対して大きな反応が観察されるとします。その場合、施策に対する反応の大きさは、異なる属性の顧客には当てはまりません。施策結果を予測するだけなら、因果推論は必要ではないと思いますが、施策の効果量を知りたい場合は因果推論が必要となってきます。原因以外の要因は同じであって原因のみが異なる状況を考えて、その状況下で結果に差があれば、その差は原因に依ることになります。マーケティング施策の場合、それが施策効果になります。
山崎 今回は、先行研究を踏襲して、結果を再現することから始めたと聞きました。
西巻 拡散モデル自体の取り扱いが、当社では豊富ではないので、まずは研究された結果を再現したうえで、応用を考えようと思ったので、その順序で研究を進めています。
山崎 具体的な研究内容をご説明して頂けますか。
西巻 DiffPO(2024)※の研究を再現することから始めています。DiffPOは、ある患者が処置を受けた場合、観測された「処置あり/なし」の結果に対して、観測されない「処置なし/あり」を潜在的結果(Potential Outcome)として推定することを試みています。通常の因果推論では、複数の患者を処置ありグループ(処置群)と処置なしグループ(対照群)とに分けて、グループごとに患者の属性(共変量)から観測結果を予測する機械学習モデルを学習します。同じ共変量に対してモデルの予測値の差から処置効果を推定することになります。一方、拡散モデルでは、処置のあり/なしを処置変数A=1または 0として、共変量とともに患者属性を表す条件として扱います。その条件のもとで観測結果と潜在的結果の両方をひとつの条件付き確率分布として学習することになります。
※Y.Ma et al., DiffPO: A causal diffusion model for learning distributions of potential outcomes, 2024
角谷 共変量と処置変数を所与とした条件付き分布として観測結果を学習し、観測されていない潜在的結果を生成するということですね。そこにはどのようなメリットがあるのでしょうか。
西巻 いま、おっしゃられたように、モデルは条件付き分布の構造を学習しています。処置変数Aが0であっても1であっても、処置結果を多数のデータの分布として得ることが出来ます。単純に処置効果として、処置ありと無しの2ケースの差分データがひとつ得られるのではなく、ふたつのケースの処置効果量の分布を取得することが出来ます。つまり、処置効果の平均や分散、処置効果が統計的に有意であるかどうか、どのような患者に対して特に有意であるのかなどの情報を得ることが出来ます。下記のイメージ図をご覧ください。処置を施したかどうかで、分布に違いがありますが、それなりの重なりが観測されます。効果にどれくらいのリスクがあるのかもデータから推測できることになります。
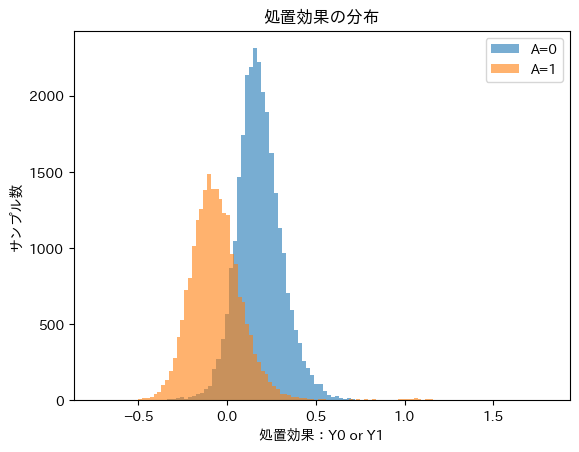
角谷 なるほど。そうすると、マーケティング施策などにおいても、その効果量が期待値だけではなく、リスク量も推定できるということですね。施策効果の下方リスクをマネタリーベースに変換できれば、施策がうまく行かなかった場合の期待損失なども推定できそうですね。
西巻 そうですね。医療やマーケティング施策においては、個々の患者や顧客に対して、施策効果を分布として計量化できるので、リスクの大きな個人に対しては施策を実施せずに、効果が見込まれる確率の高い顧客に対してのみ、施策を実施することが可能です。施策間の比較においても、期待値のみならず、リスクも比較対象となるので、より効率的な施策選択が可能ではないでしょうか。
山崎 拡散モデルを適用するメリットは他にもありますか。
西巻 因果推論に適用される代表的なAIモデルには、処置群と対照群とでY(A=1)とY(A=0)を単一モデルで予測して、それらの差分を処置効果τとするS-learner(Sはsingleを意味します)と、Y(A=1)とY(A=0)を異なるふたつのモデルで予測して、それらの差分をτとするT-learner(Tはtwoを意味します)があります。一般的には処置群と対照群で、共変量に違いがないように実験デザインを考える必要があります。一方、推定結果の違いを傾向スコア(年齢や性別などの複数の背景因子(共変量)を考慮し、処置群と対照群の間のバイアスを調整するために用いられる)で調整し、それを改めて学習するモデルも開発されています。その代表例が、DR-learner(Doubly Robust learner)やDA-learner(Domain Adaptation learner)です。これらは2段階で学習する必要が生じるため、損失関数の計算時に傾向スコアを考慮することができる拡散モデルと比べると精度が劣化する可能性があります。
今回の研究では、実際にこれらのモデルを拡散モデルと比較した結果を示しています。
山崎 では、実証分析結果をご紹介ください。
西巻 前述した論文で適用されたデータと拡散モデルを用いて再現実験するとともに、上記のモデルと精度を比較しています。比較対象は、効果の期待値の精度になるのですが、拡散モデルでは条件付き分布として効果量が得られるので、条件付きサンプリングで取得された100個のデータの中央値を期待値として用いています。なお、10分割交差検証を実施しています。検証結果は下図です。棒グラフは各モデルの平均誤差、エラーバーは標準偏差です。
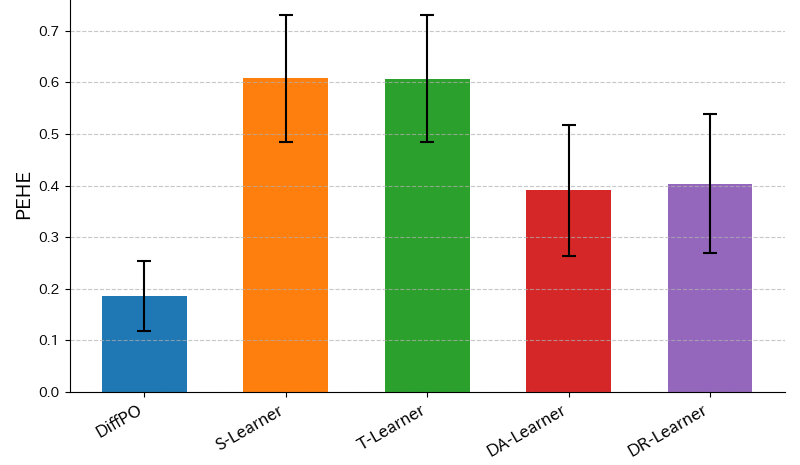
山崎 誤差の平均は拡散モデル(DiffPO)が最も小さいですね。
西巻 そうですね。左から2番目、3番目のモデルの精度が悪いのは、傾向スコアによる調整がなされていないのが理由だと思われます。傾向スコアによって調整された左から4番目、5番目のモデルは、それらよりも精度が改善されているのがわかります。精度は拡散モデルが最も良かったわけですが、上述したように潜在結果を分布として直接可視化できるというメリットがあります。下記のグラフをご覧ください。
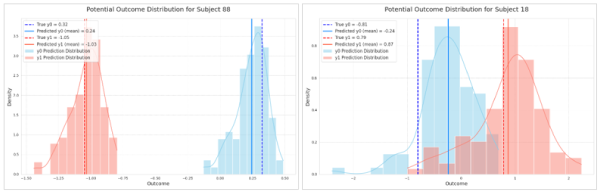
これらは、「処置あり」と「処置なし」を比較した2人の患者のグラフです。左の患者のグラフは処置の効果が際立っており、明確な効果が期待できます。一方、右のグラフは処置の有無のふたつのグラフの重なりが大きく、処置の結果、効果が表れないリスクも大きいことがわかります。このような確率分布を比較的容易に得られる(計算コストが低く、ベイズ推定のような事前分布の仮定が必要ない)ことが、拡散モデルのメリットであるといえます。
山崎 複数のリコメンデーションをシミュレーションして比較検討することも出来そうなので、面白そうですね。今回のリサーチでは、どのようなことで苦労があったのでしょうか。
西巻 ノイズ予測ネットワークのアーキテクチャ最適化に苦労しました。DiffPOは学習データにノイズを加え、それを除去するプロセスを学ぶことで、共変量と処置変数に基づいた潜在的結果の分布を生成できるようになります。しかし、このノイズ除去を行うネットワークは、使用するデータの次元や特性に応じて、表現力(レイヤー数やアテンションなど)を適切に設計しなければ精度が出ないため、その調整に時間を要しました。具体的には、論文で用いられていたオリジナルのネットワークは今回のデータセットに対しては冗長で過学習を招いたため、一部のアテンション機構の削除や層の削減を行い、モデルを軽量化することで汎化性能を向上させました。
角谷 拡散モデルの研究では、今後、どのような分野への活用・発展が考えられますか。
西巻 そうですね。LLM分野においても、拡散モデルは注目されている技術です。GPTなどは、トークンを順次生成するオートリグレッシブ(Auto-Regressive)型ですが、拡散モデルはトークンを並列で処理します。そのため、高速で文章の穴埋めや修正が可能となると考えられます。その辺りも今後は研究してみたいと思っています。
山崎 本シリーズでは、3回に渡って拡散モデルを取り上げました。拡散モデルの概要から実証分析に至るまで紹介しましたので、どのような活用ができるのかに関してイメージを持ってもらえたかと思います。また、研究を担当した若手社員も交えて対談することを試みました。今後も様々な分野で活躍する若手社員の現場の声を届けていきたいと思います。
次回は技術から離れて、AIモデルの信頼性を確保する試みに関して当社の活動を紹介したいと思います。
あなたにオススメの記事

2023.12.01
生成AI(ジェネレーティブAI)とは?ChatGPTとの違いや仕組み・種類・活用事例

2023.09.21
DX(デジタルトランスフォーメーション)とは?今さら聞けない意味・定義を分かりやすく解説【2024年最新】

2023.11.24
【現役社員が解説】データサイエンティストとは?仕事内容やAI・DX時代に必要なスキル

2023.09.08
DX事例26選:6つの業界別に紹介~有名企業はどんなDXをやっている?~【2024年最新版】

2023.08.23
LLM(大規模言語モデル)とは?生成AIとの違いや活用事例・課題

2024.03.22
生成AIの評価指標・ベンチマークとそれらに関連する問題点や限界を解説
















