



メルマガ登録
-
テーマから探す
-
技術から探す
-
業界・事例から探す
-
関連トレンドから探す
テーマから探す
技術から探す
業界・事例から探す
関連トレンドから探す

当社のプロフェッショナルサービスでは、コンサルタント・データサイエンティスト・エンジニアが一体となって、企業の経営課題をデータドリブンで解決する包括的なサービスを提供しています。
プロフェッショナルサービスでは機械学習プロジェクトとして進むことが多く、簡略化したフローは以下のようになります。

| フェーズ | 概要 |
|---|---|
| 企画 | プロジェクトにおける目的・ゴールを明確化する。 |
| 分析PoC | 機械学習モデルの構築と精度検証を行う。 |
| 実地検証 | 分析PoCで得られたモデルを実際の業務に試験的に適用し、ビジネス効果を実証する。ここで期待する結果が得られるとシステム化に移行する。 |
| システム化 | 機械学習モデルを含むシステムの本格開発を行う。 |
| 運用保守 | システムと機械学習モデルの精度を監視する。システム障害時やモデルの精度低下などが見られた場合は復旧および原因調査など改善策を実施する。 |
本記事では、このフローの中からシステム化フェーズにおけるデータ分析システム構築について、2回に分けて詳しくご説明いたします。前編では「データ分析システム全体の概要とデータ基盤」を、後編では「データ分析とデータ可視化」をご紹介します。
データ分析システムとは、企業や組織が持つ多様なデータを効率的に収集・蓄積・加工・分析し、ビジネスに活用するシステムのことを指します。
データ活用の具体例としては、需要予測および在庫の最適化、購買履歴に基づくレコメンド、製造業における異常検知などがあります。これらは業務効率化や顧客満足度向上、ビジネス価値創出に大きく貢献します。
一般的にデータ分析基盤構築の進め方は大きく2種類あります。
ひとつめは大規模データ分析基盤です。こちらはトップダウン的なアプローチで、企業全体の膨大なデータを一箇所に集約します。そこを起点として、幅広いユーザーと多様な分析ニーズに対応することができます。
ふたつめは小規模データ分析基盤です。こちらはボトムアップ的なアプローチで、特定の部門や活用方法に合わせてデータを収集します。設定済みのゴールに沿ってデータを活用することが特徴です。小規模データ分析基盤では、初期段階でミニマムな基盤を構築し、効果を検証しながら段階的に拡張していきます。このアプローチにより、リスクを抑えつつ早期に価値を提供することが可能になります。
データ分析プロジェクトを成功させるには、企画フェーズでプロジェクトのゴールを明確化し、スモールスタートで迅速に進めることが重要です。当社がサポートするデータ分析プロジェクトでも、小規模なデータ分析基盤からスタートする例が多くあります。
本記事では小規模データ分析基盤に焦点を当て、その概要から構成例、サービス選定のポイントまでを紹介します。当社ではお客様の環境に合わせて、主要クラウド(AWS・Microsoft Azure・Google Cloud)やデータ分析プラットフォーム(Snowflake・Databricks)を活用した実績があります。今回はAWSを利用した場合の例をご紹介します。
データ分析システムの構成要素を大きく分けると以下の3点になります。
| 構成要素 | 概要 |
|---|---|
| データ基盤 | 企業内の様々なデータを収集し、集めたデータを分析しやすい形に加工して保管します。 |
| データ分析 | データ基盤のデータを元に、機械学習などを用いて分析することで、意思決定などに役立つ洞察を抽出します。 |
| データ可視化 | データ基盤のデータやデータ分析結果をBIツールやWebアプリケーションなどで可視化し、意思決定を支援します。 |
データ分析システムは、これらの構成要素を組み合わせて、「データ基盤(収集・蓄積・加工)」「データ分析」「データ可視化」の順にデータを処理・活用し、ビジネス価値を創出します。
図2、図3にデータ分析システムの全体構成の例を2点記載します。
矢印はデータの流れを表しており、赤枠の部分はふたつの例で異なる部分を表しています。
データ分析システムでは業務要件に応じて、以下の箇所が変わりやすいことが特徴です。
これらは業務要件に応じて、最適な構成を検討することが重要です。
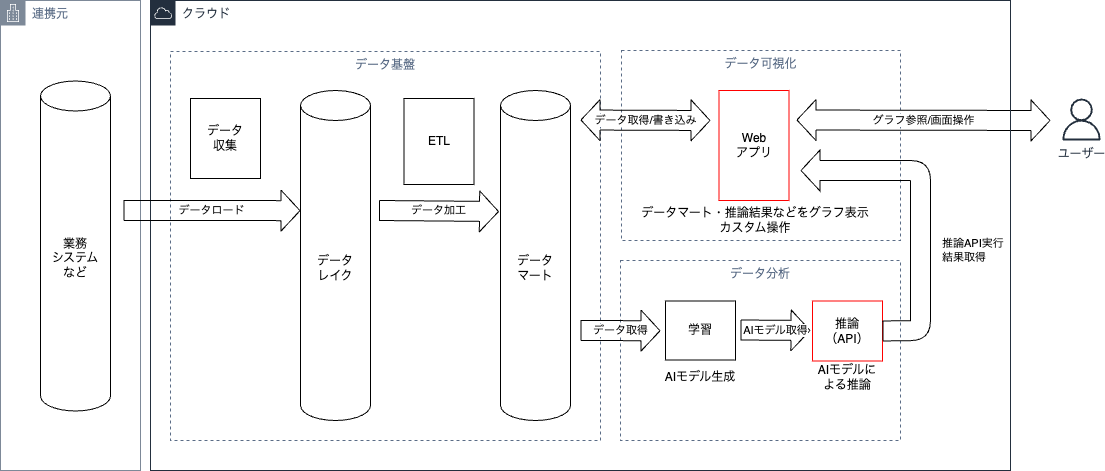
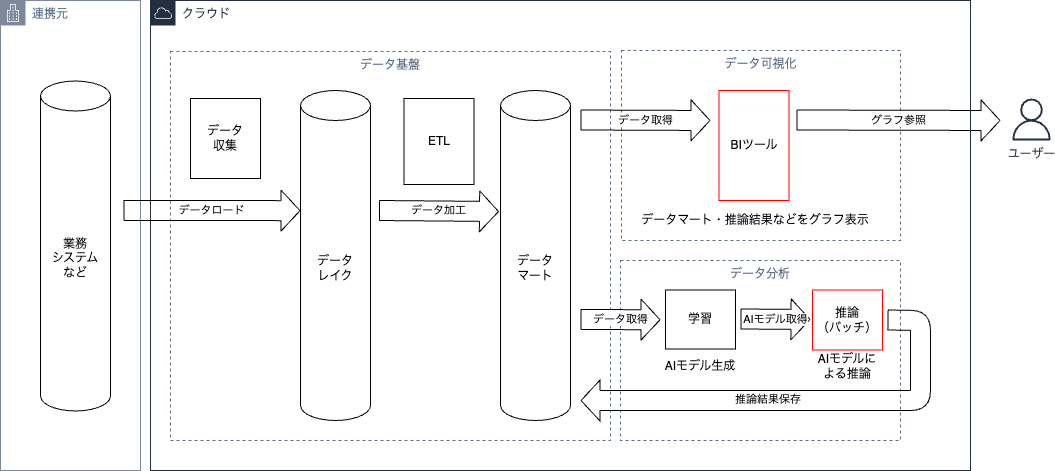
以降の章ではデータ基盤・データ分析・データ可視化のそれぞれの構成要素を構築する上でのAWSサービスを紹介します。
なお、AWSサービスの紹介では、AWSマネージドサービスとOSS(オープンソースソフトウェア)を利用した場合を記載します。一般的にAWSマネージドサービスを利用すると、サーバー管理や運用作業の一部をAWSが代行するため、運用負荷が削減できるメリットがあります。一方、OSSを利用すると、候補となるソフトウェアの選択肢が多く、要件に応じてカスタマイズしやすいといったメリットがあります。そのため、プロジェクトの状況・方向性に合わせて、AWSマネージドサービスとOSSの利用判断を行うこととなります。
また、技術情報は2025年6月時点の内容に基づいています。
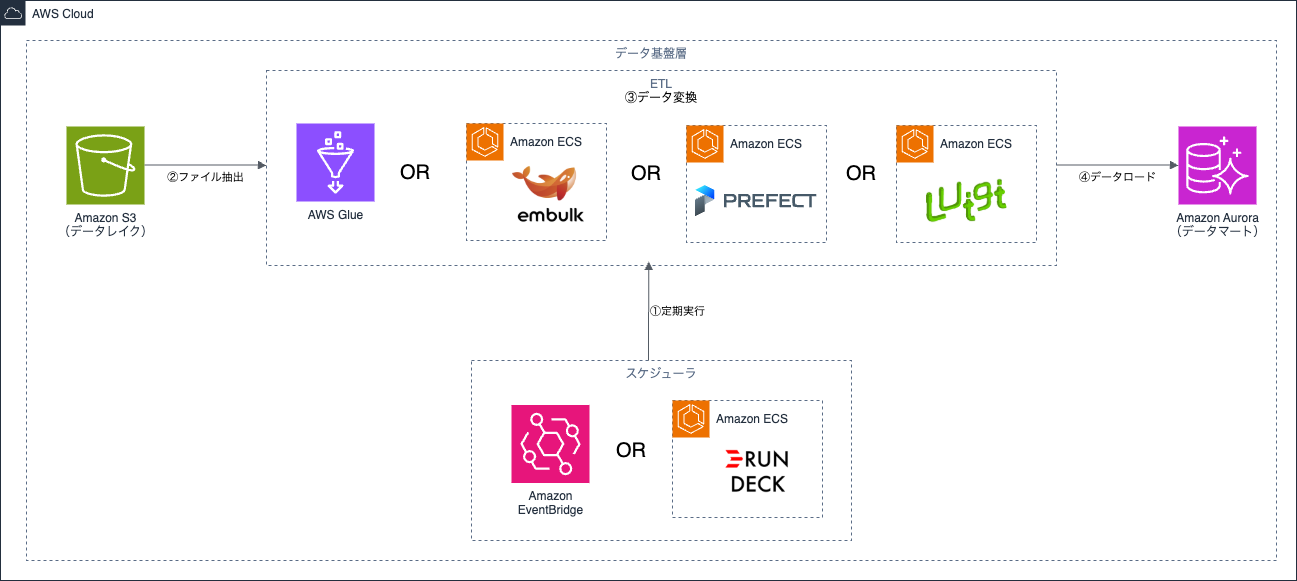
データ基盤は以下の4つの要素から構成されます。
| 構成要素 | 概要 |
|---|---|
| データ収集 | 企業内の様々なデータやIoTなどからデータを集めます。 |
| データレイク | データ収集で集めたデータの格納先です。基本的に元のファイル形式のまま保存します。サービス選定の上ではデータの容量制限がないことが重要です。 |
| ETL | データレイクのデータ抽出(Extract)・データ変換(Transform)・データマートへの格納(Load)を行います。 |
| データマート※ | 構造化されたデータを格納する場所。分析や可視化などに活用します。 |
※構造化データの格納先はデータウェアハウスと表記されることが多いですが、本記事では特定の用途向けであることを考慮し、データマートとしています。
データ収集のアーキテクチャを検討する際、まず確認するのはデータソース(データベース、ストレージ、IoTなど)や取り込み方法(バッチ、ストリーミング、イベントドリブンなど)です。
本記事の中ですべてのパターン例を網羅することは難しいため、ここでは代表例として以下ふたつのパターンを紹介します。
| パターン1 | パターン2 | |
|---|---|---|
| データソース | ファイル | データベース |
| 取り込み方法 | イベントドリブン | バッチ |
パターン1のケースで、当社での実績上よくある方法は、データ連携元のシステムからSFTP(Secure File Transfer Protocol)でデータを連携する方法です。SFTP連携を実現する上で、候補となるAWSサービスはAWS Transfer Familyです。
AWS Transfer Familyを利用すると、マネージドなSFTPサーバーを構築できるため、ユーザー自身でのインフラ管理が不要となり、運用の人的コストを抑えることが可能です。さらに、AWSの各種IAMロールによるアクセス制御とも連携できるなど、セキュリティ上のメリットもあります。ただし、SFTP Transfer Familyは月200ドル以上と比較的高価なサービスとなります。
リソースの費用を抑えたい場合はOSSなどを活用して自前でSFTPサーバを用意する選択肢もあります。OSSを利用する場合、AWSサービスとしてはAmazon ECSやAmazon EC2を利用します。Amazon ECSの場合は公開されているリポジトリを利用すると容易にSFTPサーバを構築できます。ただし、OSSを利用する場合は、パッチ適用などを自前で行ったり、アクセス制御やログ管理に対してAWSサービスとの連携がしにくいなど、運用の人的コストがかかります。
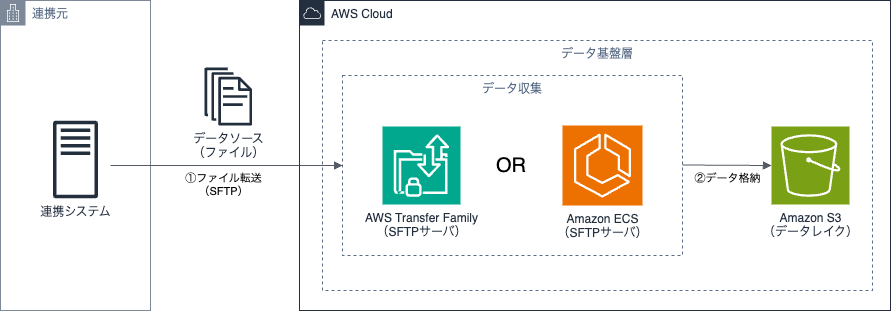
パターン2のケースで候補となるAWSサービスはAWS Glueの利用です。AWS Glueを利用すると、複数のデータソース間でデータを移動し、統合することが可能です。接続元・接続先はAmazon AuroraやAmazon Redshift、Amazon S3といったAWSサービスだけでなく、オンプレミスのPostgresSQLやSnowflake, BigQueryなど様々なサービスに対応しています。さらにAWS Glueはサーバーレスアーキテクチャのため、課金されるのはデータ処理中のみである点もメリットのひとつです。
OSSを利用する場合、代表的なものとしてEmbulkがあります。Embulkはプラグインを用いることで、様々なサービスに対して連携できます。設定・開発内容はYAML形式のファイルで容易に記述できることもメリットのひとつです。
Embulkを利用するには、実行環境としてAmazon ECSなどを用意し、バッチ処理として動かせるように設定します。そのように設定すると処理中のみの課金となります。
パターン2ではバッチ取り込みとなるため、AWS GlueやEmbulk実行のスケジュール管理の仕組みも必要です。AWSマネージドサービスでのスケジュール管理は基本的にEventBridgeを利用します。
Amazon EventBridgeではcronベース or rateベースでのスケジュール管理が可能です。複数サービス・ジョブの連携が必要な場合は、Amazon EventBridgeとAWS Step Functionsと組み合わせます。両者ともにインフラ管理が不要で様々なAWSサービスと連携しやすい点がメリットです。
OSSでスケジュール管理する場合は、Rundeckが候補のひとつとしてあります。
RundeckはWeb UI上でイベント管理できるため設定がしやすく、スクリプトでジョブ内容を記述できる・複数ジョブの連携や秒単位のスケジュールが可能など、Amazon EventBridgeと比較して複雑なジョブ管理に向いています。ただし、Rundeckを実行する環境としてサーバーや設定データ管理用のストレージ・データベース、Rundeckにアクセスするためのネットワーク設定などが必要なため、Amazon EventBridgeと比較すると管理対象が増えるデメリットがあります。
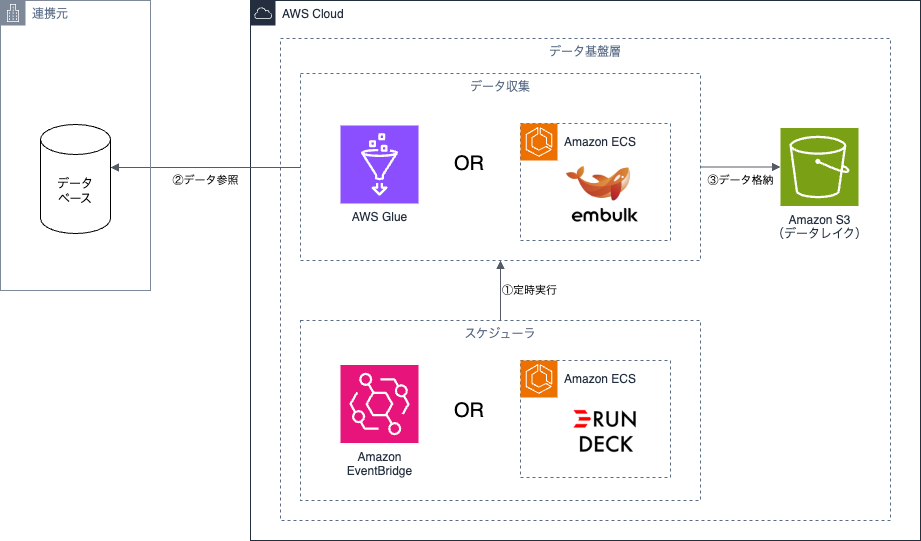
本節ではデータレイク、ETL、データマートの候補となるAWSサービスを紹介します。
データレイクの役割は、データ収集したデータを元のデータ形式のまま(またはそれに近い形式で)保存することです。そのため、CSV形式だけでなく、ExcelやPDFなど非構造データも対象になり得ます。
データレイクは加工前のデータが集まるため、データ容量が最も高くなります。そのため、AWS上での構築ではS3が利用されます。Amazon S3を利用すると、様々なファイル形式に対応できるだけでなく、ストレージサイズも無制限です。さらに、AWS Lake Formationと組み合わせると、利用者別に特定の行・列単位での細かなアクセス制御ができるなど、データガバナンス・セキュリティ強化を求める場合に有用な選択肢となります。
データレイク構築の際の注意点のひとつを挙げると、S3バケットにおける適切なパスの設定です。パスをデータ種別や年月日など階層別に整理することで、アクセス制御を適切に行えたり、AWS Athenaなどでデータ分析をする際のスキャン範囲を狭めることが可能となります。そのため、設計段階でユースケースを考慮してパス構成を考えることは重要です。
ETLの役割は、データレイクからのデータ抽出・データ変換・データマートへの格納です。AWS上でETLを構築する際の選択肢のひとつはAWS Glueです。
AWS Glueの加工処理ではApache Sparkベースの分散処理エンジンが用いられるため、比較的大規模なデータにも対応できる特徴があります。注意点として、AWS GlueではDockerイメージが使えるのはローカル環境のみのためクラウド環境とローカル環境で差異が発生しうる点や、後述のOSSのETLツールと比べると複雑な分岐条件には対応しきれない点があります。
OSSで比較的シンプルなデータ変換をしたい場合はEmbulkも候補となります。Embulkのデータ変換は、YAML形式の設定ファイルを用いて、手軽にできることが特徴です。ただし、コード実装による複雑なデータ変換は対応しにくいです。
より複雑なデータ変換が発生する場合や複雑なワークフロー制御が必要な場合は、PrefectやLuigiなどのOSSのETLワークフローツールをAmazon ECSやAWS Batchと組み合わせて使うと開発しやすくなります。PrefectやLuigiはいずれもPythonでワークフローを設計し、複雑な条件分岐にも対応可能です。ふたつのツールを比較すると、Prefectのほうがより新しく、自由度・応用範囲が広いです。一方、Luigiは歴史が長く、安定した実績があります。OSSのETLツールは技術進化が活発なため、技術トレンドのキャッチアップが重要な分野です。
その他のETLの候補にはEMR(Elastic MapReduce)やMWAA(Managed Workflow for Apache Airflow)もありますが、これらはいずれも比較的規模の大きいケースに使われます。
データマートは、AWS上だとAmazon Aurora、Amazon RDS、Amazon Redshiftが候補となりますが、本記事で扱う小規模データ分析基盤(GBレベルを想定)では、リレーショナルデータベース(Amazon Aurora AuroraやAmazon RDS)で十分なケースが多いです。
リレーショナルデータベースを用いると、データ基盤におけるデータマート以外にも、データ可視化用のWebアプリケーションや推論処理からのトランザクションデータ管理など様々な用途で使えるというメリットがあります。ただし、リレーショナルデータベースは大規模データの管理には向かないため、データ基盤の将来的な拡張性も考慮してサービスを選定する必要があります。
本記事では、小規模データ分析システムをAWS上に構築する際の全体像とデータ基盤のアーキテクチャ例を紹介しました。データ基盤は、データ収集の方法やデータ加工の複雑さ、データサイズなどによって構成が変わる部分がありますが、全体像を理解した上で、それぞれに対応できる複数の選択肢を想定しておくと、さまざまなケースに柔軟に対応できるようになります。
弊社では低コスト・短期間でクラウド上にセキュアなデータ基盤を構築するサービス、Smart Strategic Platform(SSP)を提供しています。データ活用ビジネスをすばやく開始したい場合は、ぜひ、お気軽にお声掛けください。
【参考記事】
機能プリセット型データ活用基盤「Smart Strategic Platform(略称:SSP)」|株式会社ブレインパッド(BrainPad Inc.)
後編では、データ分析・データ可視化層についてご紹介いたします。
あなたにオススメの記事

2023.12.01
生成AI(ジェネレーティブAI)とは?ChatGPTとの違いや仕組み・種類・活用事例

2023.09.21
DX(デジタルトランスフォーメーション)とは?今さら聞けない意味・定義を分かりやすく解説【2024年最新】

2023.11.24
【現役社員が解説】データサイエンティストとは?仕事内容やAI・DX時代に必要なスキル

2023.09.08
DX事例26選:6つの業界別に紹介~有名企業はどんなDXをやっている?~【2024年最新版】

2023.08.23
LLM(大規模言語モデル)とは?生成AIとの違いや活用事例・課題

2024.03.22
生成AIの評価指標・ベンチマークとそれらに関連する問題点や限界を解説
















