



メルマガ登録
-
テーマから探す
-
技術から探す
-
業界・事例から探す
-
関連トレンドから探す
テーマから探す
技術から探す
業界・事例から探す
関連トレンドから探す

当社のプロフェッショナルサービスでは、コンサルタント・データサイエンティスト・エンジニアが一体となって、企業の経営課題をデータドリブンで解決する包括的なサービスを提供しています。
プロフェッショナルサービスでは機械学習プロジェクトとして進むことが多く、簡略化したフローは以下のようになります。

図1 機械学習プロジェクトのフロー(本稿の対象:システム化フェーズ)
| フェーズ | 概要 |
|---|---|
| 企画 | プロジェクトにおける目的・ゴールを明確化する。 |
| 分析PoC | 機械学習モデルの構築と精度検証を行う。 |
| 実地検証 | 分析PoCで得られたモデルを実際の業務に試験的に適用し、ビジネス効果を実証する。ここで期待する結果が得られるとシステム化に移行する。 |
| システム化 | 機械学習モデルを含むシステムの本格開発を行う。 |
| 運用保守 | システムと機械学習モデルの精度を監視する。システム障害時やモデルの精度低下などが見られた場合は復旧および原因調査など改善策を実施する。 |
本記事では、このフローの中からシステム化フェーズにおけるデータ分析システム構築について、2回に分けて詳しくご説明いたします。後編にあたる今回は、「データ分析」と「データ可視化」をご紹介します。
データ分析システム全体の概要とデータ基盤について説明した前編はこちら。
なお、技術情報は2025年7月時点の内容に基づいています。
データ分析プロジェクトでは、リスクを減らすために事前に分析PoCを実施した上で、期待する効果が見込まれる場合に分析基盤構築のフェーズに移行します。システム化の段階では、すでに機械学習モデルの生成方法が決定している状態であることが一般的です。
そのため、システム化における主要な作業は、MLOps(Machine Learning Operations)の仕組みを構築することになります。MLOpsの仕組みを整備することで、時間経過や環境変化による機械学習モデルの品質劣化の検出や機械学習モデルの更新を素早くできるようになり、より長期間にわたって機械学習モデルを活用することが可能になります。
機械学習モデルの開発・運用に最適なAWSサービス群がAmazon SageMaker AIです。
Amazon SageMaker AIでは学習、推論、モデル管理などそれぞれの用途に最適化されたサービスが提供されており、機械学習に関わる一連のプロセスをスムーズに連携させられます。
Amazon SageMaker AIは以下のように多くのサービスがありますが、本記事ではこの中でも緑色背景のサービスをご紹介します。なお、次節以降では各AWSサービス名の接頭辞(Amazon)は省略して記載します。
| 用途 | サービス名 |
|---|---|
| 開発/実験 | Amazon SageMaker Studio |
| Managed MLflow on SageMaker | |
| Amazon SageMaker JumpStart | |
| Amazon SageMaker Canvas | |
| Amazon SageMaker Autopilot | |
| Amazon SageMaker Debugger | |
| 学習 | Amazon SageMaker Processing |
| Amazon SageMaker Training | |
| Amazon SageMaker HyperPod | |
| Amazon SageMaker Feature Store | |
| Amazon SageMaker Neo | |
| Amazon SageMaker RL | |
| Amazon SageMaker Data Wrangler | |
| 推論 | Amazon SageMaker Real-Time Inference |
| Amazon SageMaker Serverless Inference | |
| Amazon SageMaker Asynchronous Inference | |
| Amazon SageMaker Batch Inference | |
| Amazon SageMaker Inference Recommender | |
| 学習/推論など | Amazon SageMaker Pipelines |
| モデル評価/管理など | Amazon SageMaker Model Registry |
| Amazon SageMaker Model Monitor | |
| Amazon SageMaker Clarify | |
| Amazon SageMaker Model Card | |
| Amazon SageMaker Model Dashboard | |
| Amazon Augmented AI | |
| Amazon SageMaker Role Manager | |
| Amazon SageMaker Ground Truth |
分析システムの主な構成要素は以下のようになります。次節以降ではそれぞれの構成要素をご説明します。
| 構成要素 | 概要 |
|---|---|
| 実験環境 | データサイエンティストが新モデルの実験をする環境。ここで良い結果が得られたらシステムに組み込むことを検討する。 |
| 学習 | データ基盤で収集したデータを元に、機械学習モデルを生成・評価する。 |
| 推論 | 生成された機械学習モデルを元に推論結果を出力する。業務要件により、APIやバッチ処理、エッジコンピューティングといった形式で実行する。 |
| 運用 | 運用後のデータ品質や機械学習モデルの品質に変化がないかをモニターし、異常が見られた場合に対処する。 |
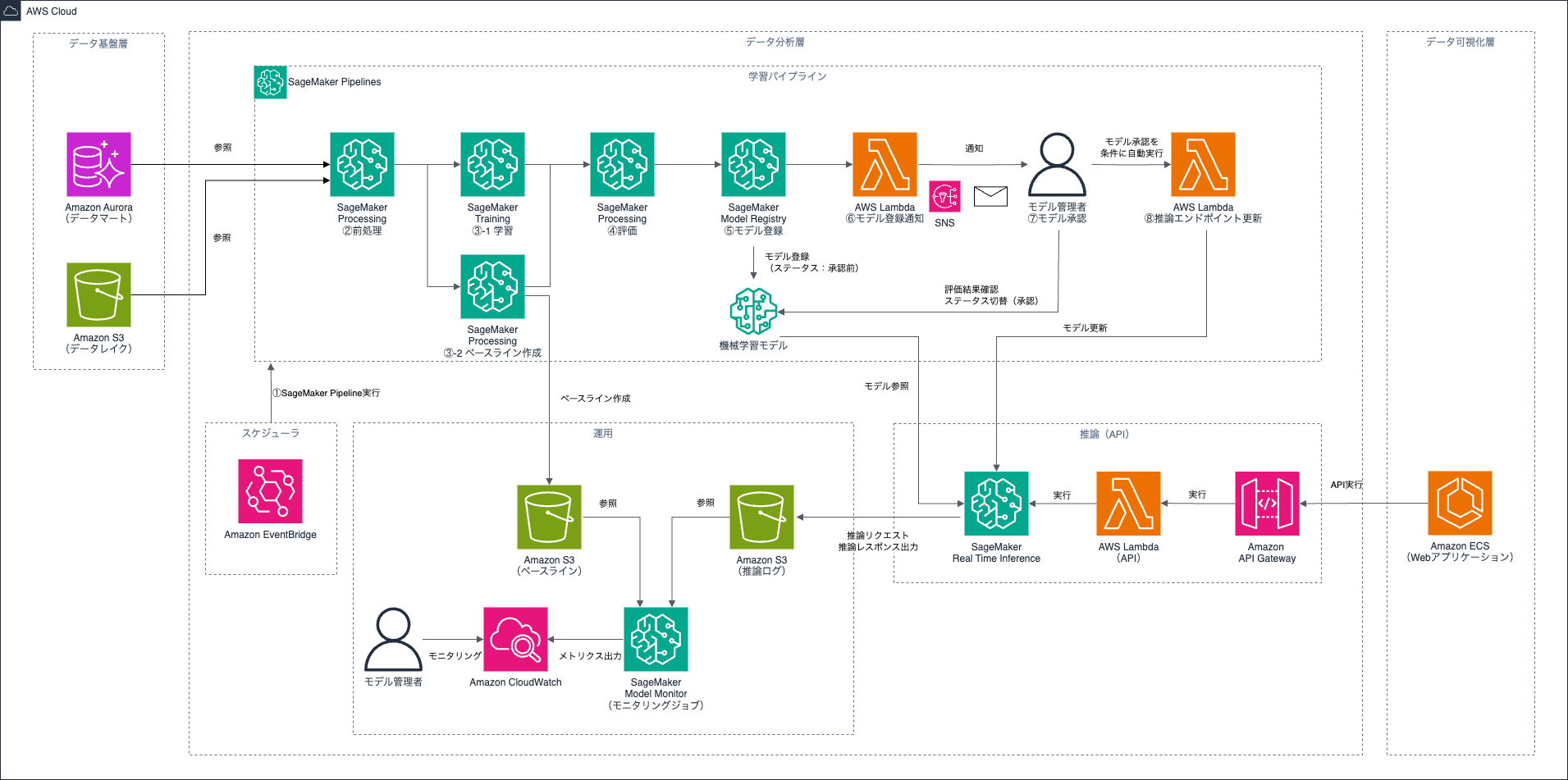
構成要素のうち、学習・推論・運用のアーキテクチャ例は図2のようになります。なお、図2では省略していますが、SageMaker Pipelinesのジョブ間のデータの入出力はAmazon S3を介して行われます。
実験環境は、主にデータサイエンティストが分析PoCフェーズにおいて、新たな機械学習モデルの作成と検証を行うために利用します。AWSで実験環境を構築する際の有力な選択肢として、SageMaker Studioがあります。
SageMaker Studioは機械学習向けのWebベースの統合開発環境(IDE)です。このツールを用いると、複数ユーザーでのノートブックや機械学習モデル・実験結果の共有ができるなど、チームでの実験環境の統一・運用が可能になります。
さらに、分析PoCフェーズにおいて、SageMakerの各種サービスと連携した開発を行っていると、システム化のフェーズに進む際、MLOpsの仕組みをスムーズに構築できるようになります。これにより、実験段階から業務適用への移行がより効率的になり、開発サイクルを短縮することが可能になります。
学習パイプラインとは、前処理から学習、モデル評価、モデル登録に至るまでの機械学習モデル生成に関わる一連の処理を指します。学習パイプラインを構築することで、定期的な機械学習モデル生成を自動化でき、機械学習モデルの運用効率が向上します。
特に機械学習モデルは、時間経過や環境変化によるデータ内容の変化(データドリフト)により推論結果が悪化する傾向にあります。データドリフトに対応するためにも、機械学習モデルの定期的な更新は重要なプロセスとなります。
AWSでの学習パイプライン構築に利用できる主要なAWSサービスとその特徴は以下の通りです。選定に当たってはパイプラインにSageMaker以外のサービスを組み込む必要があるかどうかが重要なポイントになります。SageMaker以外のAWSサービスの利用が限定的な場合、SageMaker Pipelinesを選択するとSageMakerのジョブ管理が容易になるためおすすめです。
| AWSサービス名 | 特徴 |
|---|---|
| SageMaker Pipelines | SageMakerに特化したパイプラインツール。SageMakerのみでパイプラインを構築する場合の有力候補。 |
| AWS Step Functions | AWSの様々なサービスを連携させることが可能。SageMaker以外のサービスもパイプラインに組み込む場合の有力候補。 |
| Amazon MWAA (Managed Workflows for Apache Airflow) | Apache Airflowを用いたツール。Apache Airflowでパイプラインを管理したい場合の候補。 |
図2のアーキテクチャ図を例に、SageMaker Pipelinesを使った学習パイプラインの実行〜機械学習モデルのデプロイの流れをご説明します。
1. SageMaker Pipelinesの実行
SageMaker Pipelinesの実行トリガーとしてAmazon EventBridgeを利用すると、定時実行だけでなくデータ蓄積、ソースコード更新など他のAWSサービスのイベント発生に応じた実行が可能です。データドリフト検出をトリガーにする場合は、CloudWatchメトリクスとCloudWatchアラート、AWS Lambdaなどを組み合わせて実装します。
2. 前処理
前処理ではSageMaker Processing Jobを利用します。データマートやS3から学習処理に必要なデータを読み込み、学習処理で必要な形式にデータを加工したり、データセットを分割(学習用・検証用・テスト用)します。
3-1. 学習
学習処理ではSageMaker Training Jobを利用します。前処理済みの学習用・検証用データセットを利用し、機械学習モデルを生成します。SageMaker Training Jobには、複数インスタンスによる並列学習や、ハイパーパラメータチューニング機能、SageMaker Model Registryとの連携など、学習処理に便利なオプションが用意されています。
3-2. ベースライン作成
ベースライン作成ではSageMaker Processing Jobを利用します。ここでのベースラインは、学習処理で利用した学習用データセットの統計情報を指します。作成したベースラインはS3に保管され、SageMaker Model Monitorを利用したモデルの品質管理やモニタリングの判定基準に活用されます。
4. モデル評価
評価ステップではSageMaker Processing Jobを利用します。学習処理で生成された機械学習モデルと前処理済みのテスト用データセットを用いて、機械学習モデルの性能を評価し、評価結果を出力します。
5. モデル登録
モデル登録では、機械学習モデルの評価結果・承認ステータス、推論時のインスタンスタイプなどとともにSageMaker Model Registryにモデルを登録します。初期状態では、承認ステータスを「未承認」となります。SageMaker Pipelinesでは、ConditionStepを設定することで、評価結果が特定の閾値を超えた場合のみモデルを登録させることも可能です。これにより、性能が不十分なモデルの誤デプロイを防止できます。
6. モデル登録通知
SageMaker PipelinesではLambdaステップを用いて任意のLambda関数を実行できます。図2の例ではLambda関数とAmazon SNSを組み合わせて、機械学習モデルの管理者にモデル登録の通知を行なっています。
7. モデル承認
通知を受けた機械学習モデルの管理者は、SageMaker Studioのコンソール画面から新旧モデルの評価結果を比較し、承認ステータスを「未承認」から「承認済み」に変更できます。人による最終確認は、自動的な指標確認だけでは検出できない問題を見抜くためにも重要なプロセスです。SageMaker PipelinesとSageMaker Model Registryを利用することで、そのようなモデル管理の連携がシームレスになります。
8. 推論エンドポイント更新・推論ログ設定
モデル承認を条件にLambdaステップを実行することで、機械学習モデルのデプロイを自動化できます。推論エンドポイント更新時に推論ログ設定を有効化すると、推論処理のリクエスト・レスポンスが保存され、SageMaker Model Monitorによるデータ品質・モデル品質のチェックに活用できます。
機械学習モデルをSageMakerのマネージドサービスを利用して推論させる場合、4つのサービスが利用できます。それぞれの概要と比較をまとめると以下のようになります。
推論オプションは、パフォーマンス要件、推論データサイズ、コスト要件などを基に選定します。例えば、オンラインの不正検出やストリーミングデータのリアルタイム分析などリアルタイム性が求められる用途では、リアルタイム推論が適しています。一方、BIツールでのレポート生成などリアルタイム性が求められないケースではバッチ変換が効果的です。
| リアルタイム推論(SageMaker Real-Time Inference) | サーバーレス推論(SageMaker Serverless Inference) | 非同期推論(SageMaker Asynchronous Inference) | バッチ変換(SageMaker Batch Inference) | |
|---|---|---|---|---|
| 概要 | API経由でリクエストを受け取り、即座に推論結果を返却 | リアルタイム推論と比較し、未使用時はコールドスタートとなり、コスト減・レイテンシー大。自動スケール。 | データを一括で推論する。ほぼリアルタイムに処理されるが、タイムアウト・推論データサイズに制限あり。 | 大量のデータを一括で推論 |
| 同期/非同期 | 同期実行 | 同期実行 | 同期/非同期実行 | 非同期実行 |
| レイテンシー | 秒以下 | 秒以下 | 数秒〜数分 (タイムアウト15分〜1時間) | 不定(タイムアウトなし) |
| 実行方法 | API | API | イベントベース | イベント/スケジュールベース |
| 推論データサイズの制限 | 6MB以下 | 6MB以下 | 1GB以下 | なし |
機械学習モデルを運用した後は、時間経過や環境変化によるデータ内容の変化(データドリフト)により推論結果が悪化する傾向にあります。そのため、機械学習モデルを継続的に監視し、必要に応じて再学習や改善を行うことは極めて重要です。システム化のフェーズにおいて、運用を見据えた監視の仕組みを構築すると、運用フェーズでの成功につながります。
SageMaker Model Monitorは、AWSが提供する機械学習モデルの運用監視サービスです。本番環境にデプロイされたモデルの入力データや予測結果を自動的に監視します。これにより、モデルの信頼性を維持し、ビジネス価値を継続的に提供することができます。
SageMaker Model Monitorは、4つの監視タイプを提供しており、監視したい内容に応じて使い分けることができます。
| データ品質 | モデル品質 | モデルバイアス | Feature Attributionドリフト | |
|---|---|---|---|---|
| 監視内容 | 欠損値・異常値・統計的なデータドリフト | モデル精度低下 | 性別・年齢などの属性ごとの偏り | 特徴量の寄与度の変化 |
| 正解ラベルの必要性 | 不要 | 必要 | 必要 | 不要 |
| 用途 | 入力データの異常、ドリフトの早期検知 | 精度監視、再学習タイミングの把握 | 公平性の維持、バイアス逸脱の発見 | 重要特徴量変化の発見、モデル挙動の長期監視 |
SageMaker Model Monitorの利用に最低限必要な設定は以下の3つです。
1. ベースラインの作成
ベースラインは監視の基準となる重要な要素であり、監視タイプごとに作成する必要があります。
2. 推論ログ取得
推論ログは推論処理のリクエスト・レスポンスを記録したものです。監視タイプごとに必要なログを保存します。特に、モデル品質・モデルバイアスといった、正解ラベルが必要な監視タイプを利用する場合は、SageMaker Ground Truthを使って人手で正解ラベルを付与するなど、正解ラベルの付与プロセスを組み込んだ上で、推論ログと紐づける必要があります。
3. モニタリングスケジュールの作成
モニタリングスケジュールは監視タイプの異常を検出するためのスケジュール設定です。この設定は基本的にシステム構築時にのみ行えば十分であり、モデルの再学習のたびに設定し直す必要はありません。毎時、一定時間ごとなど設定したスケジュールにしたがって、異常検出処理などが実行されます。スケジュールは、異常を検出するのに十分なデータが集まり、かつ問題を早期に検出できるよう計画することが重要です。
長期的な運用を考えると、上記設定に加え、以下の仕組みが整備されるとより安定運用に繋がります。
データ可視化層は、データ基盤層やデータ分析層を通じて、データマートに格納されたデータや推論結果を確認・分析するための層です。BIツールやWebアプリケーションが主に利用され、要件に応じて使い分けます。
BIツールは、データを可視化するダッシュボードを構築する場合の第一候補となります。Webアプリケーションは、ダッシュボード機能に加えて、特定の業務プロセスに合わせた画面設計や操作性のカスタマイズが必要な場合に適しています。
本節ではBIツールとWebアプリケーションの概要および関連するAWSサービスについてご説明します。
Amazon QuickSightは、AWSのマネージドサービスとして提供されるBIツールです。
Amazon QuickSightには以下のような特徴があります。
これらの特徴から、特にAWSを利用環境とした場合はQuickSightが推奨されます。
近年では、「Q in QuickSight」機能により、自然言語からダッシュボードが作成できるようになり、開発効率が大幅に向上しています。
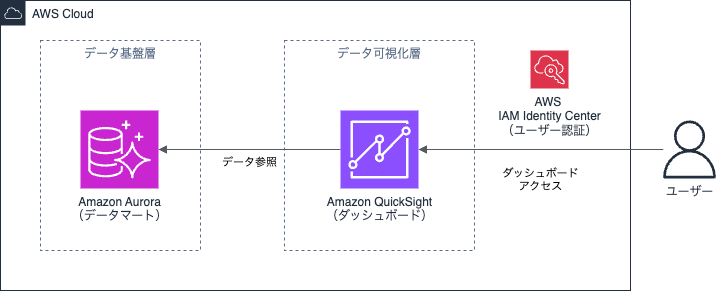
QuickSightのアーキテクチャ例は図3のようになります。QuickSightのユーザー管理方法は3通り(メールアドレス、AWS IAM Identity Center、Active Directoryとの連携)あります。図3の例ではAWS IAM Identity Centerを利用しており、この場合、他のAWSサービス含めたユーザーの一元管理ができ、運用効率・セキュリティ観点でのメリットがあります。
Amazon QuickSight以外のBIツールの例としては、Microsoft Power BI、Tableau、Google Lookerなどが挙げられます。これらのツールをAWS環境上で利用する場合は、サーバーの構築(※自ホストの場合)、認証・認可の設定、データにアクセスするためのネットワーク整備などセキュリティ面に配慮した環境構築が必要となります。
BIツールでは対応しきれない特殊な操作が必要な場合は、Webアプリケーションの開発が有効な選択肢となります。特にデータ分析に強いPythonを活用したWebフレームワークの代表例は以下の通りです。これらはいずれもPythonのみで開発可能なフレームワークであり、学習コストが比較的低く、迅速なプロトタイピングに適しています
| フレームワーク名 | 特徴 |
|---|---|
| Streamlit | 簡単・高速にWebアプリが作成可能。プロトタイプ向き。Dashと比較してカスタマイズ性が限定的である一方、開発が容易であることから近年急速に普及している。 |
| Plotly Dash | Streamlitと比較してより柔軟なカスタマイズが可能。Dash Enterprise(有償)を利用すると、デプロイ・セキュリティ関連の機能が強化できる。 |
AWS環境でこれらのWebフレームワークを活用する場合、主な選択肢として以下があります。中でもAamzon ECSは、運用の負荷が少なく、安定稼働が可能で、Amazon EKSと比べて学習コストが低いといった特徴から、Webアプリケーションの実行環境としておすすめです。
| AWSサービス名 | 概要 |
|---|---|
| Amazon ECS(Elastic Container Service) | AWS独自のコンテナオーケストレーションサービス |
| Amazon EKS(Elastic Kubernetes Service) | Kubernetesのマネージドサービス |
| AWS App Runner | コンテナアプリケーションを簡単にデプロイ&スケーリングできるフルマネージドサービス |
| Amazon EC2 | 仮想サーバーサービス |
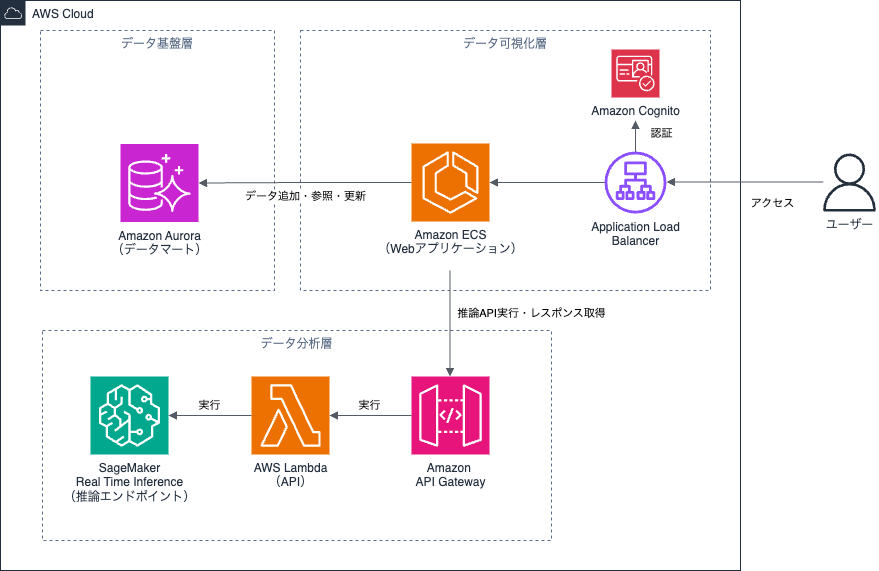
ECSを使用して、Webアプリケーションを動作させる際のアーキテクチャ例は図4のようになります。
図4の例では、Application Load BalancerとAmazon Cognitoを連携させることで、ユーザ認証を実現できます。この構成では、認証画面のカスタマイズは制限されますが、Webアプリケーションへの認証機能の実装が不要となるため、開発効率の向上につながります。
また、Webアプリケーションを活用すると、ユーザーの入力内容をもとにデータ分析層の推論APIを実行し、その結果を画面に表示するなど、BIツールでは対応困難な要件にも対応可能となります。
弊社では、アルゴリズムによる最適化・シミュレーション結果の可視化などを包括した「実験計画最適化ソリューション」、「生産計画最適化ソリューション」を提供しています。
データ活用ビジネスをすばやく開始したい場合は、ぜひ、お気軽にお声掛けください。
【参考記事】
実験計画最適化ソリューション|株式会社ブレインパッド(BrainPad Inc.)
生産計画最適化ソリューション|株式会社ブレインパッド(BrainPad Inc.)
本記事では前編・後編に分けて、小規模データ分析システムをAWS上に構築する際の全体像とデータ基盤・データ分析・データ可視化に分けたより具体的なアーキテクチャについて紹介しました。
ブレインパッドでは今回紹介したエンジニアリング領域だけでなく、DX推進に関わる企画〜運用まで一気通貫でサポートできます。DX推進にお困りの場合はぜひ弊社にお問い合わせください。
あなたにオススメの記事

2023.12.01
生成AI(ジェネレーティブAI)とは?ChatGPTとの違いや仕組み・種類・活用事例

2023.09.21
DX(デジタルトランスフォーメーション)とは?今さら聞けない意味・定義を分かりやすく解説【2024年最新】

2023.11.24
【現役社員が解説】データサイエンティストとは?仕事内容やAI・DX時代に必要なスキル

2023.09.08
DX事例26選:6つの業界別に紹介~有名企業はどんなDXをやっている?~【2024年最新版】

2023.08.23
LLM(大規模言語モデル)とは?生成AIとの違いや活用事例・課題

2024.03.22
生成AIの評価指標・ベンチマークとそれらに関連する問題点や限界を解説
















