



メルマガ登録
-
テーマから探す
-
技術から探す
-
業界・事例から探す
-
関連トレンドから探す
テーマから探す
技術から探す
業界・事例から探す
関連トレンドから探す

生成AIへの期待が高まる一方で、「モデルはできたのに使われない」「ROIを説明できない」といった声は後を絶ちません。なぜAIは、現場の業務や経営判断のなかで“当たり前の仕組み”になりきれないのでしょうか。その理由は、多くの場合、インフラやアルゴリズムではなく、「データの準備・運用・評価の仕組み」にあります。
この記事では、企業が直面しがちなPoC止まりの構造と、そこに潜む課題を明らかにしながら、データセントリックなAI基盤に求められる視点をご紹介します。

今、多くの企業の経営層が、CDO(最高デジタル責任者)やCIO(最高情報責任者)や、そのミッションを託されたデータ部門長、DX推進リーダーに、このような期待を寄せています。
かつてAIが「一部の専門家が使う高度な予測ツール」であった時代は終わりました。生成AIの登場により、AIは「全社員の生産性を向上させるパートナー」であり、「新たな顧客体験を創出するゲームチェンジャー」へとその姿を変えました。

経営者が生成AIに期待するもの
これらは、2~3年前までは日常業務では難しい技術だと思われていましたが、すでに実現すべき「ミッション」として現場に降りてきています。
しかし、その「ミッション」の理想とは裏腹の、高く険しい壁が立ちはだかっているのが現場の実情です。
ブレインパッドがデータ分析の専門家として、多くの企業のAIプロジェクトをご支援する中で目にしてきたのは、AI活用を本格化させようとする企業が必ず直面する、「2つの壁」の存在でした。

「PoCは成功した」、「ある事業部での検証デモは評価できる結果となった」こういった、現場の声は多く聞こえます。
しかし、それが全社的なビジネス価値に繋がっておらず、お金をかけてまで次のフェーズで大きく投資を行うべきかの判断がつかないこともしばしば。結果的に、多くのAIプロジェクトが、この「PoCの壁」に突き当たり、PoCを繰り返すだけの「PoC疲れ」に陥っています。
このような事態、現場で起きてないでしょうか。
これらはすべて、AIを作ることとAIで価値を生み出し続けること、つまりはPoCと本番運用の間に存在する高い壁が原因です。
特に生成AIの登場で、このもう一つの壁が深刻化しています。それは、リスク管理の課題です。AI活用のアクセルを踏みたい経営層と、リスクを懸念する現場との板挟みに陥っていないでしょうか。
このPoCの壁と、ガバナンスの壁という根深い課題に対し、クラウドベンダーやSIベンダーから、続々とAIネイティブ基盤の構築サービスが提供されています。
もちろん、GPUサーバー、Kubernetes(コンテナ技術)、高速なストレージといった最新の「インフラ」を整備することは重要です。
しかし、多くの現場で見てきたのは、高価な基盤を導入したにもかかわらず、
結果として、インフラを導入したこと自体がゴールとなり、「PoCの壁」や「ガバナンスの崖」を何ら解決できていないケースが多いのです。
AIの価値創出の本質は、「インフラ(箱)」を構築することではありません。 その「箱」の上で、いかにして「AIの価値」を継続的に、かつ安全に生み出し続けるかという良質なデータの仕組み(エコシステム)を設計することにあります。
では、なぜ多くのAIプロジェクトは、この本質的な「仕組み」の構築に失敗するのでしょうか? 次章では、我々データ分析のプロフェッショナルが見てきた、その失敗の根源にある「3つの質」の欠如について、深く掘り下げていきます。
なぜ、多くの企業が最新のインフラを導入し、優秀なデータサイエンティストを採用しても、「PoCの壁」を超えることができないのでしょうか。
原因は「AIモデル(アルゴリズム)」にあるのではなく、「データ」そのものにあるといえます。Google Brainを創設したリーダーでもあるアンドリュー・ン(Andrew Ng)氏が提唱するように、AI活用のトレンドは、モデルの精度を競う「モデル中心(Model-Centric)」から、AIに与えるデータの質を徹底的に高める「データ中心(Data-Centric)」へと明確にシフトしています。
どれほど高度なAIモデル(例えばGPT-5や最新の予測アルゴリズム)を用いたとしても、学習させるデータが不正確であったり、偏っていたり、古かったりすれば、そのAIが生み出すアウトプットの価値はゼロ、あるいはマイナス(誤った判断の誘発)にすらなり得てしまうのです。
ここまでで整理した「PoCの壁」や「ガバナンスの崖」といった問題の根底には、この「データ」を軽視し、AIの「モデル」や「インフラ」ばかりに注目してしまった結果、直面する「3つの質の欠如」が生まれてしまうことがあります。
PoC(実証実験)から本番運用(MLOps:機械学習基盤の運用)へと移行するプロセスには、「魔の川」と呼ばれるほどの深い断絶が存在します。我々は、多くの企業がこの川を渡れずにいる現場を目の当たりにしてきました。
その失敗の本質は、以下の3つの「質」を担保する仕組みが、組織的にも技術的にも欠如している点に集約されます。
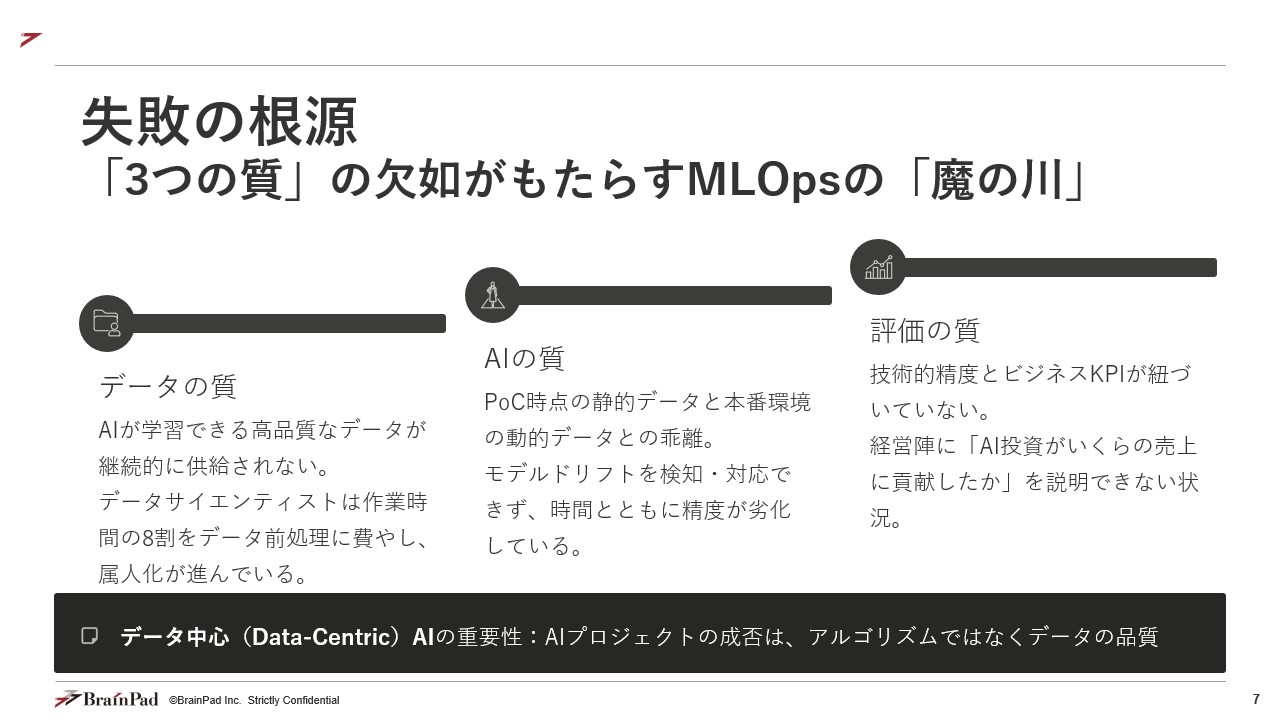
ある製造業では、高精度な需要予測AIのPoCに着手しました。データサイエンティストは、基幹システム(ERP)から「過去の出荷実績データ」、営業部門のExcelから「案件管理データ」、マーケティング部門から「キャンペーン履歴データ」を必死で収集・統合しました。
データを集めるだけで1ヶ月。各データで「製品コード」の定義が異なり、その名寄せ(クレンジング)作業にさらに1ヶ月を要しました。(データのサイロ化)
このデータ前処理(AIが学習できる形への加工)は、担当したデータサイエンティストA氏のPC内でのみ行われ、そのロジックはA氏の頭の中にしか存在しない「秘伝のタレ」となりました。(属人化)
結果
PoCは成功しましたが、いざ本番運用しようとした際、A氏が異動。後任者は「秘伝のタレ」を解読できず、リアルタイムで更新されるデータをAIに供給する仕組み(データパイプライン)を構築できませんでした。プロジェクトは事実上、塩漬けとなりました。
これは「データの質」を、特定の個人のスキル(属人技)に依存した結果の典型的な失敗です。AIの価値を継続的に生むには、「AIが使いやすい高品質なデータ(=特徴量)」を、「属人性を排除し、組織的に、かつ継続的に供給し続ける仕組み」が不可欠です。
あるECサイト運営企業が、「過去1年分」の購買履歴データを使い、顧客の閲覧傾向から「おすすめ商品」を提示するAIモデルを開発しました。PoCではクリック率(CTR)が既存ロジックより20%向上するという素晴らしい結果が出ました。
意気揚々と本番環境に実装した3ヶ月後、事件が起きます。テレビ番組で紹介されたある商品が爆発的にヒットし、顧客の閲覧パターンがPoCの時(過去1年分のデータ)とは全く異なるものになりました。(環境の乖離)
しかし、AIモデルは「過去の静的なデータ」でしか学習していません。この急激なトレンド変化(データドリフト)を検知できず、AIは的外れな「過去の売れ筋商品」を推奨し続け、CTRはPoC時を大幅に下回り、既存ロジック以下にまで悪化しました。(モデルの劣化)
結果
現場はAIの利用を停止。「AIは使えない」という烙印が押され、経営層はAI投資に懐疑的になりました。
これは「AI(モデル)の質」を、”作った時点”で固定化してしまった失敗です。AIモデルは「作って終わり」ではなく、「本番環境での性能劣化を常に監視し、変化に対応して自動的に再学習・更新され続ける仕組み」(=MLOps)がなければ、すぐに「使えないAI」へと劣化していきます。
ある金融機関が、不正取引を検知するAIモデルを開発しました。技術チームは「不正検知の精度(Accuracy)99%」というPoC結果をCDOに報告しました。
CDOは経営会議でこの成果を報告しましたが、CEOから「素晴らしい。で、そのAIは、我が社の損失(不正被害額)を年間いくら減らしてくれるのかね?」と問われ、絶句しました。(技術評価とビジネス評価の乖離)
「精度99%」という技術的な指標(KPI)が、経営が知りたい「被害額の削減」や「誤検知による優良顧客の取引停止リスク」といったビジネス上の指標(KPI)と全く紐づいていなかったのです。(ROIの説明不可)
結果
CDOはAI投資のROI(投資対効果)を説明できず、全社展開への追加予算を獲得できませんでした。AIプロジェクトは「技術的には成功したが、ビジネス的には価値不明」として、PoC止まりとなりました。
これは「評価の質」を、技術者の視点でしか設計しなかった失敗です。AIプロジェクトは、企画段階から「AIの技術的精度が、最終的にどのビジネスKPI(売上、コスト、顧客満足度など)にどう貢献するかを測定・可視化する仕組み」を設計に組み込んでおかなければ、経営層を説得し、継続的な投資を引き出すことはできません。
これら3つの「質」の担保の失敗こそが、第1章で述べた「PoCの壁」の正体です。 そして、この「質」を管理・統制する仕組みの欠如が、そのまま「ガバナンスの崖」――すなわち、品質が担保されないデータ利用のリスク、性能が劣化したAIが引き起こすリスク、ROIが不明なままコストだけが膨らむリスク――へと直結しているのです。
では、これらの失敗を回避し、「3つの質」を組織的かつ継続的に担保するためには、AIネイティブ基盤にどのような「設計思想」が求められるのでしょうか。 次章では、その具体的な解決策(アーキテクチャ)を提言します。
前章で詳述した「3つの質」の課題は、個々のデータサイエンティストの努力や、高性能なインフラの導入だけでは決して解決できません。これらの課題は、AI開発の初期段階(データ準備)から最終段階(ビジネス価値の評価)まで、一気通貫で「質」を担保する『仕組み(アーキテクチャ)』が基盤側に欠如していることに起因します。
データ分析の最前線で得た知見に基づき、これからのAIネイティブ基盤に不可欠な、「3つの質」を担保するための設計思想と、その中核となるコンポーネントを提言します。

前章で紹介したデータのサイロ化や属人化された前処理によるデータ品質の課題の根本原因は、AIが学習するために加工された高品質データが、個人の成果物になっており、組織の成果物(資産)になっていないという構造的な問題にあります。
これを解決するのが、「特徴量の一元管理と再利用」という設計思想です。
価値
当社の提言
多くのSIベンダーは「データレイク(単なるデータの湖)」の構築を提案しますが、当社は「フィーチャーストア」の構築こそが、「データの質」を組織的に担保する鍵であると考えます。これは、AIがすぐに飲める“湧き水”のような働きをすることにまいります。
データ変化(ドリフト)に対応できず、AIモデルが劣化・陳腐化するという課題がありました。この課題の根本原因は、AIモデルを「一度作ったら完成」と捉え、その「鮮度」を管理する仕組みがない点にあります。AIモデルは生鮮食品と同じであり、時間と共に劣化します。
これを解決するのが、「AIモデルの継続的な品質監視と自動更新」という設計思想です。
これは、本番環境で稼働しているAIモデルの「健康状態」を監視する仕組みです。
第2章のECサイトの例にあったような、急激なトレンド変化(=データドリフト)や、AIの予測精度が徐々に低下していく現象(=モデルドリフト)を自動で検知し、即座にアラートを発します。これが「AIの質」を維持するための“早期警告システム”となります。
これは、「AIの質」を維持・向上させるための“自動化された再循環システム”です。
価値
モデル監視アラートをトリガーに、「最新データの収集」→「自動再学習」→「品質テスト」→「新モデルの本番デプロイ」という一連のサイクルを自動実行します。
これにより、第2章のECサイトの例のようにAIが陳腐化する前に、常に最新のトレンドを学習したモデルに自動で入れ替わり、AIの品質(=鮮度)が継続的に担保されます。
当社の提言
「MLOps」とは単なるツールの導入ではありません。それは、AIの「劣化」を前提とし、「常にAIの品質を監視し、自動で再学習・更新し続ける」という運用サイクル(エコシステム)を基盤に組み込むという“設計思想”そのものです。
AIの「技術的精度(Accuracy)」が、経営が求める「ビジネス価値(ROI)」と紐づいていない、という課題がありました。この課題の根本原因は、AIプロジェクトの「ゴール設定」が間違っている点にあります。ゴールは「高精度なモデルを作ること」ではなく、「ビジネス成果を上げること」です。
これを解決するのが、「AIのビジネス貢献度の可視化と科学的な効果検証」という設計思想です。
これは、AIの技術的成果とビジネスの最終成果を、一つの画面で紐づけて可視化する仕組みです。
「評価の質」の担保の難しさの例として挙げた金融機関で言えば、「不正検知AIの精度(Accuracy)」だけでなく、「AI導入前後の実際の不正被害額(円)」や「誤検知による顧客クレーム件数」を並べて表示します。
これにより、CDOやその右腕層は、CEOからの「AIはいくら儲かったのか?」という問いに対し、データ(事実)に基づいた回答をすることが可能になります。
これは、AIの真のビジネス価値を「科学的に証明する」ための仕組みです。
価値
当社の提言
AIのROIを説明できないことは、AIプロジェクトにとって致命的です。「AIの精度」だけを追いかける自己満足なPoCを卒業し、「ビジネスKPIを測定し、A/Bテストでその価値を証明する」ことこそが、「評価の質」を担保し、経営層からの継続的な投資を勝ち取るための王道です。
これら「3つの質」を担保するアーキテクチャこそが、PoCの壁を超えるための技術的な土台となります。 しかし、どれだけ優れた仕組み(基盤)を構築しても、それを使う「ルール」や「体制」がなければ、宝の持ち腐れとなり、第1章で述べた「ガバナンスの崖」に転落してしまいます。
後編では、この高性能なAI基盤のアクセルを安全に踏み込むための「戦略的AIガバナンス」について論じます。
あなたにオススメの記事

2023.12.01
生成AI(ジェネレーティブAI)とは?ChatGPTとの違いや仕組み・種類・活用事例

2023.09.21
DX(デジタルトランスフォーメーション)とは?今さら聞けない意味・定義を分かりやすく解説【2024年最新】

2023.11.24
【現役社員が解説】データサイエンティストとは?仕事内容やAI・DX時代に必要なスキル

2023.09.08
DX事例26選:6つの業界別に紹介~有名企業はどんなDXをやっている?~【2024年最新版】

2023.08.23
LLM(大規模言語モデル)とは?生成AIとの違いや活用事例・課題

2024.03.22
生成AIの評価指標・ベンチマークとそれらに関連する問題点や限界を解説
















