メルマガ登録
-
テーマから探す
-
技術から探す
-
業界・事例から探す
-
関連トレンドから探す
テーマから探す
技術から探す
業界・事例から探す
関連トレンドから探す

ブレインパッド アナリティクスコンサルティングユニットの梅田です。この記事では、ここ5~6年で登場した比較的新しいレコメンデーション技術のトレンドを分かりやすくご紹介します。
私たちブレインパッドのデータサイエンティストは、お客様の多様なビジネス課題を解決するため、日々新しい技術の探求と検証を重ねています。中でもレコメンデーション技術は、顧客体験の向上や売上拡大に直結する重要な分野であり、その進化スピードは非常に勢いがあります。
そこで今回は、レコメンデーション領域における知見を深め、より良いご提案に繋げることを目指し、近年の主要な手法を調査・整理しました。レコメンデーション技術の現状を掴む一助となれば幸いです。

古典的な協調フィルタリングも依然として有効ですが、近年のレコメンデーション技術は深層学習の登場により、その精度を飛躍的に向上させました。
この精度の向上を支えているのが、ユーザーとアイテム(商品、映画、音楽など)の情報を「ベクトル」として表現するアプローチです。それぞれの情報をベクトル化し、その内積などを計算することで、ユーザーがアイテムを購入・クリックする確率を予測します。このような設計は、特に深層学習モデルで非常に扱いやすいという利点があります。
レコメンデーションモデルにはいくつか種類がありますが、その違いは主に「ユーザーやアイテムの情報をどのようにベクトル化するか」という点にあります。
本記事では、以下の代表的な4つのモデルを取り上げます。
この中で行列分解は、深層学習が普及する以前から存在するモデルですが、現在でも深層学習モデルに匹敵する高い性能を誇ります。他の3つは、深層学習の発展と共に進化してきたモデルです。特に自己教師あり学習モデルは、GNNをベースに対照学習などを取り入れた比較的新しいアプローチで、性能も一段高くなっています。
今回ご紹介するモデルは、いずれも「一般化協調フィルタリング」に分類されます。ユーザーとアイテム情報のみを利用するモデルという意味です。付加情報を活用したモデルについては、「付加情報を活用したモデル」のパートで紹介します。
行列分解は、古くからある協調フィルタリングの一手法ですが、その最適化された実装は、パーソナライズドレコメンデーションの分野で唯一、最新の深層学習モデルと互角に渡り合えるポテンシャルを秘めています。ここではその代表格となるiALS※1を紹介します。
※1 iALS++ https://arxiv.org/abs/2110.14044
まずはオリジナルのiALSについて説明します。
表1:N_ijの例
| N_ij | j=1 | j=2 | j=3 | j=4 |
| i=1 | 0 | 1 | 0 | 0 |
| i=2 | 1 | 0 | 1 | 0 |
| i=3 | 0 | 0 | 1 | 1 |
表2:u_i、v_jの例。表1のN_ijが近似的に再現されます。
| 要素1 | 要素2 | 要素3 | |
| u_1 | -0.54 | 0.60 | 0.32 |
| u_2 | 0.78 | -0.06 | 0.41 |
| u_3 | 0.02 | 0.82 | -0.38 |
| v_1 | 0.78 | 0.28 | 0.66 |
| v_2 | -0.49 | 0.49 | 0.89 |
| v_3 | 1.16 | 1.04 | 0.04 |
| v_4 | 0.38 | 0.76 | -0.62 |
上記の最適化の際、交互最適化(ALS)を用います。これは、Uステップ(すべてのv_jを止めてu_iを最適化する)とVステップ(すべてのu_iを止めてv_jを最適化する)を繰り返します。iALSが現在でも使われるのは、下記により処理速度・性能共に大幅な改善が出来たからです。
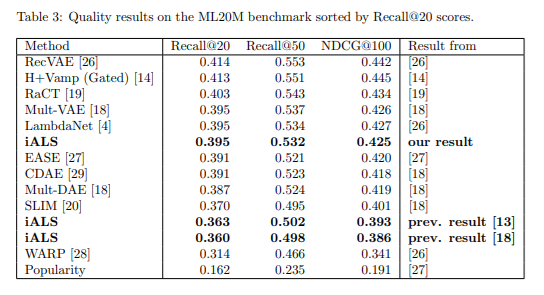
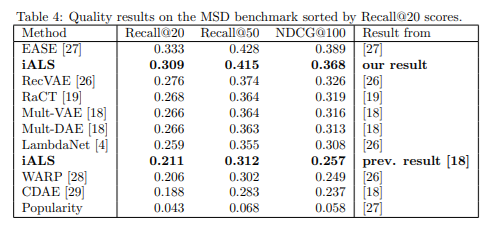
iALSは線形モデルですが、シンプルさと高いスケーラビリティから、今でも多くの場面で強力なベースラインとなります。論文※2の修正を行ったモデルの精度は表3-4の様になります。このモデルでは、ユーザーの属性(年齢・性別など)やアイテムカテゴリ等、豊富なサイド情報をモデルに組み込むのは難しくなっています。コールドスタート問題もありますが、ユーザー側は過去の行動ログから擬似的に特徴ベクトルを作成するなどの対策が可能です。新規アイテムへの推薦は、どのモデルでも困難であり、特にiALSだけの問題とは言えません。対処方法としては、類似アイテムやカテゴリ別の予測を行い、これらの結果を参考に一定確率(割合)で新規アイテムのレコメンドを行うなどがあると思います。
※2 iALS正則化項の改善 https://arxiv.org/abs/2110.14037
表3:iALSの精度その1
表4: iALSの精度その2
行列分解が線形的な関係性のモデル化を得意とするのに対し、より複雑で非線形なユーザーの好みを捉えるために登場したのが、VAE(変分オートエンコーダ)をベースとしたアプローチです。このモデルを単純化(非線形関数無し)した場合、行列分解を深層学習の考え方で発展させたモデルと捉えることができます。
このアプローチでは、まずユーザーごとにアイテムの購入履歴をベクトル(購入したアイテムは1、それ以外は0)で表現します。このベクトルをオートエンコーダに入力します。エンコーダでは、入力ベクトルを低次元(例えば200次元)の正規分布(平均ベクトルと分散ベクトル)として表現します。このベクトルをデコーダが受取り、元のアイテム選択の確率を復元するように学習を進めます。このプロセスを通じて、モデルはユーザーの潜在的な好みを学習し、最終的にはユーザーが次に購入する可能性が高いアイテムの確率を出力できるようになります。ユーザーが購入した商品以外で購入確率の高いアイテムが推薦候補となります。一部の購入アイテムを隠して、それを再現する形での学習もあります。
損失関数は、2つの部分から構成されます。
この一連の学習を通じて、モデルはユーザーがまだ購入していないアイテムの中から、次に購入する可能性が高いアイテムを予測できるようになります。
代表的なモデルの一つはMult-VAEです。再構築誤差の損失関数に多項分布(Multinomial distribution)を用いることからこの名で呼ばれています。ユーザーの嗜好を確率的に捉える生成モデルとして高い性能を示しました。
※3 Mult-VAE https://arxiv.org/abs/1802.05814
RecVAEは、2020年に発表されたMult-VAEの改良版モデルです。実験ではMult-VAEや、それと同程度の性能である行列分解系モデル iALS++を上回る精度を達成しました。
※4 Rec VAE https://arxiv.org/abs/1912.11160
RecVAEでは、主に以下の点が改良されています。
ここでは、ユーザーとアイテムの複雑な関係性をグラフとして捉え、深層学習で分析するGNN(グラフニューラルネットワーク)ベースの推薦モデルを紹介します。
このモデルでは、まず「ユーザー」と「アイテム」を、それぞれグラフの「頂点(ノード)」と見なします。そして、ユーザーによる購入やクリックといった行動はノード間を結ぶ「辺(エッジ)」として表現します。これにより、「誰が」「何に」興味を持っているかという関係性のネットワークが、一つの巨大なグラフとして可視化されます。
GNNの最大の特徴は、各頂点が自身の情報を更新する際に、辺で繋がっている隣の頂点の情報を集約する点にあります。これを層状に繰り返すことで、例えばあるユーザーの頂点には、その人が買ったアイテムの情報や、「同じアイテムを買った別のユーザー」の情報が段階的に組み込まれていきます。このプロセスを通じて、単なる個別の行動履歴だけでは見えなかった、より複雑な関係性を捉えることができます。
この学習プロセスを通じて、最終的にすべてのユーザーとアイテムは、それぞれの特徴を凝縮した「埋め込みベクトル」と呼ばれる数値のリストに変換されます。このベクトルがあれば、特定のユーザーとアイテムのベクトルの近さ(類似度)を内積などの簡単な計算で求めるだけで、そのユーザーがそのアイテムをどれだけ好みそうかを予測し、推薦スコアとして利用できます。
GNNモデルのもう一つの強みは、その柔軟性です。ユーザーやアイテムだけでなく、例えば「スポーツ」や「ファッション」といったカテゴリ情報なども新たなノードとして定義し、関係性をエッジで結ぶことで、多様なデータを比較的簡単にモデルへ組み込むことができます。
ある層におけるユーザーの埋め込みベクトルは、一つ前の層での、自分自身のベクトルと、リンクするノードの関数として更新されます。この計算を層の数だけ繰り返すことで、ユーザーのベクトルには、その人の好みを反映したアイテムの情報が効果的に集約されます。
学習の目標は、あるユーザーのベクトルを、「その人が実際に購入したアイテム」のベクトルに近づけ、同時に「購入していないアイテム(学習のためにランダムに選んだもの)」のベクトルからは遠ざけることです。具体的には、(ユーザーと購入済みアイテムの距離)が、(ユーザーと未購入アイテムの距離)よりも一定の差(マージン)だけ近くなるようにモデルを訓練します。この手法は「ペアワイズ学習」と呼ばれ、代表的な損失関数にBPR Lossなどがあります。
モデルの性能を最大限に引き出すには、下記のような設定値(ハイパーパラメータ)の調整が不可欠です。
LightGCNは、2020年にGoogleから提案された、推薦システムに特化したグラフニューラルネットワーク(GCN)モデルです。その名の通り、従来のGCNから複雑な要素を削ぎ落とし、軽量(Lightweight)な構造にした点が最大の特徴です。
※5 lightGCN https://arxiv.org/abs/2002.02126
このモデルの設計思想はシンプルイズベストです。まず、グラフ構造として「ユーザー」と「アイテム」の2つのグループのみで構成される「二部グラフ」を採用します。そして、ユーザーがアイテムを購入・クリックしたといった関係性のみをグラフの「辺(エッジ)」として結びます。
多くの推薦モデルが活用するユーザーの年齢・性別や、商品のカテゴリといった付加的な特徴量を一切使用しません。この大胆な単純化が、LightGCNの核心の一つです。
さらに、従来のGCNモデルにおける中核的な処理であった、以下のような複雑な計算をすべて排除しました。
これらの要素を取り払ったことで、LightGCNは非常にシンプルで効率的な「線形モデル」となり、高い性能を保ちながらも計算コストを大幅に削減することに成功しました。
LightGCNの学習プロセスは、そのシンプルさを反映しています。
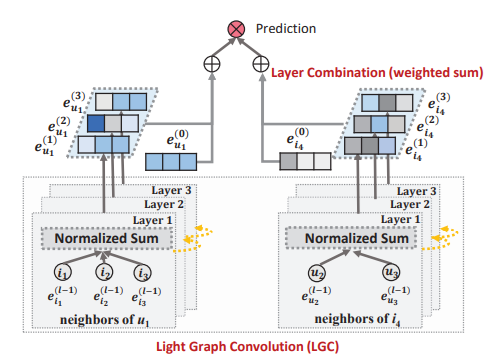
図1はLightGCNの構造をまとめたものです。次のステップ1の様に初期化し、2、3により予測が合うように学習を進め、4の様に使います。
LightGCNは、その極めてシンプルな構造にもかかわらず、非常に高い推薦精度を発揮します。実験では、より複雑な構造を持つ他のGCNベースのモデルを上回り、Mult-VAEよりも優れた性能を示すことが報告されています。その精度は、高性能なモデルとして知られるRecVAEに匹敵しています。効率性と推薦効果の両立を実現した、強力なモデルの一つと言えます。
近年、レコメンドモデルでは自己教師あり学習(SSL、Self-Supervised Learning)というアプローチが大きな注目を集めています。
自己教師あり学習は、これまでレコメンデーションモデルの精度向上を妨げてきたスパース性とノイズという2つの課題を解決する力を持っています。
SSLは、データ拡張によって学習に有益な疑似データを自ら生成することで、スパースな元データを補強します。さらに、一貫したパターンを持つ関係性を重視して学習するアルゴリズムとすることで、誤クリックのような偶発的なノイズの影響を受けにくくなり、より本質的なユーザーの好みを捉えることが可能になります。
ここでは、このSSLを用いた代表的なモデルの一つであるAutoCFを紹介します。
※6 AutoCF https://arxiv.org/abs/2303.07797
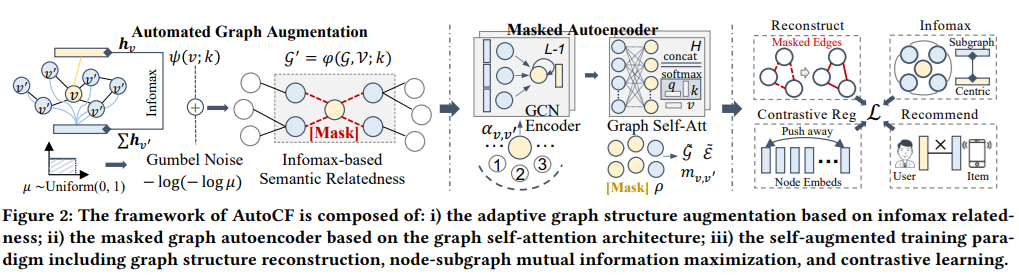
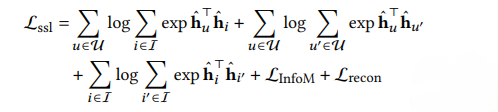
上記の自己教師あり学習の損失関数と、レコメンデーションの損失関数を連結させて、AutoCFモデルの損失関数とします。3項目は正則化項です。
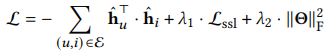
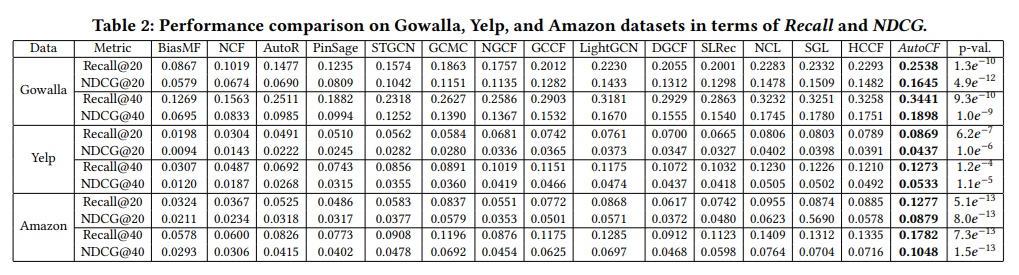
このようなモデル構造により、AutoCFは2023年時点では最高レベルの精度を達成しました。下の表5が代表的なモデル間での精度比較です。右側5列が自己教師あり学習ベースのモデルとなっています。
表5:AutoCFの精度
ここまででユーザーとアイテム情報のみを利用する「一般化協調フィルタリング」モデルを紹介しました。ここでは、付加情報を活用したモデルを紹介します。
この章では4つの付加情報を使うモデルを紹介しました。これらのモデルについても、自己教師あり学習モデルによる精度向上が可能です。
ここ5~6年でレコメンドモデルの精度は大幅に向上しています。MFベースのモデルでも、改良を加えたモデルであれば、最新の深層学習モデルに大きく劣らない精度となっています。また、利用も容易です。
近年精度の高いモデルは、自己教師あり学習ベースのモデルとなっています。AutoCFについては、データ拡張も自動であり、またソースコードも公開されています。今後は、自己教師あり学習を用いたレコメンドモデルの活用も進んでいくのではないかと思います。
あなたにオススメの記事

2023.12.01
生成AI(ジェネレーティブAI)とは?ChatGPTとの違いや仕組み・種類・活用事例

2023.09.21
DX(デジタルトランスフォーメーション)とは?今さら聞けない意味・定義を分かりやすく解説【2024年最新】

2023.11.24
【現役社員が解説】データサイエンティストとは?仕事内容やAI・DX時代に必要なスキル

2023.09.08
DX事例26選:6つの業界別に紹介~有名企業はどんなDXをやっている?~【2024年最新版】

2023.08.23
LLM(大規模言語モデル)とは?生成AIとの違いや活用事例・課題

2024.03.22
生成AIの評価指標・ベンチマークとそれらに関連する問題点や限界を解説