



メルマガ登録
-
テーマから探す
-
技術から探す
-
業界・事例から探す
-
関連トレンドから探す
テーマから探す
技術から探す
業界・事例から探す
関連トレンドから探す

レコメンデーション技術は、顧客体験の向上や売上拡大に直結する重要な分野ですが、近年は大規模言語モデル(LLM)の台頭により、従来の「IDによるマッチング」という常識を覆し、アイテムの「意味(セマンティック)」を理解して提案を行う「生成型推薦(Generative Recommendation)」という全く新しいパラダイムへのシフトが起きています。
そこで今回は、この凄まじいスピードで進化するレコメンデーション領域の知見を深め、より高度なご提案に繋げることを目指し、3つの最新の生成型推薦の事例をご紹介 します。言語モデルと同様に、次の単語(トークン)を当てるという意味での大規模深層学習を用いた推薦モデルが 2例、GPTを用いたAIエージェントシステムが 1例になります。レコメンド技術の現在地とさらなる可能性を掴む一助となれば幸いです。

レコメンド技術はこれまで、その目的やデータの性質、扱うコンテキストに応じて多角的に発展してきました。RecBole※1によるレコメンドモデルの分類は下記のとおりです。
※1:中国の研究機関によって、複数のレコメンド手法をまとめて性能比較できるように作られた、レコメンドモデルのオープンソースが集まっているプロジェクトのことです。リンクはこちらです。
一部のアルゴリズムの詳しい内容は深層学習が変えたレコメンデーション技術:主要モデルの潮流とは | DOORS DX でも解説しています。
これらのアルゴリズムの変遷は、モデルの表現能力の進化と同期しており、大きく二つの世代に分けることができます。
しかし、これら第1・第2世代の手法は、推薦を識別的なスコアリングとして扱っているため、意味的な知識の活用に限界がありました。また、データスパースネスに起因するコールドスタート問題や、人気アイテムへの過度な偏り(ポピュラリティ・バイアス)といった、推薦の本質的な課題を抜本的に解決するまでには至っていませんでした。
近年、大規模言語モデル(LLM)の台頭は、これらの問題を「ID依存からの脱却」という形で解決しつつあります。これが「生成型推薦(Generative Recommendation)」と呼ばれる新たなパラダイムです。このパラダイムによって引き起こされた進化をデータレベル・モデルレベル・タスクレベルで分けてまとめました。
データ側面では、従来の推薦システムが依存していた「ID」によるマッチングから脱却し、LLMが持つ膨大な知識を基盤とした「セマンティック(意味的)な理解」が可能になりました。これにより、履歴データが全く存在しない新規ユーザーや新アイテムに対しても、そのテキスト情報や文脈から直接好みを推論できる「コールドスタート問題の克服」が実現しています。具体的には、LLMを用いてユーザーの潜在的な意図を推論したり、不足しているインタラクションを擬似的に合成したりすることで、データの希薄さを能動的に補完できるようになりました。
モデル側面では、推薦という課題を「単語を生成するプロセス」として再定義したことで、従来の識別型モデルでは到達できなかった高度な柔軟性が備わりました。アイテムを単なる記号ではなく、意味的な情報を保持したトークンとして扱うことで、LLMの推論能力を推薦エンジンとして直接活用できるようになっています。このアプローチにより、アイテム間の表層的な関連性だけでなく、より深いセマンティックな依存関係を捉えた高精度な予測が可能です。また、モデル規模を拡大させる「スケーリング則」によって、より大規模で複雑なユーザー行動パターンを正確にモデル化する道が開かれました。
タスク側面においては、推薦の結果を単なるリストとして提示するのではなく、高度な「説明可能性」と「対話能力」を兼ね備えた体験を提供できるようになりました。LLMの推論能力を活かし、なぜそのアイテムが最適なのかという論理的な理由を、ユーザーが納得できる自然な言葉で解説することが可能です。加えて、リアルタイムで多段階のやり取りを行う「対話型推薦」が実現したことで、ユーザーは曖昧な要望を言葉で伝え、システムとの対話を通じて自身のニーズを洗練させたり、結果を即座に修正したりできるようになりました。これにより、推薦システムは受動的なツールから、ユーザーの意図を汲み取る知的な対話型アシスタントへと進化を遂げています。
【参考】
A Survey on Generative Recommendation: Data, Model, and Tasks
ここからは、Generative Recommendationに分類される手法の中から代表的な 3つのモデルを紹介 します。社会実装への容易性を考えて、企業が開発に関与していて、なおかつオープンソースとしてモデルを提供している手法に限定して選出 しました。また、gitのスターがなるべく多いものから選出 しています。
DeepMindが2025年に発表したモデルになります。(論文はこちら)
これは、アイテムをIDからセマンティック・トークンへ昇華させるアプローチを採用しており、前章の「モデルレベルでの進化」に該当します。従来の推薦システムは、アイテムを「ID」という無機質な記号として扱ってきました。しかし、同じアイテムでも「何と一緒に検討されているか」でその意味は変わります。このActionPieceでは、アイテムを周囲の行動履歴(文脈)に応じて形を変える「可変なトークン」として定義し直すことで、推薦における言語的アプローチを提案しました。
技術的特筆点は、NLPのサブワード化技術(BPE)を推薦ドメインへ拡張した点にあります。単一アイテム内の特徴量だけでなく、隣接するアイテム間での共起頻度に基づき、文脈そのものを一つの新しい「セマンティック・トークン」として結合します。これにより、モデルはデータ表現レベルで深い文脈を読み取ることが可能になりました。
※2 Amazon上に実際に投稿された、カスタマーレビューや商品メタデータをまとめたデータセットのこと。
こちらにソースコードが公開されています。
LLMをバックボーンに据えつつ、AmazonデータセットでFineTuningしてモデルを作成しています。手元の環境で動かすにはGPUが必要です。
Metaが2024年に発表したモデルになります。(論文はこちら)推薦専用のLLMであるLRM(Large Recommendation Models)を作成する手法であり、前章の「モデルレベルでの進化」に該当します。LLMがモデルサイズの拡大に伴い性能を向上させたように、推薦でも「スケーリング則」は成立するのかという疑問から生まれたのがHSTUです。汎用Transformerの流用ではなく、超大規模・非定常・長尺という推薦データ特有の性質に特化した専用アーキテクチャを構築することで、数兆パラメータ規模への道筋を付けました。
技術的特筆点は、Softmaxベースのアテンションを廃止し、「Pointwise Aggregated Attention」を採用したことです。これにより、ユーザーのアクション頻度や滞在時間の重みを効率的にアテンションへ反映できるようになりました。ユーザーの「行動の密度」を直接モデルが扱えるようになり、予測精度と学習の安定性を両立し、さらに標準的なモデルに対し驚異的な高速化を実現しました。
※3 ユーザーによる映画の5段階評価データセットのこと。
ソースコードはこちらに公開されています。
こちらは1からスクラッチでモデルを学習させる必要があり、24GB以上のGPUが必要です。
こちらは、2023年にMicrosoftが開発したモデルになります。(論文はこちら)
LLMを推薦エンジンそのものではなく、既存の推薦エンジンや検索ツールを自在に操る「脳」として活用するエージェント指向のフレームワークで、前章の「タスクレベルでの進化」に該当します。ActionPieceやHSTUのように新しくモデルを学習させているわけではなく、既存のLLM(GPT-4など)をレコメンドタスクに応用したフレームワークです。既存のLLMの対話・論理力を活かしつつ、レコメンドの正確性は専用ツールに任せて役割分担をすることにより、次世代の対話型推薦を実現します。専用ツールはSQLの作成(発売日や価格などを調べる機能)、アイテムの検索(調べた結果を条件にしてアイテムを絞り込む機能)、ランキングの計算(絞り込まれたアイテムをユーザーの好みに合わせて順位をつける機能)に分かれています。
技術的特筆点は、「Shared Candidate Bus」というメモリ機構です。アイテムの膨大なリストをテキストとしてLLMに流し込むのではなく、ツール間で共有される「バス」に候補を保持させることで、トークン制限を回避し、対話を止めずに数千件規模の候補を絞り込めるようになりました。
ソースコードはこちらに公開されています。
こちらはGPT4(またはGPT4o-mini)をAPIで呼び出して使用することができるので、動かす環境はCPUのみでも可能です。実際にこちらをローカルのPCで動かしてみました(日本語で出力するように元コードのシステムプロンプトを修正しております)。
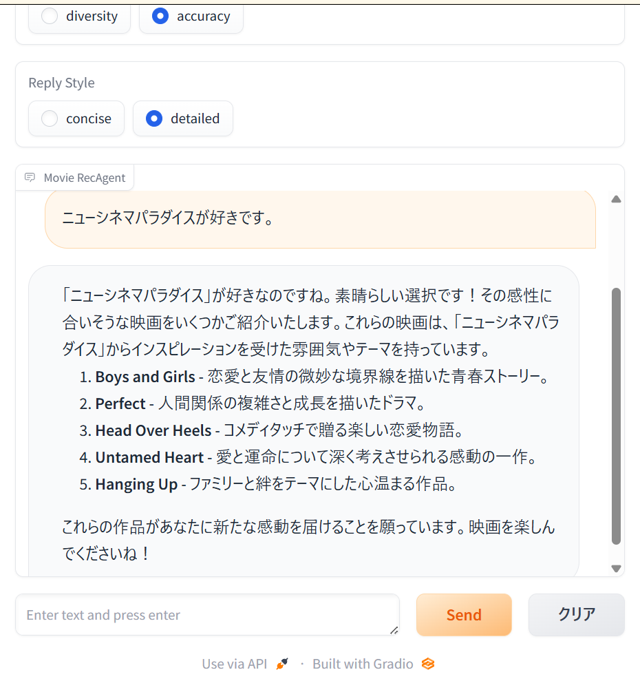
これらは入力しているデータがMovieLensですので、その中からレコメンドするようにしてくれています。このように、実際にあるアイテムリストを参照しながら対話型レコメンドを行えることもこのシステムの特徴です。
「生成的推薦」へのパラダイムシフトにより、推薦システムは単なるスコアリングとリスト提示の道具から、アイテムの持つ意味やユーザーの文脈を深く解釈できる推薦エンジンへと進化しました。これにより、ActionPieceが提唱する「属性の集合」としてのアイテム理解や、HSTUが実証した「スケーリング則」による高精度な予測、そしてInteRecAgentのような会話型のレコメンドシステムが実現しました。これらにより、膨大な新商品が投入されるプラットフォームでのコールドスタート問題の解決や、ユーザーの曖昧な言語的要求に応えるなど、より広範なシーンでの社会実装が期待されます。
一方で、実運用に向けては生成AI特有のコストや計算リソースが課題となります。今回紹介したHSTUのような大規模モデルのスクラッチ学習には膨大なGPUパワーが必要ですし、InteRecAgentのようなエージェント型ではAPIの推論コストやレスポンスの遅延(レイテンシ)を考慮しなければなりません。精度の向上と運用コストのトレードオフをどう見極めるかが、次世代レコメンドをビジネスに組み込む際の鍵となるでしょう。
あなたにオススメの記事

2023.12.01
生成AI(ジェネレーティブAI)とは?ChatGPTとの違いや仕組み・種類・活用事例

2023.09.21
DX(デジタルトランスフォーメーション)とは?今さら聞けない意味・定義を分かりやすく解説【2024年最新】

2023.11.24
【現役社員が解説】データサイエンティストとは?仕事内容やAI・DX時代に必要なスキル

2023.09.08
DX事例26選:6つの業界別に紹介~有名企業はどんなDXをやっている?~【2024年最新版】

2023.08.23
LLM(大規模言語モデル)とは?生成AIとの違いや活用事例・課題

2024.03.22
生成AIの評価指標・ベンチマークとそれらに関連する問題点や限界を解説
















