



メルマガ登録
-
テーマから探す
-
技術から探す
-
業界・事例から探す
-
関連トレンドから探す
テーマから探す
技術から探す
業界・事例から探す
関連トレンドから探す

近年のデジタルトランスフォーメーション(DX)において、企業が直面する課題は単一のデータ形式では解決困難なものが増えています。しかし、従来のAI技術では異なる情報を個別に処理するため、人間のような直感的な判断や包括的な分析は困難です。
そこで登場したのが、マルチモーダルAIです。この革新的な技術は、複数のデータ形式を同時に理解・分析することで、さまざまな業界で実用的な成果を上げています。
本記事では、マルチモーダルAIの基本概念から代表的なモデル、業界別の活用方法、そして実際の企業導入事例まで、実践的な情報を幅広く解説いたします。導入を検討している企業の方は、ぜひ参考にしてください。
近年注目を集めている「マルチモーダルAI」は、テキスト・画像・音声といった多様な情報を統合して理解・生成できる新しい人工知能です。単一のデータ分析では得られない洞察や判断が可能となり、幅広い分野での応用が進んでいます。
まずはその基本的な概念から整理していきましょう。
マルチモーダルAIは、テキスト・画像・音声など複数の種類のデータを同時に処理し、統合的に学習・分析する能力を持つ人工知能です。異なるモダリティ(データの種類)※1の特徴を抽出し、共通の潜在的特徴空間で関連付けを行います。
マルチモーダルAIの主要な特徴は次の通りです。
※1 本記事では“モダリティ”を画像・音声・テキストに加え、時系列センサーや行動ログなどの構造化/半構造化データも含む広義の概念として扱います。
シングルモーダルAI※2は、テキスト・画像・音声など単一の種類のデータのみを処理し、特定のタスクに高い精度で対応するAI技術です。一方、マルチモーダルAIは複数のデータ形式を統合し、相関関係を理解することで、より複雑で多角的な分析や判断を可能にします。
両者では、次のような決定的な違いがあります。
マルチモーダルAIは人間に近い総合的な情報処理を実現する点で革新的な技術です。
※2 本記事では“シングルモーダル”を入力が単一のモダリティであるモデルとし、出力のモダリティは問わないとします。
マルチモーダルAIの研究は1980年代半ばに始まり、当初は音声や映像など単一モダリティの組み合わせによる補助的な処理が中心でした。技術の発展とともに、より複雑で高度な情報統合処理が可能になり、AI技術も段階的に進化を遂げてきました。
日本でも産学連携によるマルチモーダルAI研究が活発化し、実用化段階に入りつつあります。
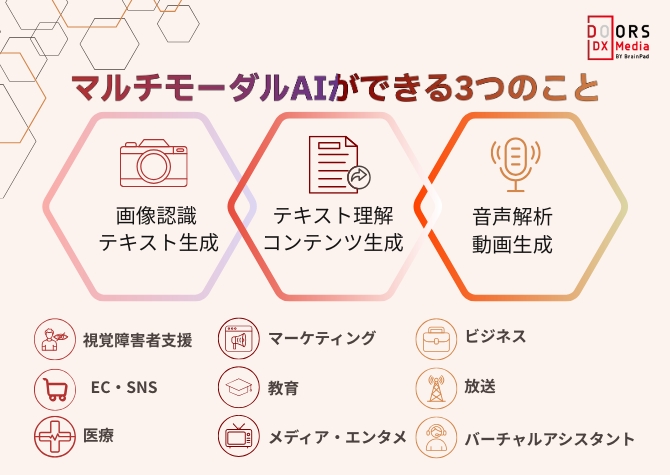
マルチモーダルAIの真価は、複数のデータを組み合わせて新しい価値を生み出せる点にあります。画像とテキストを組み合わせた説明生成や、テキストから動画を作り出すなど、人間の感覚に近い処理が可能です。
ここでは、マルチモーダルAIの代表的な3つの機能を、事例とともに紹介します。
【関連記事】
【連載①】生成AIのマルチモーダルモデルでできること -タスク紹介編-
マルチモーダルAIの画像認識とテキスト生成機能は、写真や画像の内容を分析し、人間が見て理解するような自然な文章で説明する技術です。人が写真を見て説明するかのように、AIが画像を「読み取って」言葉にすることができます。
具体的な活用事例は次の通りです。
このように、画像認識とテキスト生成を組み合わせることで、視覚情報を言語化する新たな価値創出が実現されています。
テキストから音声・画像・動画を生成するマルチモーダルAIは、文字情報を理解して視覚的・聴覚的なコンテンツを自動作成する技術です。人間が文章を読んで頭の中で映像を思い浮かべるように、AIがテキストの内容をもとに具体的な画像や動画を生み出します。
代表的な活用例は次の通りです。
テキスト理解と多様なコンテンツ生成の融合により、クリエイティブ活動の可能性が大きく広がっています。
音声から動画を生成するマルチモーダルAI技術は、話し言葉の内容や感情、話者の特徴を分析し、それに対応する映像コンテンツを自動作成します。人が相手の声を聞いて表情や仕草を想像するように、AIが音声情報から視覚的な表現を生み出します。
具体的な活用例は次の通りです。
音声解析と動画生成の連携により、聴覚情報を視覚的に表現する新しいコミュニケーション手段が実現されつつあります。
マルチモーダルAIを導入することで、企業は従来のAIでは難しかった複雑な業務や高度な分析に取り組めるようになります。人間に近い直感的な判断や、精緻な分析に基づく意思決定をサポートする点が大きな強みです。
ここでは、その具体的なメリットの数々を見ていきましょう。
マルチモーダルAIは、視覚・聴覚・言語など複数の感覚情報を同時に処理し、人間の脳のように統合的に理解することで人間に近い判断を実現します。人間が「目で見て」「耳で聞いて」「文脈を読み取りながら状況を判断」するかのように、AIも多角的な情報を組み合わせて理解を深めます。
人間に近い判断能力がもたらすメリットは、次のように多岐にわたります。
人間に近い情報処理を行うことで、より実用的で信頼性の高い判断パートナーとして機能します。
マルチモーダルAIは異なる種類のデータを同時に解析することで、従来の単一データ処理では解決困難だった複雑な業務課題に対応できるようになりました。複数の情報源を組み合わせることで、課題の本質を多面的に捉えることが可能です。
ビジネスシーンでの活用メリットは次の通りです。
複雑な業務課題への対応により、業務効率向上と迅速で的確な意思決定が同時に実現されます。
マルチモーダルAIは複数の異なる形式のデータを統合的に処理するため、単一データでは見落としがちな情報を補完し合い、包括的で高精度な分析を実現します。各データが持つ独自の情報を組み合わせることで、より深い洞察を得ることが可能です。
高精度な分析がもたらす主なメリットには、次のようなものがあります。
高精度な分析により、業務効率向上・リスク軽減・顧客満足度向上など、多様なビジネス価値を創出できます。
マルチモーダルAIは革新的な技術である一方、克服すべき課題も存在します。特に、大量のデータ準備や評価方法の難しさは、多くの企業が導入を検討する際の大きなハードルとなっています。
ここでは、マルチモーダルAIの実用化に向けた、主要な課題について詳しく解説します。
マルチモーダルAIが膨大かつ高品質な学習データを必要とする理由は、複数のデータ形式を統合して学習する技術的特性にあります。画像・テキスト・音声・動画などの各データ形式の特徴と相互関係を理解するには、従来のAIとは比較にならないほど、多様な学習材料が大量に必要となります。
学習データ準備における具体的な課題は、次の通りです。
学習データの準備負荷の高さが、多くの企業にとってマルチモーダルAI導入の大きなハードルとなっています。
マルチモーダルAIの評価が困難な理由は、複数の異なるデータ形式を統合処理する複雑性にあります。各データの貢献度を明確に分離することは、技術的に非常に困難な状況です。
評価指標が理解しにくい具体的な要因は、次の通りです。
特に、法的判断や医療診断などの説明責任が重要な分野では、モデルの透明性を高めるAI技術や横断的な評価指標の開発が急務となっています。

2025年現在、マルチモーダルAIを牽引する代表的なモデルが次々と登場しています。各モデルはそれぞれ得意分野や強みが異なり、活用できるシーンも多岐にわたります。
ここでは、特に注目すべき3つのモデルを取り上げます。
OpenAIは、テキスト主体のGPT-3.5やGPT-4から、画像入力対応のGPT-4V、リアルタイム音声・映像処理が可能なGPT-4o(Omni)へと発展してきました。
直近では、GPT-5が発表され、より高度な推論能力と長大なコンテキスト処理能力※3を兼ね備えています。GPT-5は研究開発・意思決定支援・エージェント的自律動作など、実務レベルでの幅広い応用を見据えた進化型モデルとして位置付けられています。
特徴的な進化ポイントは次の通りです。
このようにOpenAIは、GPT-4シリーズからGPT-5へと進化する中で、単なる自然言語処理の枠を超え、人間に近い直感的な理解と複雑な意思決定支援を担えるマルチモーダルAIを実現しています。
※3 長文や複雑なデータを一度に扱える能力。
※4 答えを一つに決める前に、複数の可能性を検討する能力。
GoogleはPaLM 2を経て、Gemini 1.x/1.5でマルチモーダル統合と長文処理を強化し、2025年時点ではGemini 2.5 Proを中心とした最新系へ発展しています。Geminiはテキスト・画像・音声を中心に、動画やコードも含めたマルチモーダル処理※5を視野に設計されており、業務活用を意識した多機能なAIへと進化してきました。
特徴的な進化ポイントは次の通りです。
このようにGoogleのマルチモーダルAIは、研究開発向けのモデルから実務に直結するAIプラットフォームへと進化し、ビジネス効率化と高度な情報処理の両立を実現しています。
※5公式対応範囲はモデルにより異なる。また、動画・コードの対応は研究段階や一部機能に限られる。
Anthropicは「安全性と信頼性」を最重要テーマに掲げ、Claude 3系からClaude 4系へとモデルを発展させてきました。最新のClaude Sonnet 4.5やClaude Opus 4では、画像入力など一部のマルチモーダル機能を拡張しつつ、高度な推論力と説明可能性の向上を意識した設計が進められています。
特徴的な進化ポイントは次の通りです。
Anthropicはこのように、安全性を軸に据えた進化を続けることで、企業にとって信頼できる実用的なAIパートナーとしての地位を確立しつつあります。
※6 最大100万トークンは Sonnet 4 の仕様例
※7 前系列から継続する名称例
マルチモーダルAIは、単なる技術導入にとどまらず、各業界が抱える課題解決の鍵として注目されています。近年では、製造・自動車・医療・教育・セキュリティなど、幅広い分野でデータを横断的に活用する事例が急速に増えています。
ここからは、各業界でどのように成果を上げているのか、その具体的な活用方法を見ていきましょう。
製造業では、マルチモーダルAIが画像データとセンサー情報を組み合わせ、従来の目視検査を大幅に進歩させています。振動・温度・音などの多角的な情報をリアルタイムで解析し、品質検査と異常検知を高精度で実行できます。
製造業における具体的な活用事例は次の通りです。
マルチモーダルAIにより、製造業の品質管理と生産効率が同時に最適化されています。
【関連記事】
世界の製造業の進化を実感:Hannover Messe 2025参加レポート
自動車産業では、マルチモーダルAIが自動運転技術の中核として機能し、カメラ映像・各種センサー・音声情報を統合的に解析してリアルタイムでの状況判断を可能にしています。人間ドライバーが視覚・聴覚・触覚をフル活用して運転するように、AIも多様な情報源から包括的な環境理解を実現します。
自動車産業における主要な活用例は次の通りです。
マルチモーダルAIにより、自動車の安全性と利便性が飛躍的に向上しています。
医療分野では、マルチモーダルAIが画像診断データと患者の病歴・電子カルテ・バイタルデータを統合解析し、診断精度を大幅に向上させています。多角的な医療情報を組み合わせることで、単独では見逃しがちな微細な異常も的確に検出します。
医療分野における具体的な活用例は、次の通りです。
マルチモーダルAIにより、医療の質向上と医療従事者の負担軽減が同時に達成されています。
【関連記事】
医療分野のAI活用―社会実装に向けてのディスカッションで見えてきたこと
教育分野では、マルチモーダルAIがテキスト・画像・音声・動画を組み合わせ、個別化された教材生成と学習支援を実現しています。学習者の理解度や反応をリアルタイムで分析し、最適なフィードバックを提供します。
教育分野における主要な活用例は次の通りです。
マルチモーダルAIにより、教育の個別最適化と効率化が実現されています。
セキュリティ業界では、マルチモーダルAIが監視カメラの映像データと音声センサー情報を統合し、従来の監視システムでは困難だった高精度な異常検知を実現しています。複数の感覚情報を組み合わせることで、より確実な状況把握が可能となります。
セキュリティ分野における具体的な活用例は、次の通りです。
マルチモーダルAIにより、物理的・デジタル両面でのセキュリティ強化が実現されています。
実際に企業がどのようにマルチモーダルAIを導入し、成果を上げているのかは気になるところです。ECサイトの検索精度向上から医療現場での診断支援、防犯システムまで、適用範囲は多岐にわたります。
ここではブレインパッドの事例を中心に、具体的な活用事例を紹介します。
ブレインパッドが開発したRtoaster GenAIは、GoogleのマルチモーダルAI「Geminiファミリー」を活用した商品検索最適化サービスです。従来のキーワード検索では対応困難だった曖昧なニーズへの対応が課題となっていましたが、画像・テキスト・行動ログ・ユーザー入力を総合解析することで、次のような抜本的な課題解決を実現しました。
初期導入はタグ設置で早期に価値検証を開始できます。一方、精度向上や業務適合の最大化にはデータ連携や評価設計、運用プロセス整備が必要です。
【関連記事】
「検索」から「対話」へ 老舗『Rtoaster』が描く、生成AI時代の“出会うUX”|DOORS DX Media BY BrainPad
昭和大学歯科矯正学講座とブレインパッドの共同研究では、口腔内画像から不正咬合(かみ合わせ異常)を分類・検索するマルチモーダルAIシステムを開発しました。従来は歯科医師の経験と主観に依存していた診断プロセスに客観性と定量性を持たせることが課題でしたが、AI技術により大幅な改善を実現しています。
複雑な症例への対応は今後の課題として残っているものの、さらなる精度向上と社会実装に向けた取り組みを進めています。
【関連記事】
マルチモーダルAI×歯科医療〜産学連携の取り組み成果をViEW2024で発表|DOORS DX Media BY BrainPad
NTTデータは防犯・セキュリティ分野において、映像データと音声データを組み合わせたマルチモーダルAIシステムを開発しました。従来の映像解析だけでは検出困難だった複合的な迷惑行為や異常事態への対応が課題でしたが、多角的なデータ統合により高精度な検知システムを構築しています。
多様な現場への導入拡大により、地域の安全強化と運用コスト削減の両立に貢献する重要なソリューションとなっています。
※参考:マルチモーダルAIとは?複数データを統合する次世代AIの仕組みと活用事例|クラソル
マルチモーダルAIは、今やビジネスの競争優位性を左右する重要な技術となりました。複数のデータ形式を統合的に処理する能力により、人間の感覚統合に近い情報処理を可能にし、従来のAIでは対応困難だった複雑な業務課題の解決を支援します。
しかし、データ準備の負担や評価指標の不透明さなど課題も残されており、導入にはしっかりとした準備と戦略が必要です。AI技術の進歩は日進月歩であり、早期導入によりノウハウと実績を蓄積すれば、将来的に大きな競争力となります。
マルチモーダルAIは、今後各業界で高度な活用が進み、新たなビジネス価値創造の原動力となるでしょう。マルチモーダルAI導入を検討している方は、DX分野で豊富な実績を持つブレインパッドまでお気軽にご相談ください。
あなたにオススメの記事

2023.12.01
生成AI(ジェネレーティブAI)とは?ChatGPTとの違いや仕組み・種類・活用事例

2023.09.21
DX(デジタルトランスフォーメーション)とは?今さら聞けない意味・定義を分かりやすく解説【2024年最新】

2023.11.24
【現役社員が解説】データサイエンティストとは?仕事内容やAI・DX時代に必要なスキル

2023.09.08
DX事例26選:6つの業界別に紹介~有名企業はどんなDXをやっている?~【2024年最新版】

2023.08.23
LLM(大規模言語モデル)とは?生成AIとの違いや活用事例・課題

2024.03.22
生成AIの評価指標・ベンチマークとそれらに関連する問題点や限界を解説
















