



メルマガ登録
-
テーマから探す
-
技術から探す
-
業界・事例から探す
-
関連トレンドから探す
テーマから探す
技術から探す
業界・事例から探す
関連トレンドから探す

Difyのようなノーコード/ローコードでLLMアプリケーション(LLMアプリ)を構築できるツールが急速に普及し、専門家でなくてもLLMアプリを驚くほど手軽に構築できるようになりました。
「うちも生成AIを導入するぞ!」と意気込んで、社内規定やマニュアルを読み込ませたLLMアプリを作ってみた、という方も多いのではないでしょうか。
しかし、いざ使ってみると「あれ、なんだかイマイチだな…」と感じていませんか?質問しても知りたいことに答えてくれなかったり、正しいようで、正しくない回答が出てきたり…
Webで改善策を検索してみても、専門用語が並んだ難解な記事ばかりで、どこから手をつければ良いのかわからない…。そんなお悩みを抱えている方も少なくないはずです。
このような悩みはLLMアプリ構築における「あるある」といえるでしょう。本連載では、「あるある」の原因を紐解き、LLMアプリ改良の糸口を探っていきます。まずは本記事で、自社データを生かすためのRAG(検索拡張生成)のチューニングポイントについてざっくりと概要をご紹介します。

2022年11月のChatGPTの登場をきっかけに、生成AIの時代、「第4次AIブームの到来」が訪れたと言われています。ChatGPTはわずか2か月後の2023年1月に世界の利用者が1億人を超えた※1という驚異的なスピードで利用者を獲得し、LLM(大規模言語モデル)が一気に普及しました。一方で、もっともらしい内容だが、正しくない回答や意味不明な回答をする、いわゆるハルシネーションの存在や、計算問題が苦手であること、モデルが学習された時期以降の最新ニュースなどの情報を持っていないことなどの課題が存在していました。翌年2024年に公開されたモデルは、科学・コーディング・数学など理数系の問題を得意としており、その後もLLMの思考・推論能力は向上の一途を辿っているといえます。
※1 出典:Has the AI rally gone too far?
最新のニュースに回答できないという課題についても、ユーザーから質問を受けたLLMアプリが自己の判断によりWeb検索を行い情報収集をするようになりました。さらには、2025年初頭に、Deep Researchと呼ばれる機能がChatGPTやGeminiにおいてリリースされました。これは自律的に判断し行動するAIエージェントの一種であり、ユーザーの質問に対して複数のソースを対象に情報収集を行いレポートを作成します。検索に限らず、様々なタスクにおいてこのようなAIエージェントがその作業を代替していくと予想されています。
ただし、多くのアプローチによって回答の正確性向上が試みられているものの、ハルシネーションを完全に克服することは難しいのが現状です。今後もハルシネーションのリスクと付き合いつつ、実用に足りうるLLMアプリケーションの構築を進めていかねばなりません。
企業においても、FAQや従来型チャットボットの代替、社内情報検索などのLLMアプリや、業務効率化のためのAIエージェントの導入が始まっています。
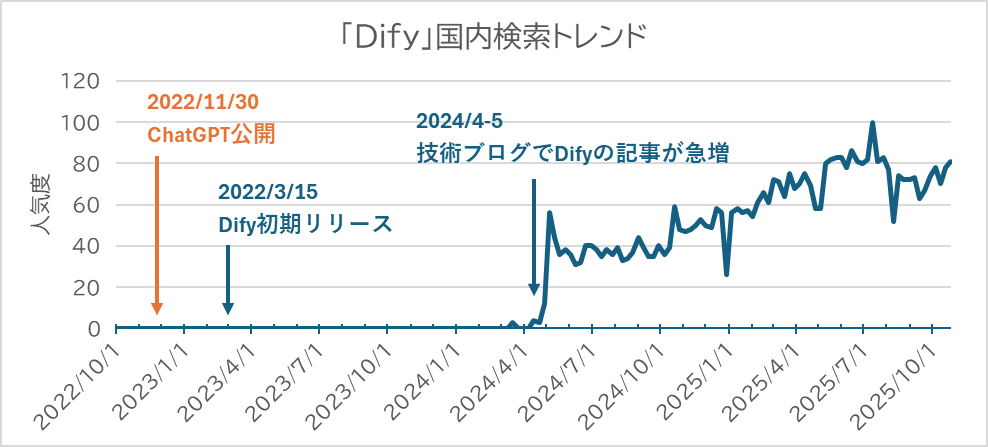
Difyなどのノーコード/ローコード開発ツールの登場により、LLMアプリの開発のハードルが下がり、専門的な知識を持たないビジネスユーザーでもアプリ開発が容易になりました。国内の人気動向をGoogleトレンドによって確認(図1)すると、2024年5月ころからDifyの人気が急上昇し、その後も右肩上がりに伸び続けていることがわかります。
企業におけるLLM活用の重要なポイントとして、社内情報などの非公開なデータをLLMに渡し、各社特有の知識をもとに回答を生成する機能が挙げられます。LLMが学習していない知識を外部から与えるための技術にRAG(検索拡張生成)と呼ばれる手法があります。2020年に当時のFacebook(現Meta)がRAGを提唱※2して以来、従来のファインチューニング等と比べ手軽に実装できることから、様々なユースケースで採用され、必要不可欠な機能となっています。先述のDifyにおいてもナレッジベースという機能でRAGが実装されています。
※2 出典:Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
ここからは、企業におけるLLMアプリ活用の壁に迫っていきます。
RAGを搭載したアプリを作ってみたものの、イマイチ有用な回答が得られず、活用が進まないという声も聞きます。皆さんも、次のような場面に直面したことはありませんか?
うまくいっていないことはわかるが、何が原因かわからない・どうしたらよいか見当がつかない……こうした壁に悩まされている方も多いのではないでしょうか。Difyのようなツールは、RAGの実装を非常に簡単にし、いわばブラックボックスとして提供してくれています。しかし、「イマイチ」を脱却するには、このブラックボックスの中から一歩踏み出し、内部で何が行われているかを理解することが不可欠です。
本記事では、RAGの仕組みについて簡単に解説した上で、壁として立ちはだかる「あるある」の原因がなぜ発生してしまうのか探っていきます。
基本的なRAGは、「データ整備」「情報検索」「回答生成」という3つの要素で構成されています。
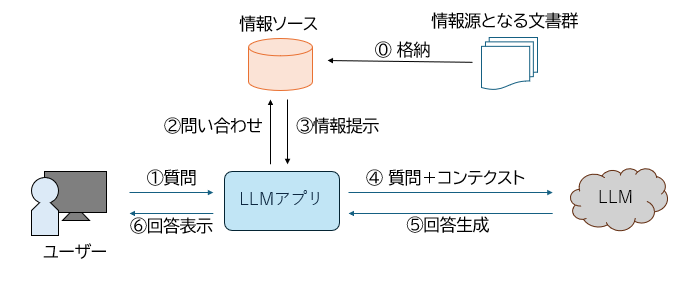
図2:RAGの概要
今回は、ノーコード/ローコードツールを利用するうえでの最低限の仕組みの解説に留めますが、そのようなツールを用いない場合の実装についてはこちらの記事でも解説していますので、ぜひご覧ください。
改めて、先ほどの「あるある」をもう一度確認してみましょう。
RAGの仕組みを踏まえると、これらの課題の原因が見えてきませんか?
例えば、「該当する情報はありません」と匙を投げられてしまうのは、質問に対して適切な情報を探してくる「情報検索」の段階に改善ポイントがあるのかもしれません。少し複雑なことを聞くと的外れになってしまうというのも、調べるべき内容が多岐にわたり、必要な情報を絞り切れていないのかもしれません。あるいは、さらに前段の「データ整備」の段階で用意したデータに課題があり、LLMがうまく質問に答えるための情報源として機能していないのかもしれません。
「データ整備」「情報検索」の両者に改善すべき点があるなど、しばしば複数の要素に原因が絡んでいることがあります。それぞれのポイントに対して適切な対応をとり、3つの要素が嚙み合わさるようにすることが重要となります。
RAGの構成要素と紐づけながら、改善・性能向上のためのチューニングポイントをご紹介します。「データ整備」の段階では、データそのものをどれだけ整えた形で用意することができるかがポイントとなります。「情報検索」では適切な検索ロジックの選択が、「回答生成」では望ましい出力を得るためのプロンプト構築がチューニングポイントとなってきます。それでは順に見ていきましょう。
情報検索に用いるロジックやLLMの回答生成能力がどんなに優れていても、データが汚ければ望ましい回答を得ることはできません。検索がうまくいくように、データを丁寧に整えておく必要があります。
データのチューニングポイントとしては、大きく分けて3つあります。
ノーコード/ローコードツール上でも設定がカスタマイズできるポイントと、ツールに投入する以前に処理しておくべきポイントがあります。チャンク処理やエンベディングの設定はほとんどのツールに実装されていますが、データの前処理については細かいところに手が届かないツールが多いようです。Difyにおいても、2025年9月にナレッジパイプライン機能が搭載されたようですが、まだ利用されていない方も多いのではないでしょうか。
データの前処理は見落としがちな重要ポイントです。特にカスタマイズせずにPDFファイルから抽出された文章にはノイズが入り込むことが多々あり、それが検索に影響を及ぼします。例として、弊社の決算報告に関するリサーチレポートのPDFをDifyのナレッジに登録した結果を見てみましょう。

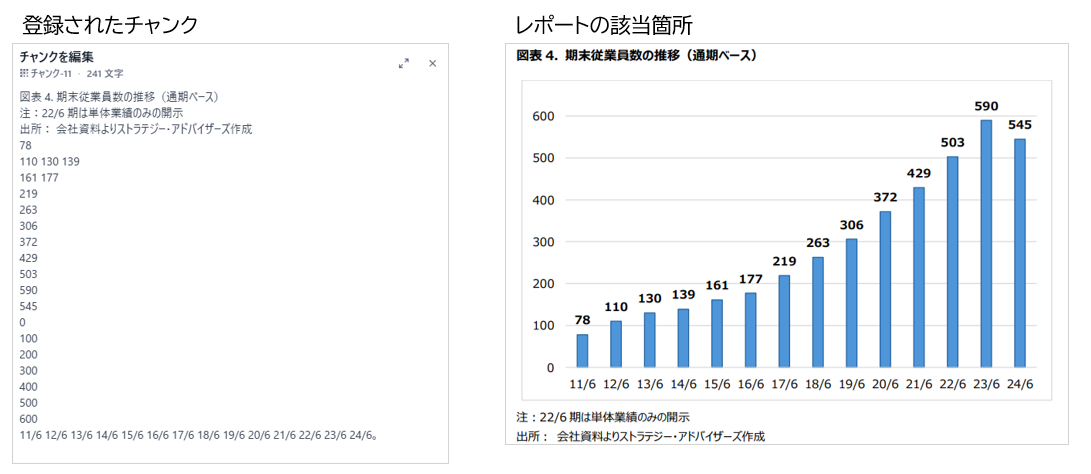
図3のように、本文は大まかに抽出できているものが大半ですが、改行が頻繁に行われており、文書がバラバラになっているのは少し気になりますね。図4で見られるようにグラフや表の数値が混じってきてしまうものもあります。図表の情報も重要ですが、元の構造とは全く異なるばらばらなかたちで抽出されており、これが検索結果として出てきたとしても何を意味するものなのか全く分からないデータになってしまっています。
実際にレポートをツールに登録して質問をしてみても、意図通りの回答は得られませんでした(弊社の事業としては「プロダクト事業」と「プロフェッショナルサービス事業」があります)。
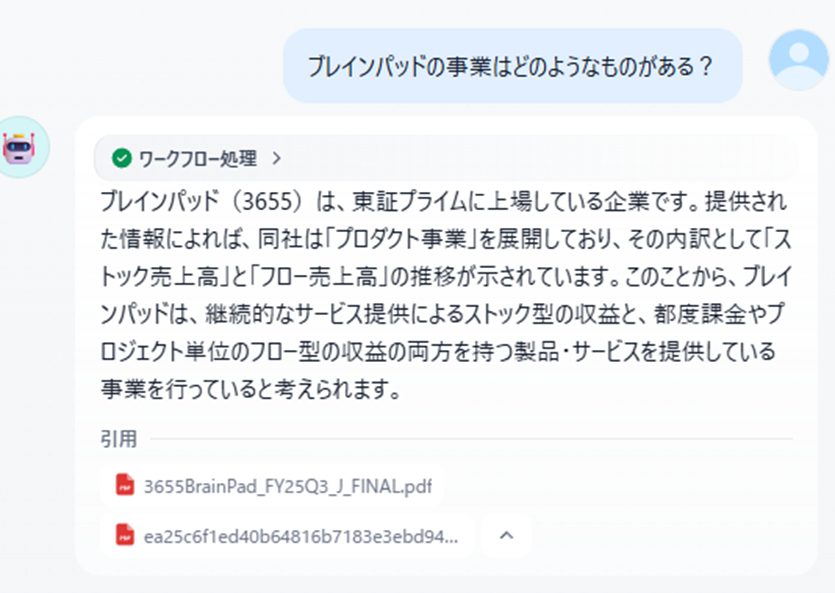
引用されているチャンクを見ると、図4のような断片的なチャンクがなぜかヒットしており、本来参照すべき文書が検索結果に現れていないことが原因のようです。理想としてはグラフや表の意味合いも検索できるとよいですが、まずはノイズになるような情報をバッサリと削除してみます。Difyであれば、検索でヒットしてほしくないものを一つひとつ無効にすることができます。その上で再度質問してみましょう。
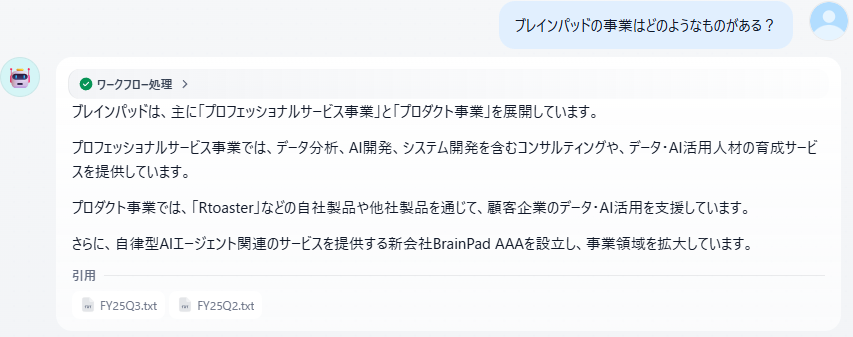
今度は意図通りの回答となりました。
このように、簡単にデータが登録できるからと言って、それが質問回答に必ずしも効果的に用いられるとは限らないことがよくわかります。膨大な資料に対して前処理を行うには入念な準備が必要となりますが、データ整備はRAGの根幹をなすチューニングポイントです。
今回のPDFでノイズとみなしたものは以下のとおりです。
このような、人がレポートを見るために整えられた体裁がナレッジとしては悪影響を及ぼしうることを念頭におく必要があります。
メタデータの登録も重要です。メタデータとは、その文書などのデータそのものに対する情報を差し、文書の作成日時や作成者などが代表例です。メタデータは、検索時のフィルタとして利用することができます。「最新の社内規定を出して」というときに古いバージョンが出てきてしまう場合、メタデータの設定によって回避することができるかもしれません。
その他にも、元の文書が配置されているファイルの階層構造や、文書のカテゴリなどをメタデータとして登録することで、部署や商材ごとに似たような文書が膨大にあるようなケースでも、もっともらしい誤りが生成されるリスクを下げることができるはずです。
とりあえずPDFを放り込むのではなく、データが持つ情報の質を上げるためのポイントに取り組んでいくことが重要です。
チャンク処理とエンベディングは関連性が高いため、まとめてご紹介します。埋め込みベクトルへの変換はエンベディングモデルと呼ばれる専用のモデルを利用して行われます(検索方法としてベクトル検索を選択する場合)。エンベディングモデルが一度に数値表現に変換できるテキストの長さには上限があるため、文書を一定の長さで区切る必要があるのです。
また、上限に収まる長さであっても、話題があれこれ散らばった内容を埋め込みベクトルに変換すると、モデルの性能によっては元の意味合いが正確に保持されず、検索時にうまくヒットしない可能性も高まります。エンベディングモデルの性能が高いほど、より長い文書の意味合いを残したまま埋め込みベクトルに変換できるとされています。一方で利用コストも高くなりがちであるため、情報源である文書の内容をよく理解し、設定のバランスを見極めることがチューニングポイントとなります。
多くのツールでは「ベクトル検索」「全文検索」の2つの検索ロジックに加え、ベクトル検索と全文検索の両方を行い、両者のバランスを取った検索結果を出力する「ハイブリッド検索」の3種類から選択することができます。
ベクトル検索は多くのケースで効果的であるとされるものの、万能ではありません。ベクトル検索と全文検索では得意とすることが異なるため、LLMアプリのユースケースを想定したうえで適切に使い分けることが推奨されています。それぞれの得意分野は、ざっくりと表1のように整理できます。
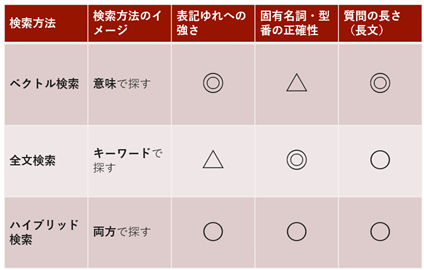
ベクトル検索は、埋め込みベクトルが元文章の意味合いを数値化した抽象的な情報を利用することから、表記ゆれが起こりやすいトピックの検索や、比較的長文の質問が想定される場合において効力を発揮します。一方の全文検索は、いわゆる「キーワード検索」で、質問のキーワードが含まれる文書を検索する仕組みです。固有名詞を正確に一致させる必要がある場合に採用する方法です。
具体的な商品名や製品型番などを含む質問を想定するLLMアプリでベクトル検索の設定を行っていると、「もっともらしいが検討違いの回答」が生成されやすくなってしまいます。そのような場合は全文検索を採用すべきでしょう。
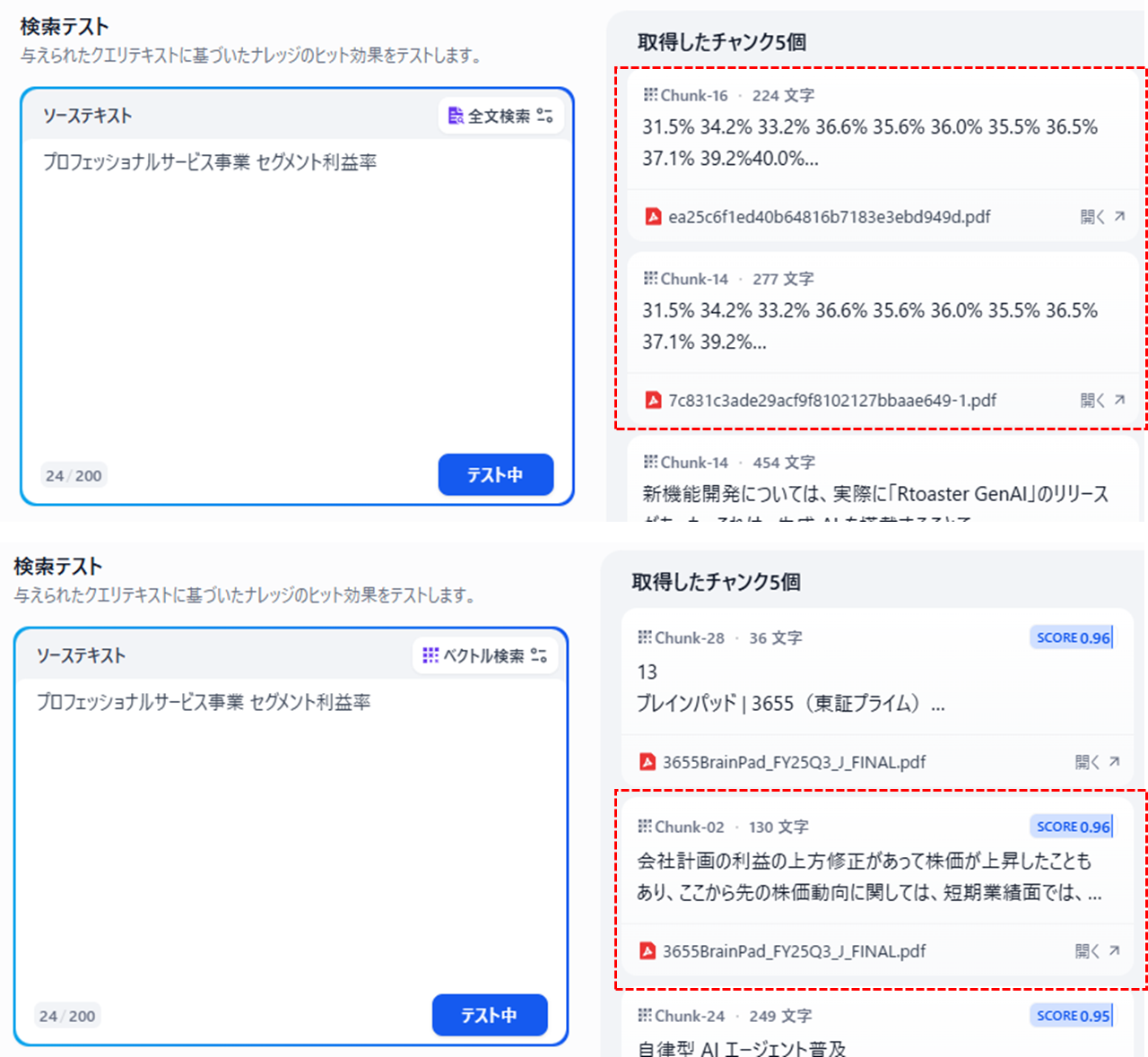
例えば弊社のプロフェッショナルサービス事業のセグメント利益率について質問を行うとします。全文検索では、(データのポイントで記載のとおり、今回はノイズになってしまいますが)セグメント利益率の推移を描いたグラフのチャンクが選ばれてきています。一方ベクトル検索で同様の質問をすると、会社全体の利益に関するチャンクがヒットしていることがわかります。このように異なる対象に対し似通った内容のチャンクがある場合、大まかな意図を捉えるベクトル検索よりもキーワードで狙い撃ちする方が良質な回答が期待できます。
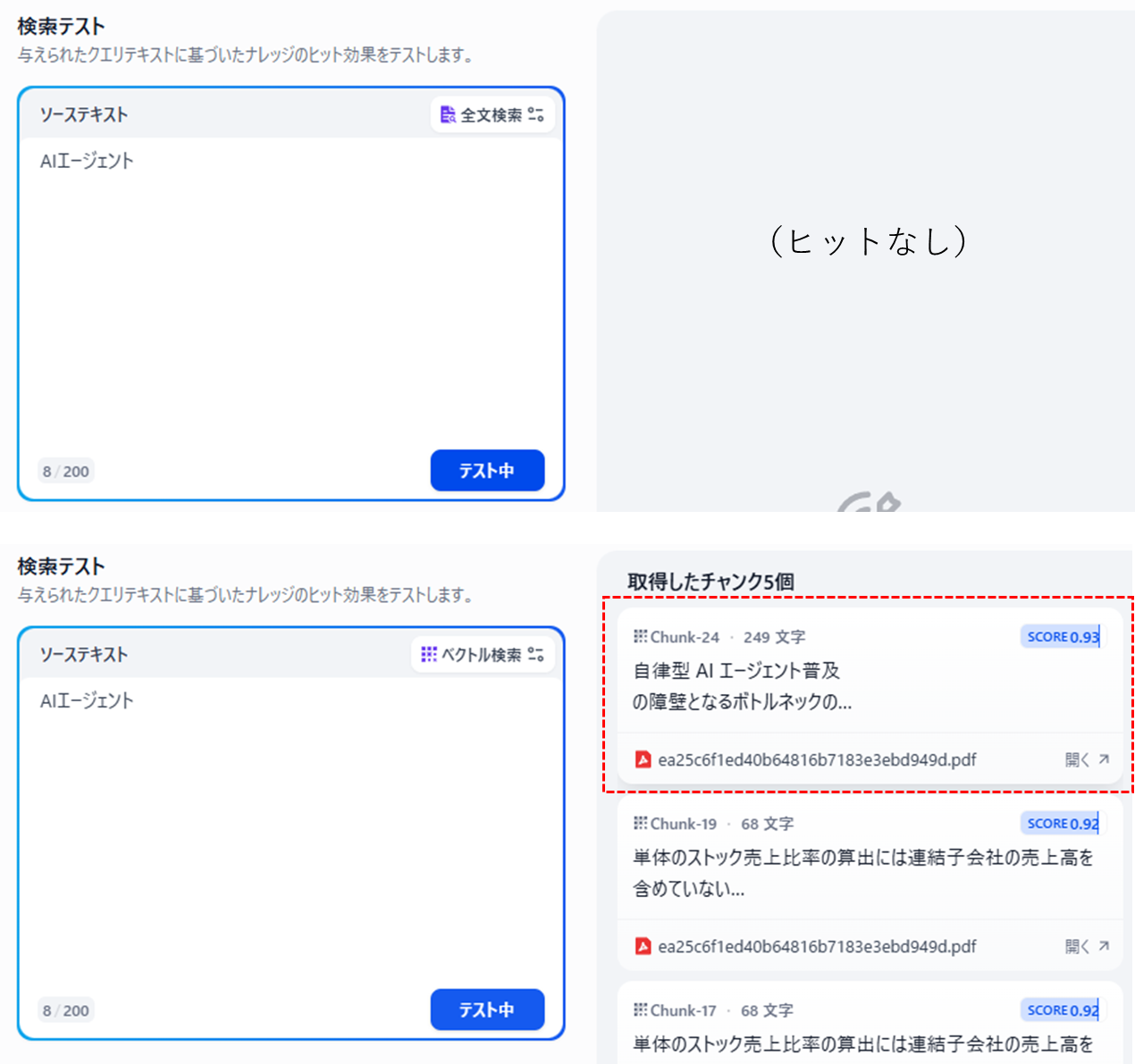
先ほどのレポートの中には「AI エージェント」というワードが登場しますが、間にスペースが入っており、全文検索で「AIエージェント」と調べてもヒットしません。このような容器揺れが起こりやすいワードに対しては、全文検索よりもベクトル検索が効果的です。
ハイブリッド検索はベクトル検索・全文検索の両者の短所を補うことができるとされますが、どちらの検索に重きを置くかをパラメータで指定する必要があるため、両者の特徴を押さえた上で重みづけの設定を行うことが望ましいといえます。
検索設定にはもうひとつ要素があります。それはRerankモデルの設定です。上記の検索方法は、膨大な情報の中から高速に質問に近しい情報を探してくるためのアルゴリズムであるため、正確性が一部犠牲になることがあります。そこで登場するのが、質問に対する情報の重要性を並べ替えるRerankモデルです。ベクトル検索などでおおざっぱに関連した情報をいくつか取得し、Rerankモデルで細やかに情報の取捨選択を行うことで、検索結果をより重要なもののみに絞ることが期待できます。ただし、Rerankモデルが効力を発揮するのは、検索の段階で重要な文書が選ばれてくることが前提となります。したがって、Rerankモデルは性能向上の一手段として捉え、適切な検索方法を選ぶことがより重要な立ち位置であると考えられます。
ちなみに、文書の検索ロジックはベクトル検索や全文検索だけではありません。これらの方法は、断片化された文章に対して検索を行うため、元の文書が持つ構造や関係性を加味した検索に弱点があります。弱点を克服するために、ベクトル検索に工夫を加えたアルゴリズムやデータ構造を別アプローチから実装した手法などがあります。現時点でDifyには搭載されていない機能ではありますが、これらの手法についても今後取り上げられればと思います。
RAGの回答生成ステップでは、検索の結果を参考にしながら、元の質問に対してLLMが回答を生成します。具体的には、質問と検索結果を一つのプロンプトにまとめてLLMに渡す処理が該当しますが、単純にこれらを並べるだけでは、ユーザーの意図から逸れた回答になる可能性があります。例えば、検索結果に質問に回答できる確かな情報が含まれていない場合でも、LLMが頑張って推論を行ってしまい、回答をでっちあげてしまうことがあるかもしれません。簡単な対策として、「以下の情報のみを使用して回答を生成してください」といった指示を加えたり、「根拠となる情報が無い場合は、”回答できない”と答えてください」などと無理な推論を避けるプロンプトを用意しておくことがチューニングの最初のステップとなります。
その他にも、一度仮の回答候補を複数生成させ、別のステップで候補の中から最も妥当性の高い回答を選別する方法や、妥当性が一定程度担保されるまで回答を繰り返し生成するようなアプローチの論文も存在していますが、ノーコード/ローコードツールで実現するのは難易度が高い方法かもしれません。
「データ」「検索ロジック」「プロンプト」のポイント以外にも、LLMアプリの性能を担保するために検討しておくポイントを簡単にご紹介します。
一例として、構築したLLMアプリの会話テストも論点になります。簡単な質問を行い、意図した回答が得られるか確かめることは皆さん行われていることかと思います。その反面、回答すべきでない質問や想定外の質問に対しての回答を想定し、実際にそうした状況でも期待通りの回答が生成されることをテストするところまではなかなか手が届いていないのではないでしょうか。例えば、想定したQ&Aの用途を越えて一般的な質問に答えさせたり、雑談を持ちかけたりといった抜け道をユーザーが見つけてしまわぬよう、プロンプトにルールを設けておくことと、それが正常に機能するかどうか確認しておくことを検討すべきです。
簡単な社内向けアプリであればそこまで作りこむ必要はないかもしれませんが、想定外利用によってLLMの費用が嵩んでしまい、アプリを使い続けられなくなる最悪のケースも想定しておけると良いでしょう。
それぞれのチューニングポイントを一通り紹介しましたが、重要なのは「唯一の正解」はないということです。どのような情報を、誰に、どのように使ってほしいのかというアプリケーションのユースケースによって適切な設計・チューニングが異なります。自社のデータ特性を分析し、最適な対策を見つけ出すのは容易ではありません。
今回は、LLMアプリに潜む「あるある」とその原因・チューニングポイントについて、RAGの仕組みから探りました。ツールを導入するだけで魔法のように課題が解決するわけではなく、その裏側にある仕組みを理解し、LLMアプリの目的に合わせてチューニングしていくプロセスが不可欠です。
次回以降、今回ご紹介した3つのチューニングポイントについて、具体的な改善策をさらに詳しく解説していきます。第二弾は「データ」の観点から、今回紹介しきれなかった具体的な文書の前処理やメタデータ設定を検証を交えつつご紹介する予定です。第三段以降も、検索ロジックやプロンプトの観点を深掘りしていきます。単純なベクトル検索と異なる検索手法「GraphRAG」など、現段階ではツールで実装されていない別アプローチの解説や検証も行っていければと思いますので、是非連載にご期待ください。
あなたにオススメの記事

2023.12.01
生成AI(ジェネレーティブAI)とは?ChatGPTとの違いや仕組み・種類・活用事例

2023.09.21
DX(デジタルトランスフォーメーション)とは?今さら聞けない意味・定義を分かりやすく解説【2024年最新】

2023.11.24
【現役社員が解説】データサイエンティストとは?仕事内容やAI・DX時代に必要なスキル

2023.09.08
DX事例26選:6つの業界別に紹介~有名企業はどんなDXをやっている?~【2024年最新版】

2023.08.23
LLM(大規模言語モデル)とは?生成AIとの違いや活用事例・課題

2024.03.22
生成AIの評価指標・ベンチマークとそれらに関連する問題点や限界を解説
















