



メルマガ登録
-
テーマから探す
-
技術から探す
-
業界・事例から探す
-
関連トレンドから探す
テーマから探す
技術から探す
業界・事例から探す
関連トレンドから探す

機械学習システムを業務システムと連携させるためには、アプリケーション基盤(フレームワーク)を構築しなければなりません。これを最も簡単な構成である「Web・DB・バッチ」(図)で説明します。
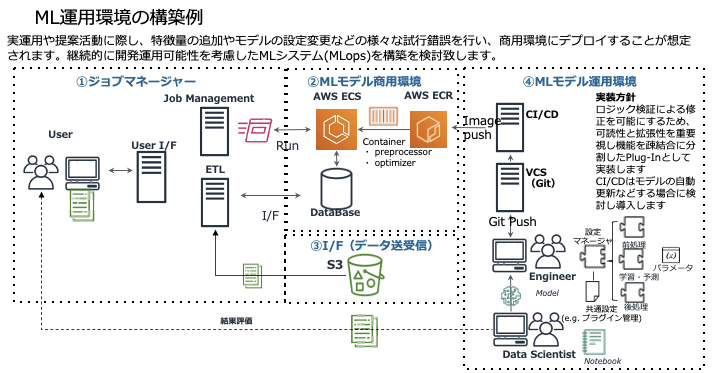
この図は在庫最適化システムの提案書に記載した構成図です。このお客様は機械学習システムの実用化経験が豊富で、現実的なご指摘をしてくださる会社でした。例えば、このお客様は世界中に倉庫を持っておられる上に、新しい倉庫を次々と作っておられます。「これから新しく作る倉庫の適性在庫をどうやって評価するのか?」と聞かれて、筆者は正直言葉につまりました。
しかしエンジニアとしては、何らかの回答を示さなければなりません。本番環境だけではなく、検証環境を用意して、分析の結果が良いかどうかを月次で評価し、レポートすることではどうかと提案しました。もう少し具体的に言うと、業務で実際に出た結果と突合してモデルの正しさ、つまりデータに対して正しく学習できているかを検証する環境を用意するということです。図の中の「④MLモデル運用環境」がこれに該当します。この提案にお客様も納得してくださいました。
システムの肝は、「②MLモデル商用環境」になります。これは、コンテナサービスであるAWS ECSとAWS ECRを利用して構築しました。コンテナは、マイクロサービスを提供するための非常に優れた技術であり、APIという形でデプロイを繰り返していくものとなります。
マネジメントシステムやバッチジョブもすべてAPIで提供されます。
まず、「①ジョブマネージャー」の部分は業務アプリケーションそのもの、あるいは既存の業務アプリケーションと連携する部分(ETL)です。この部分に関しては、要件定義が必要となります。
残る「③I/F(データ送受信)」も③に劣らず重要な部分です。この中でも特に機械学習に必要データを取得するためのデータレイクが最も重要です。機械学習システムの運用では様々なデータを蓄積し柔軟に管理する必要があるため、データレイクを今後の分析環境としてどのように構成するかについては、お客様と1年ぐらい議論することもあります。。
以上の①~④の環境を個別に作っていきます。この中でアジャイル型は②と④、ウォータフォール型が①と③になります。①と③はお客様の業務をしっかりヒアリングして作らなければなりません。
アジャイル型とウォータフォール型を組み合わせるとは、このようなことを指していますが、お客様はウォータフォール型の考え方に慣れているため、こうした作り方を説明するのもなかなか大変です。そこでシステム化の方針を決める前の、データの価値を確認する段階でお客様と一緒にPoCを実施しておくことにしています。IT基盤について説明する前に、データ活用をアジャイル型で進めることに慣れてもらうためです。またPoCを経験していただくことで、プログラムだけでなくデータに一定の価値があることを認識していただくこともできます。
PoCを経験していただいた上で前掲図を見せながら、「運用しなければいけない機能は、②と④です、業務で使う(すなわちしっかり要件定義する必要がある)部分は①です、データに関する部分、つまり③についても要件定義が必要ですよね、②はアジャイルで進めるのが常道です」といった説明をすると、今度はかなり理解していただけます。 しかしながら、日本企業でずっと基幹系システムを作ってきた方々にとっては、かなり違和感があるのも事実です。こうしたお客様をどう説得し、納得してもらうかは私たちにとってもまだまだチャレンジだったりします。
前述した「検証環境」についてもう少し詳しく説明します。冒頭で、「①手動分析、②仕組みの構築、③システム化&本格運用の最低3つのステップが必要」と述べました。この②の段階で、機械学習エンジニアは、例えば分散環境を構築して機械学習の前処理ができるようにしますが、アプリケーションとしての作り込みはしません。まだ再学習が必要な段階だからです。アルゴリズムやパラメータの変更がなくなった時点でAPI化(すなわちシステム化)します。検証は、この②の段階で行います。
半年間ぐらい、もっと長い場合は1年間様子を見て、季節の変わり目に想定外のデータがないかなど検証することになります。検証しながら、一方でお客様の基幹システムとどうやって接続するかという話を進めていきます。
さて、データサイエンティストが作成したシステムとして動かす際には、「リファクタリング」と呼ばれる作業が必要になります。検証段階におけるリファクタリングは、アジャイル性を高めることを意味しています。言ってみれば、デプロイが簡単かどうかです。初期段階は机上分析と並行に進むため、デプロイの自動化をしないで、Jupiter Notebookからコードをコピー&ペーストすれば動作するレベルが最適です。
この段階でお客様によっては、データがアップロードされたらシームレスにリアルタイムに実行したいと要望されることがあります。しかし、このそのような仕組みはしっかり作り込まないとピーク時にダウンするようなことが起こりがちです。何度も言うように、この段階では作り込みはしません。アップロードしたらcronでキックするぐらいの作りでちょうどいいのです。
私たちの会社に限らず、経験値の高いエンジニアは、検証段階であってもしっかりした設計をし過ぎる傾向があるように感じています。そのため私からは「作りすぎるな」と指示することもあります。良い意味でのいい加減さを許容しないといけません。ですが、あるタイミングからしっかりと作り込むことになります。そのタイミングを見失わなければよいわけです。 「③システム化&本格運用」におけるリファクタリングは、プログラムの柔軟性や保守性の向上というこの言葉が持つ本来の意味合いの作業となります。データサイエンティストがJupiter Notebookから上げてきたロジックを、機械学習エンジニアが本番運用および保守に耐えるようにリファクタリングを行ってからデプロイすることになります。これは開発ではなく本番運用になりますが、しかしこのようなリファクタリングを行う環境自体は、「②仕組みの構築」の段階で用意しておくわけです。
次にお客様のウォータフォール型システム(基幹業務システム)と連動するために、アジャイルシステム構築を並行して行うための注意点を説明します。
この際に、どこまでが業務システムでどこまでが分析システムかという線引きが非常に大切になります。その線引きがあってこそ、モデルの活用フェーズでAPIをデプロイする際にどのような検証・テストが必要か見えてきます。また、お客様の業務システムには、AIだけでなく多くのシステムが連携していることも忘れてはなりません。
線引きした中間にデータレイクをHubとして用意し、それ経由で結合していくという作り方が一般的です。データレイクの運用については、開発時および運用初期にはベンダーが代わりに行いますが、ある時期からはお客様自身で、つまり自走してデータ変更をすることになります。そのタイミングを見据えた設計をしておくことが、内製化を目指すお客様に満足いただくための非常に重要なポイントになります。 実際の現場では、お客様はデータ運用をExcelで実施しているケースもありますが、自動化等も考慮に入れてデータの構造化を図らなければなりません。その過程においてはIoTの活用なども視野に入れておく必要があります。分析のためにユーザが柔軟にデータを取り出せる環境を作りつつ、アクセス管理やデータの清流化なども厳密に行う必要があります。
最後に、機械学習を活用したアプリケーションを構築する上での典型的な失敗パターンをいくつか示します。
イテレートを繰り返す度にシステム品質が劣化していくという失敗例がよく見られます。アジャイル開発ほど全体のストーリーをしっかり決めないといけません。そのストーリーに沿って一般的に「フレームワーク」と呼ばれるアプリケーション基盤を作っておくとよいでしょう。
フレームワークがどのようなものかは、「3. 既存の業務システムと連携する機械学習システムの基本的なアーキテクチャーとプロジェクトの進め方」で詳しく説明しました。ここで付け加えますと、データサイエンティストには見えなくていいものを隠蔽しておいて、例えば関数名の命名ルールに従っておけば、モデルが正しくデプロイされるような枠組みを提供することもフレームワークの重要な役割です。つまりデータサインティストに実装の手間をかけさせず、しかもルールさえ守ってもらえば正しくデプロイされる(逆にルールを守らなければデプロイされない)仕組みがフレームワークです。
冒頭でも述べたように、データサイエンティストは分析のアルゴリズムを書くことが仕事です。システムのスケーラビリティ、パフォーマンス、セキュリティ、相互運用性といった品質属性の専門性は求められません。しかしシステムとしてはこれらも加味しておかないと、運用段階で破綻することになります。その破綻を防ぐためにも、フレームワークを用意することが必要なのです。
これは既に述べた「②仕組みの構築」の段階で作り込みすぎることで、修復が難しくなるという失敗のことです。これを防ぐためには、業務ユーザと業務ルールや文化、業務慣習などをしっかりヒアリングすることです。つまり業務要件定義をするタイミングを設けることが必要になってきます。 また実際に仕組みを構築するエンジニアには、作りすぎないことを指示しながら、「作ったものは次のフェーズで使うよ」と約束するなど、モチベーションを低下させない配慮も必要です。
プロトタイプは検証を目的としているため、コア機能と評価方法をしっかりと考えた上で作る必要があります。プロトタイプの検証段階でお客様と揉めることがありますが、そのほとんどが提案段階で何のためにそのプロトタイプを作るのかがしっかり合意されていないことが原因です。簡単なプロトタイプであっても、どのような仮説を検証するものなのか、検証の際の評価ポイントと評価方法を決めてから作る必要があるのです。
またプロトタイプの目的が周知されていないと、現場で動くものがお客様の目に留まることで、おかしな方向に話が進んでいくことが往々にしてあります。よくあるのは、プロトタイプやパイロット部門などの部分最適化を目標に作っているのに、それを知らない方から全体最適を目指すべきだといった横槍が日あることです。「部分最適化でいいのです。まずは一部門で効果が上がり、データに価値があることを証明し、その後徐々に全体最適を図っていくというロードマップなのです」といったことを、関係者全員に説明しておかなければなりません。 そのような「根回し」をきっちりとしておかないと、一部門での検証が終わり、これからステークホルダーを広げていこうというタイミングでの協力が得られません。PoCやプロトタイプ作成だけで終わってしまう案件が非常に多いのは、実はこうした配慮が欠けていたことが原因なのです。
アジャイル開発は、繰り返し開発し、評価を行いながら改善して作り上げていく開発方法ですが、これにも綿密な計画とゴール設定は必要です。そうしないと「いつになったら使えるものができるのですか」とお客様から聞かれてしまうことになります。
終わらないアジャイル開発は、何から何まで機械学習でやろうとしがちですが、一部ルールベースのAIでも構わないのです。運用開始に必要な最小限の機能は何かを合意し、その完成を1つのゴールとして設定することが大切です。
アジャイル開発は、繰り返し繰り返し作るので、お客様から見たら「言えばすぐに作ってくれてすぐ確認できる」となりがちです。そうこうしているうちに、前述の「データ分析と同時並行でシステム開発を行う際の失敗」でも述べた、業務要件定義をするタイミングを逃してしまうことになります。
どこかの段階で、いったん開発の手を止めて、「最終ゴールをもう一度決めませんか?」とお客様と段取りすることが肝心です。これは開発方法論というよりも、プロジェクトマネジメントの話であり、アジャイル開発でもプロジェクトマネジメントは重要だということです。 以上、私の実際の事例をベースに典型的な失敗例を列挙しました。失敗のパターンとしては一通り網羅できているかと思います。このようにならないように注意することでプロジェクトの成功確率は大幅に高まります。ぜひ参考にしてください。
【関連】機械学習プロジェクトを推進するにあたって大切なこと~DX推進時の「企画・PoC 」フェーズの落とし穴にはまらないために~
あなたにオススメの記事

2023.12.01
生成AI(ジェネレーティブAI)とは?ChatGPTとの違いや仕組み・種類・活用事例

2023.09.21
DX(デジタルトランスフォーメーション)とは?今さら聞けない意味・定義を分かりやすく解説【2024年最新】

2023.11.24
【現役社員が解説】データサイエンティストとは?仕事内容やAI・DX時代に必要なスキル

2023.09.08
DX事例26選:6つの業界別に紹介~有名企業はどんなDXをやっている?~【2024年最新版】

2023.08.23
LLM(大規模言語モデル)とは?生成AIとの違いや活用事例・課題

2024.03.22
生成AIの評価指標・ベンチマークとそれらに関連する問題点や限界を解説













