



メルマガ登録
-
テーマから探す
-
技術から探す
-
業界・事例から探す
-
関連トレンドから探す
テーマから探す
技術から探す
業界・事例から探す
関連トレンドから探す

2025年6月19日に開催されたASCII x Microsft主催 第4回 AI Challenge Dayに当社のデータサイエンティスト5名が参加しました。イベントの概要やブレインパッドの健闘の様子をご紹介します。





「AI Challenge Day」は、株式会社角川アスキー総合研究所と日本マイクロソフト株式会社が共同で企画・開催している生成AI開発コンテストです。特定業界の課題解決をテーマに開催されており、第4回となる今回は「小売(Retail)」に焦点が当てられました。
本イベントのテーマは「NextGen: Virtual Online Store Copilot」。ECサイトを訪れる顧客に対し、これまでにない新しい検索・購入体験を提供するAIアシスタントの開発を競います。単に質問に答えるだけでなく、RAG(検索拡張生成)やAIエージェントの技術を駆使して、多様なデータから顧客の意図を正確に読み取り、購入までをスムーズに導く能力が問われました。
開発期間は、2025年6月12日のテーマ説明会から、最終プレゼンテーションが行われる6月19日までの約1週間でした。
評価は、「スコア」と「審査員によるプレゼン評価」の2軸で総合的に行われました。

これらの評価を基に、総合評価として「グランプリ」「準グランプリ」が、スコアのみで「インテリジェントエージェント賞」が決まりました。
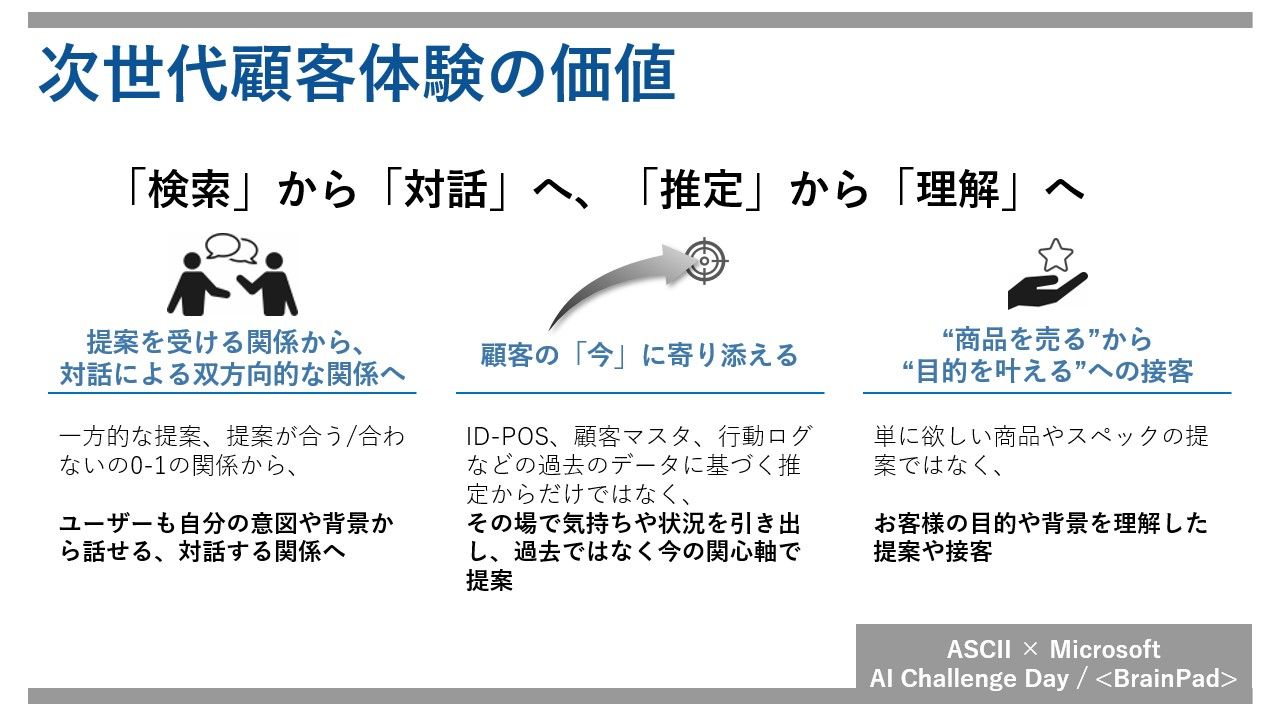
今回のハッカソンで私たちが目指したのは、単なるECサイトの機能改善ではありません。AIエージェントとの「対話」を軸に、ユーザーの購買体験そのものを根本から変革することです。
従来の検索体験が抱える課題を乗り越えるため、私たちは以下の3つの体験価値の変化を設計の核に据えました。
1.「要望を伝えて提案を受ける一方向コミュニケーション」から、「対話による双方向コミュニケーション」へ
従来のECサイトにおける商品検索は、ユーザーが明確な条件を設定する必要があります。ECサイトはその条件に合う商品を提示し、合わなければユーザーが再検索を繰り返します。
しかし、「大切な人へのちょっとした贈り物」や「新生活の準備をしたい」などの漠然としたニーズを持つユーザーは、その思いを適切な検索条件に変換する作業を一人で担っています。
新しい体験では、エージェントが言語化前の購買ニーズを拾い上げ、対話の中で目的の深掘りや予算の確認、イメージの具体化をサポートします。まるで実店舗で優秀な店員に相談するように、自然な会話で最適な商品に出会える――それが私たちの提案する「対話型検索」です。
2.単発提案から、顧客の「過去」を踏まえ「今」に寄り添う提案へ
「以前検討していたあの商品、まだ在庫あるかな?」「この前買ったPCに合うマウスが欲しいんだけど…」ECサイトを使うたびに、自分の状況を最初から説明するのは大きなストレスです。私たちが開発したエージェントは、ユーザーとの対話を「記憶」します。
さらに、過去の購入を踏まえた再レコメンドや、PC本体購入後には周辺機器を提案するなど、時系列の文脈を加味した提案も実施。
「言わなくてもわかってくれる」体験は、ユーザーに「自分専属のコンシェルジュ」がいるかのような感覚を与え、ECサイトへの信頼と愛着を育みます。
3.「商品を売る」から「目的を叶える」接客へ
ユーザーが商品を買うのは、「生活を豊かにしたい」、「誰かを喜ばせたい」といった目的達成の手段にすぎません。短期的な売上を追うのではなく、ユーザーの目的達成に寄り添うことこそが、長期的な顧客満足度(LTV)の向上に繋がります。
エージェントは購入目的を深掘りし、真にユーザーの目的を叶える提案を行います。条件に合う商品を並べるだけでなく、ユーザーの購入目的を深く理解し、その目的を叶えるための最適解を「一緒に探す」パートナーとして振る舞います。
前述のような新しい検索・購入体験を提供するAIアシスタントを目指して、今回は役割に応じて様々なツールを呼び出すマルチエージェントシステムを開発しました。
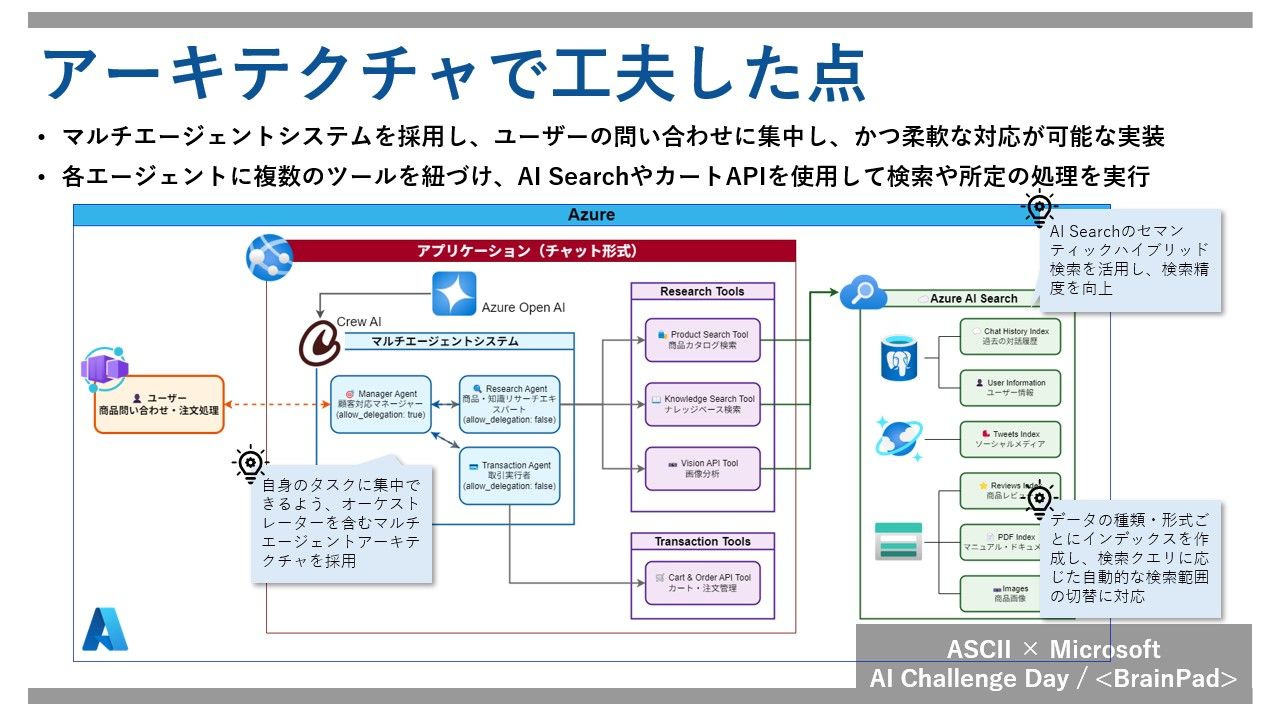
本システムは、タスクの抽象度が高い順に、以下の3つの役割が階層的に連携します。
タスクを細分化し、それぞれを最適なエージェント/ツールへ委譲することで回答品質を高めています。以下、各コンポーネントの詳細を説明します。
1.オーケストレーターエージェント(顧客対応マネージャー)
ユーザーからの入力(テキスト/画像)を受け取り、意図を理解したうえで適切なタスク特化型エージェントへタスクを振り分ける中核的存在です。各エージェントから返ってきた結果を統合し、必要に応じて自身で要約してユーザーへ返答します。単独で回答可能な内容は、他エージェントを呼び出さずに処理します。
2.タスク特化型エージェント
検索、注文処理、FAQ 応答など、特定業務に最適化されたエージェント群です。オーケストレーターの指示を受けて独立に処理し、結果を返却します。今回は、ECサイトの中核業務を担うふたりのエキスパートを用意しました。
3.機能特化ツール
エージェントは自らデータベースを直接操作したり、外部APIを呼び出したりはしません。その代わりに、標準化されたインターフェースである「ツール」を使用します。これにより、システムの疎結合性を保ち、メンテナンス性と拡張性を高めています。
これらのエージェントを動かすため、以下の技術を選定しました。
このアーキテクチャにより、抽象度の高いユーザーの意図理解から、具体的なAPI操作までを一気通貫でカバーし、高品質かつスケーラブルな対話型購買体験の基盤を構築しました。
6月19日の発表を終え、ブレインパッドの最終スコアは142点と悔しい結果となりました。 コンセプトとして描いた理想の顧客体験を形にするには技術的に多くの課題があったので、1週間の開発期間で得た学びを振り返ります。
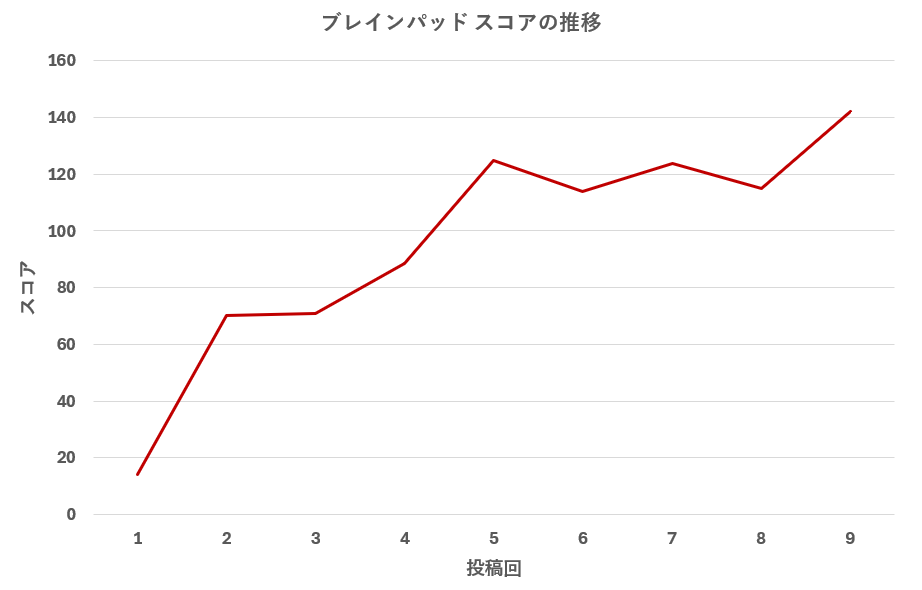
| 投稿No. | 評価スコア | 主な開発状況 |
|---|---|---|
| 1 | 14.0 | 初回テスト投稿
|
| 2 | 70.1 | Azure OpenAIのgpt-4oによる基本エージェント実装
|
| 3 | 70.8 | コードの微修正に伴うテスト投稿のため、スコアは推移 |
| 4 | 88.7 | 評価要件の会話コンテキスト実装
|
| 5 | 124.9 | 評価用ペルソナ拡張による自動的な点数向上
|
| 6 | 113.9 | マルチエージェントシステムの実装
|
| 7 | 123.9 | RAGシステム実装
|
| 8 | 118.5 | オーケストレーターエージェントのプロンプト変更
|
| 9 | 142.0 | 仮想顧客エージェント対応完成(最終スコア)
|
今回私たちは4つの点を意識して開発しました。
1.マルチエージェント実装
システム全体像で示した通り、今回はマルチエージェントシステムを実装しました。オーケストレーターエージェントを正確に機能させ、タスク分担を行うためにプロンプトの修正を繰り返しました。
2.ツール統合アーキテクチャ
Azure AI Searchと連携した動的な商品検索に加えて、ユーザーの質問意図をAIが解釈し、商品カタログ、製品マニュアル、サービスガイドなど複数のデータソースから最適な情報を自動選択するマルチモーダル検索システムを構築しました。テキスト検索と画像検索を組み合わせることで、ユーザーの多様な問い合わせパターンに対応できる柔軟性を実現しました。
3.「おもてなし」の心を持つ対話設計
単なる「エラー処理」ではなく、ユーザーに寄り添う対話設計を重視しました。商品が見つからない場合でも、関連性の高い代替商品を提案したり、検索条件の変更を促したりすることで、対話を継続させユーザーの目的達成をサポートする仕組みを実装しました。この「おもてなし」のアプローチにより、ユーザーとの自然で継続的な対話を維持することができました。
4.API連携による確実な状態管理
フレームワークの標準機能では難しい部分を補うため、カートAPIと直接連携する独自機能を開発しました。これにより、カートの中身や注文情報といった重要なデータを常に正確に把握し、評価に反映させることが可能になりました。
しかし、実装では多くの課題に直面しました。
多様すぎるデータソース
まず、直面したのは検索対象データの圧倒的な多様性です。今回与えられたデータは下記のように多岐に渡るものでした:
| 区分 | 種類 | 形式 |
|---|---|---|
| 構造化データ |
| テーブル |
| 半構造化データ |
| json |
| 非構造化データ |
|
|
これだけ特性の異なるデータを、単一の検索インデックスで柔軟に扱うのは困難と考え、データの種類(商品・マニュアル・レビュー…)や形式(テキスト・画像)に応じてインデックスを複数作成し、クエリに応じて最適なインデックスを参照させる戦略を取りました。しかし、そのパターンが膨大であり、データの特性に応じた個別のチューニングに十分に時間を割くことができませんでした。
エージェントへのデータ接続
インデックスを用意しても、AIエージェントは自動でそれを参照してくれません。「いつ、どのインデックスに、どのようなクエリを投げるべきか」というインデックス・ルーティングのロジックを精緻に定義する必要があります。
本来であれば、このロジックは「高価なプレゼントを探している顧客には、レビュー評価の高い商品インデックスを優先的に参照させる」といった販売戦略と密に連携させるべきです。しかし、実際にはエージェントが見かけ上は正常に動作していても、意図したデータソースを参照しなかったり、微妙に的外れな判断を下したりする予期しない動作パターンに苦労し、ビジネス観点を実装に反映させる前にタイムアップとなってしまいました。
曖昧な日本語に対する検索精度向上
データの特性に依存しない包括的な精度向上策として、私たちは、キーワード検索とベクトル検索を組み合わせたセマンティックハイブリッド検索を実装しました。キーワードの一致を捉える従来のテキスト検索と、文脈や意図を理解するベクトル検索を組み合わせ、さらに、検索結果をLLMで並び替えるセマンティックリランカーを導入し、ユーザーの検索意図をより深く汲み取る構成を目指しました。
この高度な仕組みは、具体的な商品名や機能に関する質問には有効でした。しかし、「ともだちが持ってなさそうなのがいい」や「おはようさん」といった、極めて曖昧で、検索意図そのものが希薄な入力に対しては、期待した効果を発揮できませんでした。最先端の検索技術であっても、ユーザーの心を完全に読み解くことの難しさを痛感した瞬間です。
マルチエージェント設計における複雑なフロー管理
問5では、RAG検索結果、カート操作、ユーザー情報管理などの複数のツールをまたぐ一連のタスクを、構造化されたデータに正確に連携し実行させる必要があり、堅牢なデータフローの設計に苦労しました。ここの設計が、システム全体の安定性を左右する重要な課題となりました。
フレームワーク制約下の設計の難しさ
エージェント開発にはCrewAIフレームワークを活用しましたが、ハッカソンの提供するシステムの制約を満たしつつ、CrewAIフレームワークを活用した柔軟なマルチエージェントシステムを構築する必要がありました。フレームワークの標準機能だけでは実現困難な部分を補うため、独自のAPI連携機能を開発するなど、フレームワークから外れた概念を含む全体システムの設計を必要としました。
今回のハッカソン期間では実装できませんでしたが、今回の実装をさらに進化し理想のコンセプトに近づけるため、以下の4つの観点で改善の可能性を見出しています。
1.RAG: クエリ拡張
2.RAG: チャンキング / インデックス化
3.エージェントワークフロー
4.Azureのベストプラクティス活用
機能実装を優先するあまり、Azureの強力な機能を十分に活用しきれなかった点は大きな反省点です。
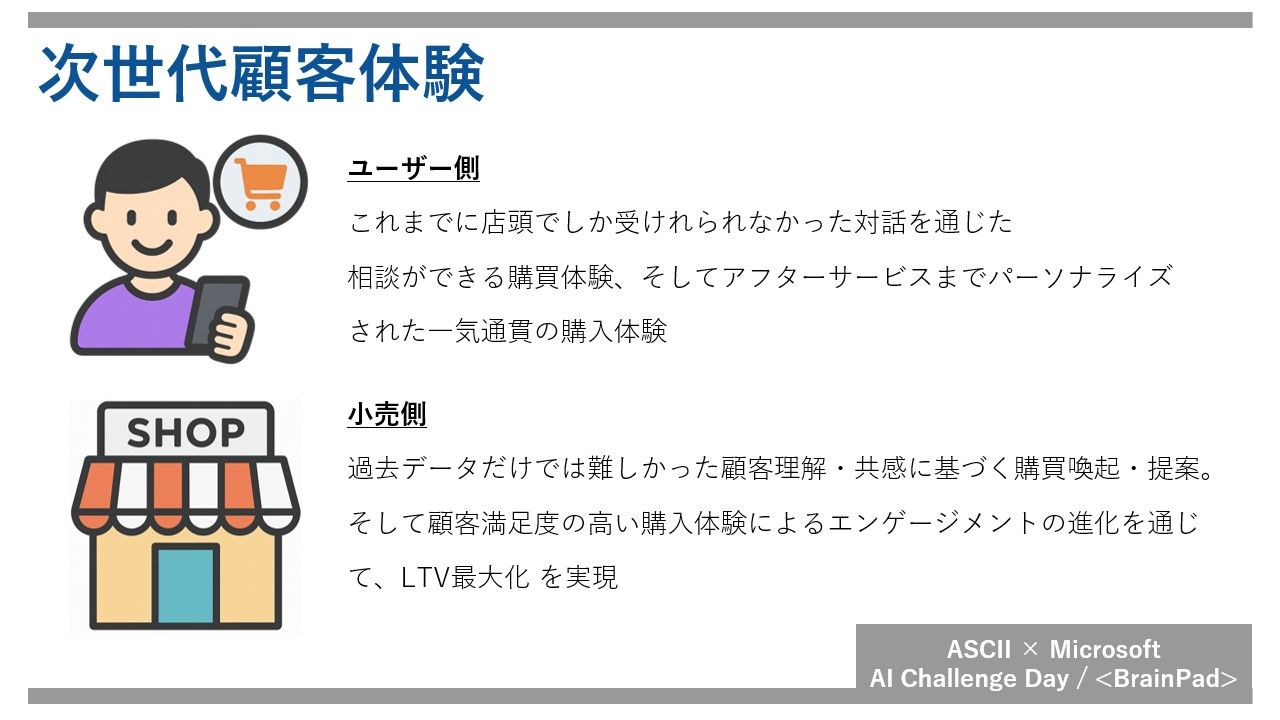
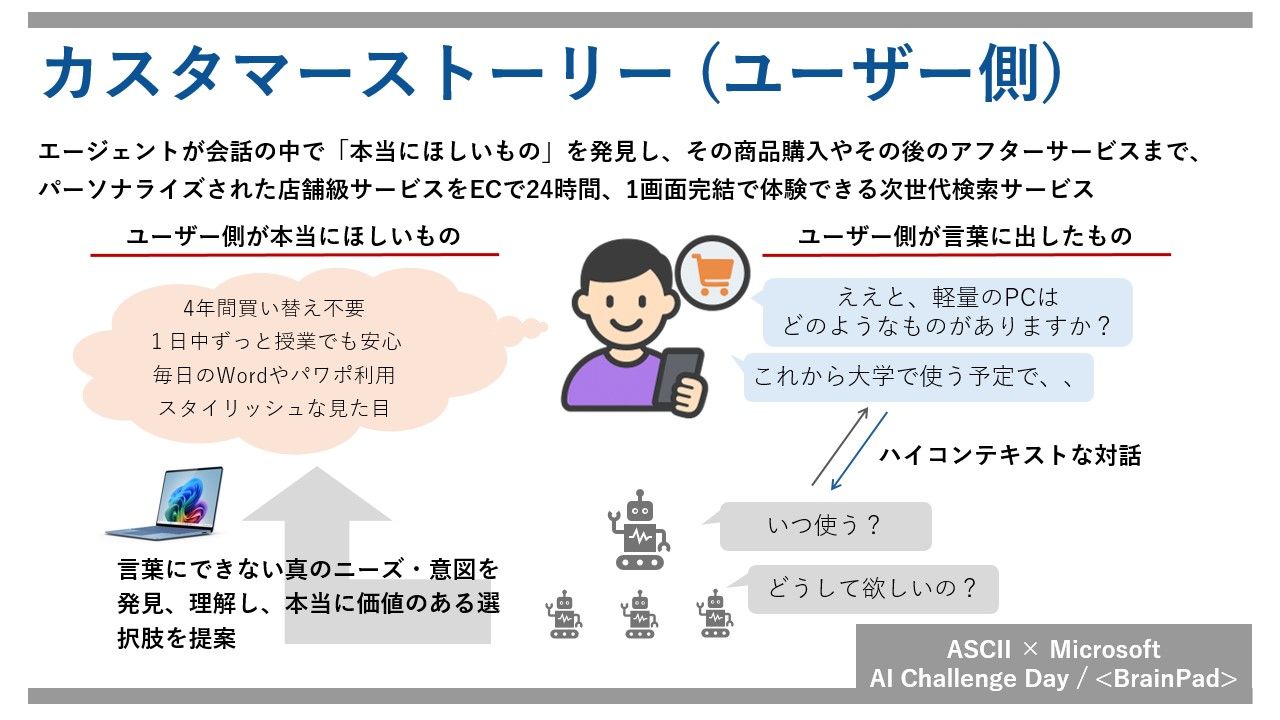
私たちは、目指したカスタマーストーリーでは、AIアシスタントが単なる高機能なアシスタントではなく、すべての顧客の「専属の担当営業」となる究極のパーソナル体験を提供することを目指しています。
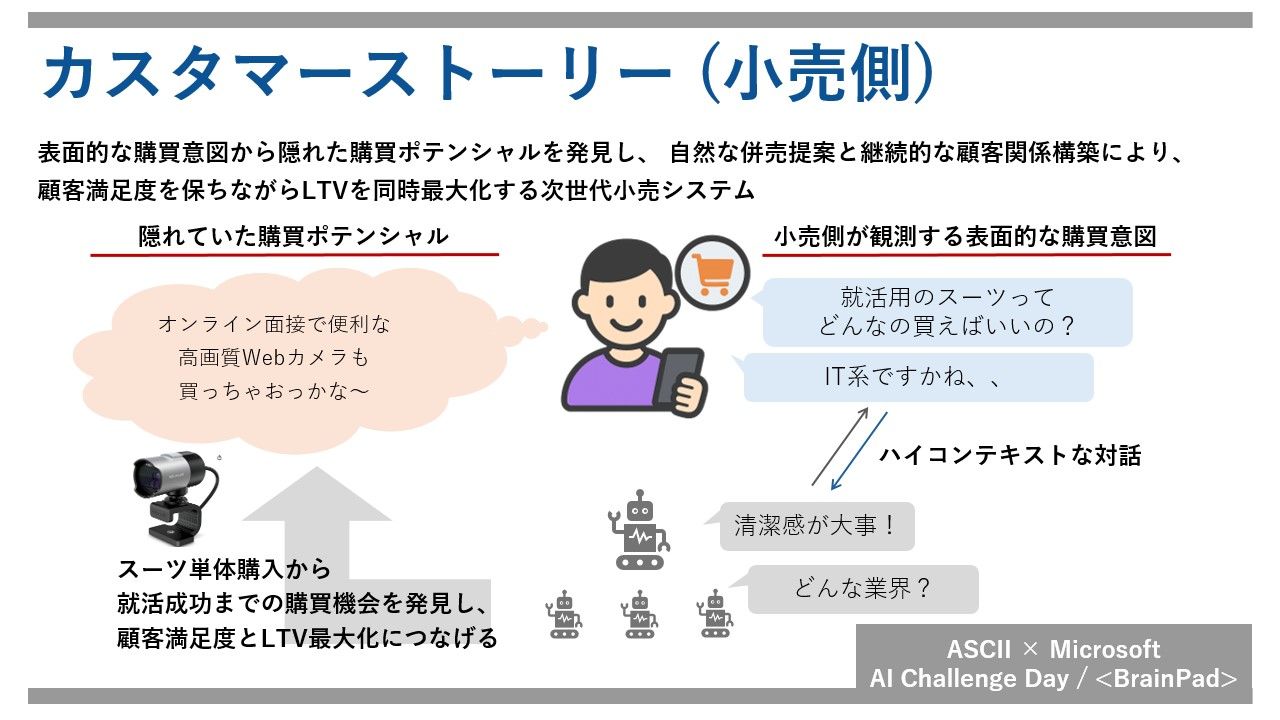
「スーツが欲しい」顧客に対し、従来の検索エンジンであれば「スーツ」と検索し、その結果を提示するだけで終わっていたところを、我々の目指すAIアシスタントは、「何色のスーツが欲しいのか?」「背丈とウエストはどのくらいか?」「どうしてスーツが欲しいのか?」ということを自律的に質問します。質問に対して顧客から「黒いスーツが欲しい」「身長は170cmで、ウエストは76cm」「就活で必要になったから欲しい」という回答が得られれば、顧客が本当に欲しいものは ”検索上位に提示されるありふれたスーツ” ではなく ”清潔感のある細見の黒いリクルートスーツ” であるとAIアシスタントは判断して提示します。顧客が就活生と分かれば、ネクタイやオンライン面接で利用するWebカメラも必要かもしれないと推測し、顧客の気付かない潜在的需要もAIアシスタントは自律的に推測して提案します。顧客の買い忘れ防止と店舗のクロスセルが両立した接客になります。
このような購入体験を繰り返すことで、購買履歴だけでなく、顧客の嗜好やショッピング思想が蓄積されます。顧客が数年後に再びスーツを購入しようとした際、AIアシスタントは顧客が既に持っているネクタイに良く似合う、顧客好みのスーツを提案できます。さらに何も言われずとも、値段やポイントの付与対象かどうかといった、顧客が購入時に気にしていることを織り交ぜた接客が可能です。顧客からすれば「専属の担当営業」による、最高の購買体験となります。
今回のハッカソンでは構築しきれなかった自律的な質問機能の実装や精度向上施策を再検討することで、この理想の次世代の顧客体験提案アシスタントの構築は可能と考えています。
ブレインパッドには今回ハッカソンに参加した若手データサイエンティスト以外にも、小売業界のスペシャリストや生成AIのスペシャリストが多数在籍します。社内にも今回の学びを持ち帰り、多様な視点を取り入れながら、さらなる精度向上に励みたいと思います。
【参考】
データ活用のパイオニアとして最前線を走り続けてきたブレインパッドが“データのプロ”のノウハウを集約した、小売業向けソリューション
停滞するDXを打開する“AIエージェント”――経営改革の新たな推進力
このような貴重な機会を頂き、最新技術に触れる貴重な機会をくださった日本マイクロソフト様、角川アスキー総合研究所様、そして運営を支えてくださった皆様、誠にありがとうございました。
あなたにオススメの記事

2023.12.01
生成AI(ジェネレーティブAI)とは?ChatGPTとの違いや仕組み・種類・活用事例

2023.09.21
DX(デジタルトランスフォーメーション)とは?今さら聞けない意味・定義を分かりやすく解説【2024年最新】

2023.11.24
【現役社員が解説】データサイエンティストとは?仕事内容やAI・DX時代に必要なスキル

2023.09.08
DX事例26選:6つの業界別に紹介~有名企業はどんなDXをやっている?~【2024年最新版】

2023.08.23
LLM(大規模言語モデル)とは?生成AIとの違いや活用事例・課題

2024.03.22
生成AIの評価指標・ベンチマークとそれらに関連する問題点や限界を解説
















