



メルマガ登録
-
テーマから探す
-
技術から探す
-
業界・事例から探す
-
関連トレンドから探す
テーマから探す
技術から探す
業界・事例から探す
関連トレンドから探す

こんにちは、株式会社ブレインパッド アナリティクスコンサルティングユニットの小澤、久津見です。
生成AI (Generative AI) は、テキスト、画像、音声、音楽など様々なコンテンツ生成が可能で、世界中から注目を集めています。特に、ChatGPTなどで利用されている大規模言語モデル (Large Language Models, LLM) は、まるで人間のような言語理解能力と自然な言語生成能力で知られ、ビジネスシーンでの活用も積極的に検討されています。
【関連記事】
生成AI(ジェネレーティブAI)とは?ChatGPTとの違いや仕組み・種類・活用事例
LLM(大規模言語モデル)とは?生成AIとの違いや活用事例・課題
カスタマーチャットボットや法律文書自動生成など専門領域での応用においては、特定の業界や分野(以下、ドメイン)に特化した生成AI(特にLLM)の開発が不可欠です。また、ドメインに特化したLLMの運用に先立って信頼性の評価が極めて重要です。そのためには専門用語理解、タスク遂行能力、倫理的観点などを正確に測定できる独自の評価フレームワークの構築が求められます。
ところが、昨今の生成AI技術の進化の速さもあり、評価フレームワーク構築について議論が追い付けていないのが現状です。正確な評価の欠如は、AIによる提案や意思決定補助が人間のニーズや倫理基準と乖離し、重大なインシデントを引き起こすリスクとなります。
本連載では数回にわたって、
などについて、ビジネスリスクや現在直面している課題・最新の研究と併せて詳しくご紹介します。
本連載の一本目である本記事では、LLMのドメイン特化の必要性と課題、そして評価アプローチの概要について詳しく解説します。


ChatGPTのように一般ユーザーが利用できるLLMサービスの基盤モデルは、法律や医療などのドメインに特化していないため、専門知識を要するタスクには対応できません。そのためビジネス活用においては、特定ドメインに特化したLLMが必要となります。
ドメイン特化型LLMの具体的な活用例としては以下のようなものがあります。
■人材業界に特化:ChatGPTを利用し360万件以上の転職口コミ情報を要約するシステムを開発
転職口コミサイト『転職会議』、ChatGPTのAIを活用した企業口コミの要約情報を提供開始
■旅行業界に特化:ChatGPTを利用した外国人観光客向けの多言語AIチャットボット開発
訪日外国人や越境EC事業者をサポート!Chat-GPT (GPT-3) をインバウンド施設、越境EC向けにAI学習させた「多言語チャットコマース」のサービス提供を開始
■自動車業界に特化:会話による音楽再生・訪問先の情報提供可能なChatGPT搭載自動車の開発
メルセデス・ベンツ、アメリカでChatGPTを車に試験搭載
これらのドメイン特化型LLMの活用は、業務効率化だけでなく、顧客満足度の向上、新たなビジネス機会の創出、そして競争上の優位性確保にも大きく貢献します。
また、ドメイン特化を達成する手法としては様々な方法が研究および提案されています。
| ドメイン特化の手法 | 概要 | 参考URL |
|---|---|---|
| Fine-Tuning | 追加学習によりドメイン知識を学習させる | 社内文書に特化したChatGPT ファインチューニング実践編 |
| Instruction Tuning | 追加学習によりタスクの解き方を学習させる | GPT-4登場以降に出てきたChatGPT/LLMに関する論文や技術の振り返り |
| Prompt Engineering | プロンプトに指示の詳細を与えながら出力の最適化を行う | プロンプトエンジニアリングの基本と応用 OpenAIのHPより – Prompt engineering |
| Retrieval Augmented Generation (RAG) | ユーザーからの質問に対して外部データを基に回答を生成する | プロンプトエンジニアリング手法 外部データ接続・RAG編 |
| Reinforcement Learning from Human Feedback (RLHF) | 人間からのフィードバックを用いた強化学習を行う | ざっくりわかるRLHF(人間からのフィードバックを用いた強化学習) |
ドメインに特化したLLMを成功させるためには、複数のKPIを基にした多面的な評価が欠かせません。QAチャットボットを例にとると、回答の精度や速度だけでなく、ユーザー満足度や倫理面、バイアスへの考慮なども必要です。
多方面への考慮が必要となってくるため、専門家、エンドユーザー、ビジネスリーダーなど各ステークホルダーの認識や意見のすり合わせも必要となります。Sun et al. (2024) では、LLMの信頼性を評価する観点を8つに分類し、それをさらに細分化しながら評価方法について考察しています(詳しくは次回の記事で)。このように、様々な観点による評価の必要性がLLMのビジネス活用における大きな課題となっています。

ドメインに応じたLLMの学習や評価には、高品質なデータセットが不可欠です。まず、ドメイン固有の言語パターン、専門用語、文脈やニュアンスを含んだ文章を収集する必要があります。データを収集した後、評価用データセットとして用いるには、正解データの作成が必要になります。LLMの場合、翻訳や要約タスクなど、唯一無二の正解データを作成するのが難しいタスクがほとんどです。高品質な正解データを用意するには、そのドメインに特化した専門家や複数人による正解データの作成が必要なため、工数の掛かる作業となります。

一般的な機械学習モデルの活用や分析モデルの活用と同様に、ドメイン特化したLLMの活用においても性能改善のための反復的なテストや評価、及びその結果を受けたモデル改善が必要となります。
一方で、自然言語の性質上LLMの入出力に対する定量的な評価は難しく、機械学習の一般的な定量的評価指標(Precision, Recall, F1スコアなど)だけでは評価しきれないことがあります。Liu et al. (2008) によれば、定量的評価指標の結果と人間の好みの相関関係は低いことが指摘されています。またLLMの評価用ベンチマークが多数公開されているものの、汎用的なデータセットが多く、実際のビジネスではより特定タスクに絞られたデータセットが必要になります。そのため、最終的には専門家による人力評価が必要になることが多く、性能改善のために高品質な反復テストを行うには多大なコストや工数が掛かることが大きな課題となっています。
ここまで述べてきたように、ドメイン特化型LLMの活用はビジネスにおける競争上の優位性確保の大きなチャンスとなり得る一方で、多くの課題も残されており、特に評価部分において莫大なコストが掛かりがちです。
シンプルなLLMの評価方法としてROUGEやBLEUといった古典的なマッチングベースの評価などがあります。ところが、どの手法も単語レベルでのPrecisionやRecallといった正解との差分に焦点を当てた評価しかできないため、ビジネス上の判断で用いるのは難しいでしょう。Chang et al. (2023) でも紹介がある通り、近年はLLM評価用ベンチマークも数多く提案されています。しかし、Rakuda ベンチマークでも指摘がある通り日本語専用のベンチマークが少ない問題に加え、実際のビジネスで使うデータと近い分布のデータセットでの評価ではないため、ベンチマークによる評価結果をビジネス上で過度に信用するのは危険です。
最近では、コストを掛けずに出来るだけ高品質な評価を得る方法として、LLMによる出力の自動評価機能の構築が多く提案されています。
評価指標、ベンチマーク、LLMによる自動評価など具体的な評価方法は次回以降の記事でご紹介します。
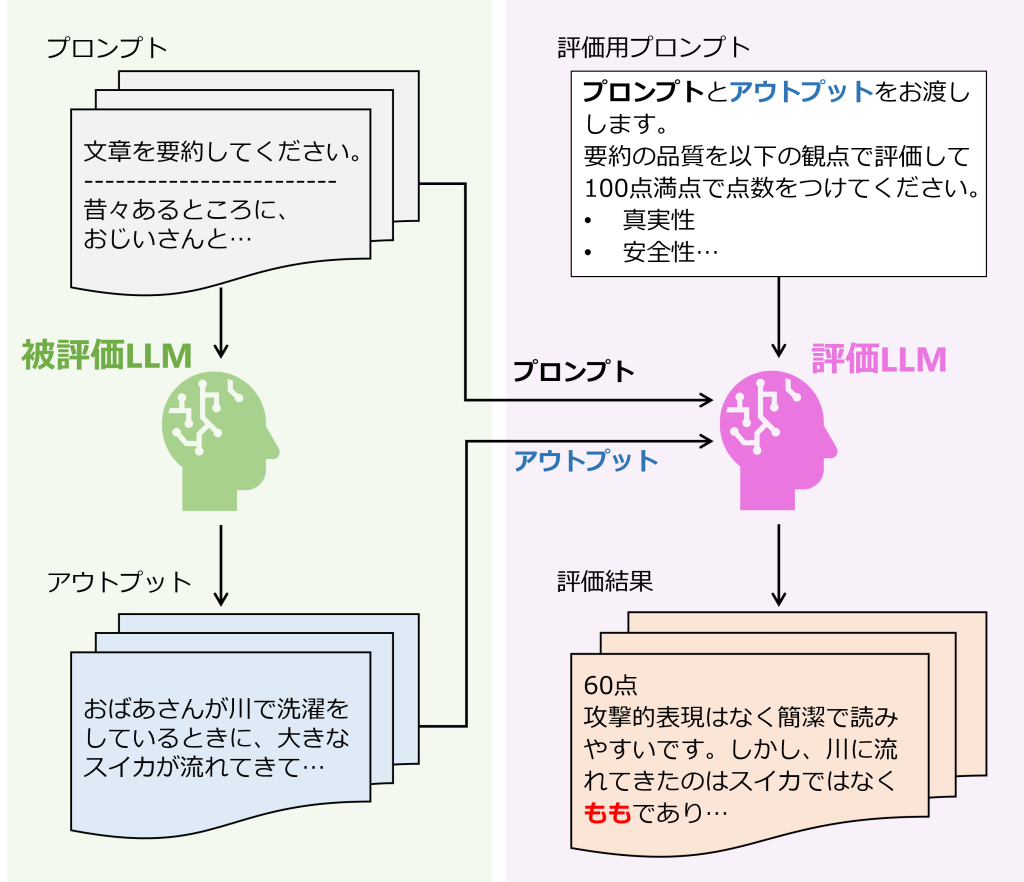
Kocmi and Federmann (2023) や Zheng et al. (2023)など複数の研究によれば、専門家による評価とLLMによる自動評価の間には高い相関性があることが明らかとなっています。とはいえ、そのほとんどは特定のベンチマークによる検証のみが行われていることが多いため、ビジネスで活用する際のデータセットでも同様に高品質の結果が得られるとは限りません。実際にビジネスでLLMを活用する場面では業種・業務ごとの細かいレベルで工夫が必要になるでしょう。
LLMによる自動評価技術がドメイン特化に強いとはいえ、業種、企業、業務レベルの細かい粒度まで対応しているとは言えません。実際には各業界・業種・企業ごとに評価するタスクや評価観点の重要性は異なります。単純にLLMに自動評価させるだけではなく、提案手法を参考にしながらも業務環境にあったプロンプトへの書き換えや評価観点の優先順位付けなど、より実用的な視点でLLMを評価する姿勢が重要になるでしょう。
LLMのビジネス活用においては、特定ドメインへの特化が必要でした。社内チャットボット、カスタマーサポート、文章自動生成ツールなどへの適用により、業務効率化や顧客満足度の向上が期待できます。しかし、これらの成功はLLMの信頼性が担保されていることが前提です。LLMの各タスクにおける評価指標やベンチマークが数多く提案されているものの、どのような評価方法もこれまで紹介した信頼性のごく一部しかカバーすることができません。また新たな評価方法としてLLMによる自動評価なども提案されており、LLMの出力を改めてLLMに問いただすことで様々な観点を考慮することができます。一方で、実際のビジネスでLLMによる自動評価を適用するにはKPI(評価観点)の設定やそれに応じたLLMプロンプトの調整、結果の解釈やそれに応じたモデルの改善などが必要であり、多くの工数が必要です。
LLMの信頼性の評価は非常に複雑で難しく、KPIに基づいた評価指標の設定と、様々な観点からの評価サイクルの確立が不可欠です。LLMのビジネス活用に向けて抑えておくべきポイントに注意を払いながら、安全に利用していく必要があります。次回のブログでは、LLMの信頼性を担保するために必要な様々な評価観点についてご紹介します。
あなたにオススメの記事

2023.12.01
生成AI(ジェネレーティブAI)とは?ChatGPTとの違いや仕組み・種類・活用事例

2023.09.21
DX(デジタルトランスフォーメーション)とは?今さら聞けない意味・定義を分かりやすく解説【2024年最新】

2023.11.24
【現役社員が解説】データサイエンティストとは?仕事内容やAI・DX時代に必要なスキル

2023.09.08
DX事例26選:6つの業界別に紹介~有名企業はどんなDXをやっている?~【2024年最新版】

2023.08.23
LLM(大規模言語モデル)とは?生成AIとの違いや活用事例・課題

2024.03.22
生成AIの評価指標・ベンチマークとそれらに関連する問題点や限界を解説













