



メルマガ登録
-
テーマから探す
-
技術から探す
-
業界・事例から探す
-
関連トレンドから探す
テーマから探す
技術から探す
業界・事例から探す
関連トレンドから探す

第7回(前回)で生成AIのひとつである拡散モデルの概要と適用事例を紹介しました。今回の記事では、既存の応用研究を再現しつつ、実際のビジネス面での活用を想定して議論・考察します。生成AIは画像生成や動画生成に関してはメディアで取り上げられることが多く、広く知られていると思われますが、それ以外の用途が一般的に取り上げられることは少ないのが実情です。本連載では、弊社での応用研究に携わった社員を交えて、より具体的な将来の課題についても考えていきたいと思います。


株式会社ブレインパッド・角谷 督(以下、角谷) 今回は、拡散モデルの応用研究に携わった弊社の若手社員を交えて、応用研究の結果やそこから示唆される活用方法や将来の課題について議論していきたいと思います。まずは、今回の研究では、ふたつのテーマを扱っています。ひとつがテーブルデータの生成精度の検証であり、ふたつ目が因果推論に関する適用事例の実証研究です。ここで、ひとつ目の研究に携わった弊社の若手データサイエンティストを紹介します。平田さん、簡単に自己紹介をお願いします。
株式会社ブレインパッド・平田 直樹(以下、平田)はい。2024年にデータサイエンティストとして入社した平田 直樹です。 大学・大学院では素粒子理論物理学を専攻しており、その延長としてデータや数理を扱う仕事に関心を持ち、入社しました。 入社後はマーケティング分野にて、機械学習モデルの構築を通じ、ユーザーの購入促進や満足度向上につながる施策を検討する分析業務に従事してきました。現在は、拡散モデルなどの深層学習技術をデータサイエンスの現場で活用していくことに関心を持っています。本日はどうぞよろしくお願いいたします。
株式会社ブレインパッド・山崎 清仁(以下、山崎)平田さん、よろしくお願いします。早速ですが、実際にはどのようなテーマで研究をされたのでしょうか?
平田 はい。私が取り組んだテーマは表形式データの生成に関するものです。拡散モデルは汎用的なデータ生成技術ですので、この記事を通して、様々な応用分野への広がりを感じてもらいたいと思っています。
山崎 データ生成というと、単純なデータのコピーとは違いますよね。コピーとは、何が異なるのかを簡単に説明してもらえますか。
平田 そうですね。コピーとの違いは、オリジナルデータに共通する特徴を備えながら、元データとは異なる新しいデータを生成するということです。例えば、人の顔であるなら、目や口、鼻の配置はおおよそ共通ですが、それぞれの形には個々人の固有の特徴があります。生成AIでは共通の特徴は保持しながら、固有の要素を新たに生成して、オリジナルとは異なるデータを生成するということになります。
山崎 今回は表形式データを使った実証研究ということですが、表形式を扱った理由について教えてください。
平田 表形式におけるデータ生成では、古典的なやり方としては、モンテカルロシミュレーションなどがあります。様々な分野で使われている手法ですが、古典的な方法と拡散モデルではどのような違いがあり、その有用性は何かというところを明確にしたいという意図がありました。
角谷 モンテカルロシミュレーションは、金融分野でも多用されてますよね。古典的な方法では、過去データを用いて相関構造を保ったまま、シナリオとなる資産収益率データを大量に生成して、VaR(99%タイル点などのテールリスク)を推定したりします。さきほど説明していただいたデータの共通の特徴としては、資産の期待値や資産間の共分散などの1次、2次モーメントとなりますので、それを保ったまま様々な資産の収益率シナリオを新たなデータとして生成することになります。拡散モデルで扱うデータの共通の特徴とは、どのようなものになりますか。
平田 拡散モデルでも統計的な性質は結果的に忠実に再現されていると思いますが、明示的にモーメントマッチング(新たに生成されるデータの期待値や分散などをオリジナルデータに一致させること)するわけではありません。データ構造全体を学習するので、尖度や歪度などのより高次の統計的性質も保たれる可能性があり、より正確なモンテカルロシミュレーションが実現できると思われます。
角谷 なるほど。高次のモーメントまで一致させた複数の乱数を生成するのは大変ですが、AIでデータ構造を学習してしまえば、結果として統計的な性質は満たされたデータが生成されているであろうと推測できるということですね。
平田 はい。ですから、テールリスク管理を目的としてシミュレーションするなら、拡散モデルで生成されたデータのほうが有用である可能性は高いと思います。
山崎 問題意識は理解しました。それでは、今回の具体的な検証内容について教えてください。
平田 今回は、拡散モデルを使って表形式データを生成するTABSYN※1を用いて検証しました。実証研究の詳細は拡散モデルのデータサイエンスへの応用事例で公開しているので、そちらを参照してほしいのですが、簡単に研究デザインについて説明します。まず、元データとして表形式のデータを用意します。そして、TABSYNを用いて、当該データの構造を学習し、その学習モデルから新たなデータを生成することになります。その評価は、
としました。
※1 参考文献:H. Zhang et al., Mixed-Type Tabular Data Synthesis with Score-based Diffusion in Latent Space. In Proc. ICLR, 2024; arXiv:2310.09656
角谷 評価項目ですが、1と2以外に3も必要となるのでしょうか。
平田 そうですね。1で統計的性質を調査していますが、統計的性質を表す指標を選択・定義すると、それ自体が恣意的になってしまうという批判が考えられます。そのため、様々な機械学習モデルを用いて、元データと新たに生成したデータ間で学習モデルの性能が低下していないことを示すことも重要と考えたからです。
山崎 検証結果からどのような知見が得られたのでしょうか。
平田 統計的性質が近いことを示すために、オリジナルデータと生成データ間で、分布の比較をしています。また、複数のデータ項目間で相関係数も比較しました。結果、分布の裾野の広がりも再現できており、生成データは元データの平均や分散だけでなく、より高次のモーメントまで表現できていると思います。
山崎 2つの分布を比較して、近似していることを示すためにQ-Qプロット(Quantile-Quantile Plot)を使ってますね。簡単に説明してもらえますでしょうか。
平田 はい。Q-Qプロットは、2つの確率分布の分位点を比較するための手法です。一方の分布の分位数をx軸に、もう一方の分布の分位数をy軸にプロットし、散布図として表示します。2つの分布の分位点が一致していれば、斜め45度の直線状にプロットされます。例えば、ある分布が正規分布に従っているかどうかを調べたい場合、X軸に標準正規分布の理論値を取り、Y軸にサンプルデータを標準化した値を取ることになります。(下図参照)
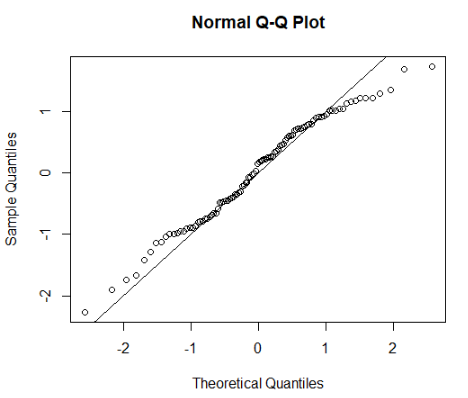
図では、両端で45度線から大きく外れているので、分布の裾野の広がりが正規分布とは異なっていることがわかります。経験分布同士を比較するときは、理論値はわかりませんので、分位数同士を比較することになります。
山崎 なるほど。特定の分位数を選択して比較するのではなく、全体を視覚的に確認できるのですね。
平田 はい。今回の実験で得られたQ-Qプロットの例を以下に示します。
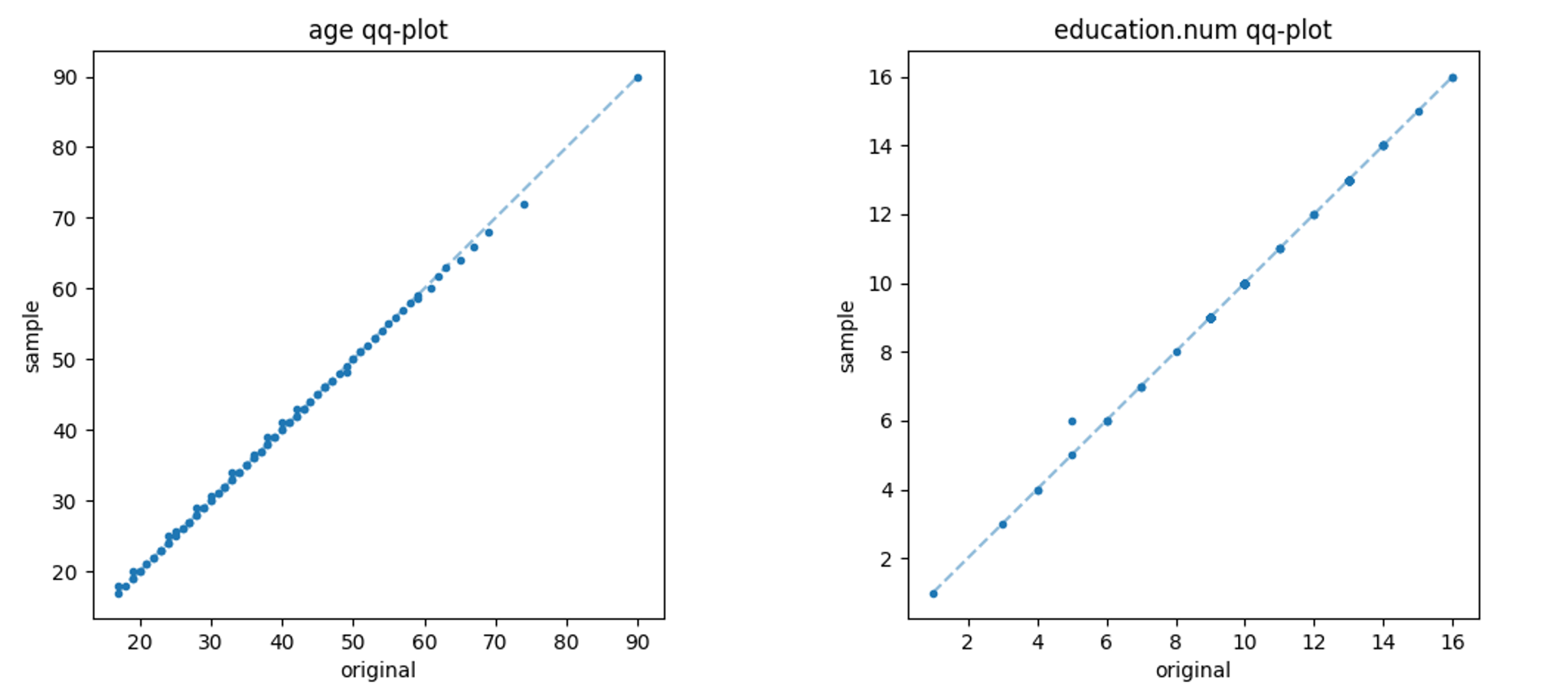
図は、年齢と教育年数の変数分布の例です。X軸にオリジナルデータ、Y軸に生成データの分位の値を取っています。値が一致すれば、45度線上に完全に一致することになります。当該図のプロットが概ね対角線上にあり、再現性が高いことがわかると思います。
角谷 うまく生成できていそうですね。では、次に機械学習モデルによる精度劣化の評価の具体的な検証方法と評価結果を教えてもらえますか。
平田 機械学習モデルによる検証は、オリジナルデータを学習データとテストデータに分離し、学習データだけを使って生成AIモデルで新規の学習データを作りました。オリジナルの学習データで学習したモデルと生成した新規の学習データで学習したモデルを、同一のテストデータに適用して精度を比較することで、精度の劣化が生じていないかどうかを確認しました。同時に、拡散モデル以外の複数の生成AIモデルに関しても同様の検証をしました。
結果としては、オリジナルのテストデータの結果が最も精度が高く、その次が拡散モデルでした。当該実験の結果だけから判断すると、生成AIとしては、拡散モデルがオリジナルデータをよく再現することができていたといえると思います。(下図参照)
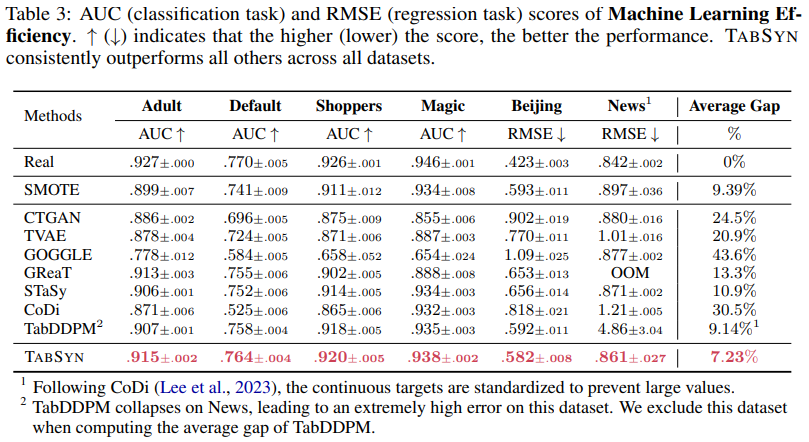
角谷 生成AIモデルの中で、拡散モデルの精度が優れているのは理解できましたが、オリジナルのデータと比較すると少し劣化しているようですね。この劣化度合いが、推定誤差の範囲内といえるかどうかという点に関しては如何でしょうか。
平田 おっしゃられた件に関しては、オリジナルデータのテストデータを複数用意して、拡散モデルで生成したテストデータも加えて、それぞれに対して機械学習モデルの精度を比較することが必要ですね。今回は、そこまで詳細な実験は実施しておりませんが、今後その観点でも実験してみたいと思います。
山崎 今回の実験は、既存の論文を再現したものと聞いていますが、研究における苦労や工夫に関しても教えてもらえますか。
平田 はい。工夫した点としては、生成データの統計的な評価だけでなく、データサイエンスの現場での活用を想定した評価項目を設定したことです。具体的には、1.クライアントの秘匿性が高いデータを生成データ(ダミーデータ)に置き換えてPoCを行うこと、2.不均衡データ予測におけるオーバーサンプリング手法として利用すること、の2つの活用シーンを想定していました。 そのうえで、1.については、先ほどご説明したような機械学習モデルによる精度劣化評価を実施し、2.については、実務で広く使われているオーバーサンプリング手法であるSMOTEと比較しながら、生成データの品質検証を行いました。
角谷 前述した金融機関におけるVaRの推定などの応用事例が考えられると思うのですが、その点に関しては、どのように考えていますか。
平田 そうですね。例えば、リーマンショックが生じたときに、VaRの推定がどの程度の予測精度を保ち得るのかを調べたいと思ったときに、学習データとテストデータに分離するとデータ量が不足するような事態も考えられます。その際、生成AIのような技術があれば精度の高いデータを人工的に作り出すことができます。もうひとつの研究テーマである因果推論の研究と組み合わせれば、ストレステスト(市場に不測の事態が発生した場合を想定して、ポジション損失の度合いをシミュレーションして確認する検証方法)にも応用できると思います。今後、金利が急騰すれば、株価がどれほど影響を受けたりするかなど、仮想現実をシミュレーションすることができます。金融分野だけに関わらず、マーケティング分野においてもレコメンド施策を提示した場合、顧客の購買行動がどのように変化するかをシミュレーションするなどの適用も面白いと思いますね。
山崎 今回は、平田さんを招いて、生成AIのモデルのひとつである拡散モデルを用いて、研究結果を説明させていただきました。研究テーマとしては、もうひとつ、前述した因果推論もあります。次回はそちらのテーマに関しても、実証分析結果をご紹介し、今後の実社会への適用可能性を議論していきたいと思います。次回も実際に研究を推進した若手データサイエンティストを交えて、議論を展開したいと思います。平田さん、今後も面白い研究成果が出れば、ぜひお話ください。
平田 はい。ぜひお願いします。
山崎 今回はご参加いただき、ありがとうございました。
あなたにオススメの記事

2023.12.01
生成AI(ジェネレーティブAI)とは?ChatGPTとの違いや仕組み・種類・活用事例

2023.09.21
DX(デジタルトランスフォーメーション)とは?今さら聞けない意味・定義を分かりやすく解説【2024年最新】

2023.11.24
【現役社員が解説】データサイエンティストとは?仕事内容やAI・DX時代に必要なスキル

2023.09.08
DX事例26選:6つの業界別に紹介~有名企業はどんなDXをやっている?~【2024年最新版】

2023.08.23
LLM(大規模言語モデル)とは?生成AIとの違いや活用事例・課題

2024.03.22
生成AIの評価指標・ベンチマークとそれらに関連する問題点や限界を解説
















