



メルマガ登録
-
テーマから探す
-
技術から探す
-
業界・事例から探す
-
関連トレンドから探す
テーマから探す
技術から探す
業界・事例から探す
関連トレンドから探す

マルチモーダルAIとは、画像・音声・動画・テキストなど複数の情報を統合して理解し、判断や生成を行うAIです。生成AIの進化により、文章だけでなく視覚や音声を含めた自然なやり取りが可能になり、ビジネス活用も急速に広がっています。
一方で、「生成AIとの違いが分からない」「どのような仕組みで動いているのか理解しにくい」と感じる方も多いのではないでしょうか。AI活用を検討するうえで、技術の全体像を押さえることは重要です。
マルチモーダルAIは、「人間が目で画像を見て、耳で音声を聞き、文章を読んで状況を判断する」という流れに近い仕組みを持ちます。当記事では、基本概念から仕組み、できること、導入時の課題、今後の展望までわかりやすく解説します。
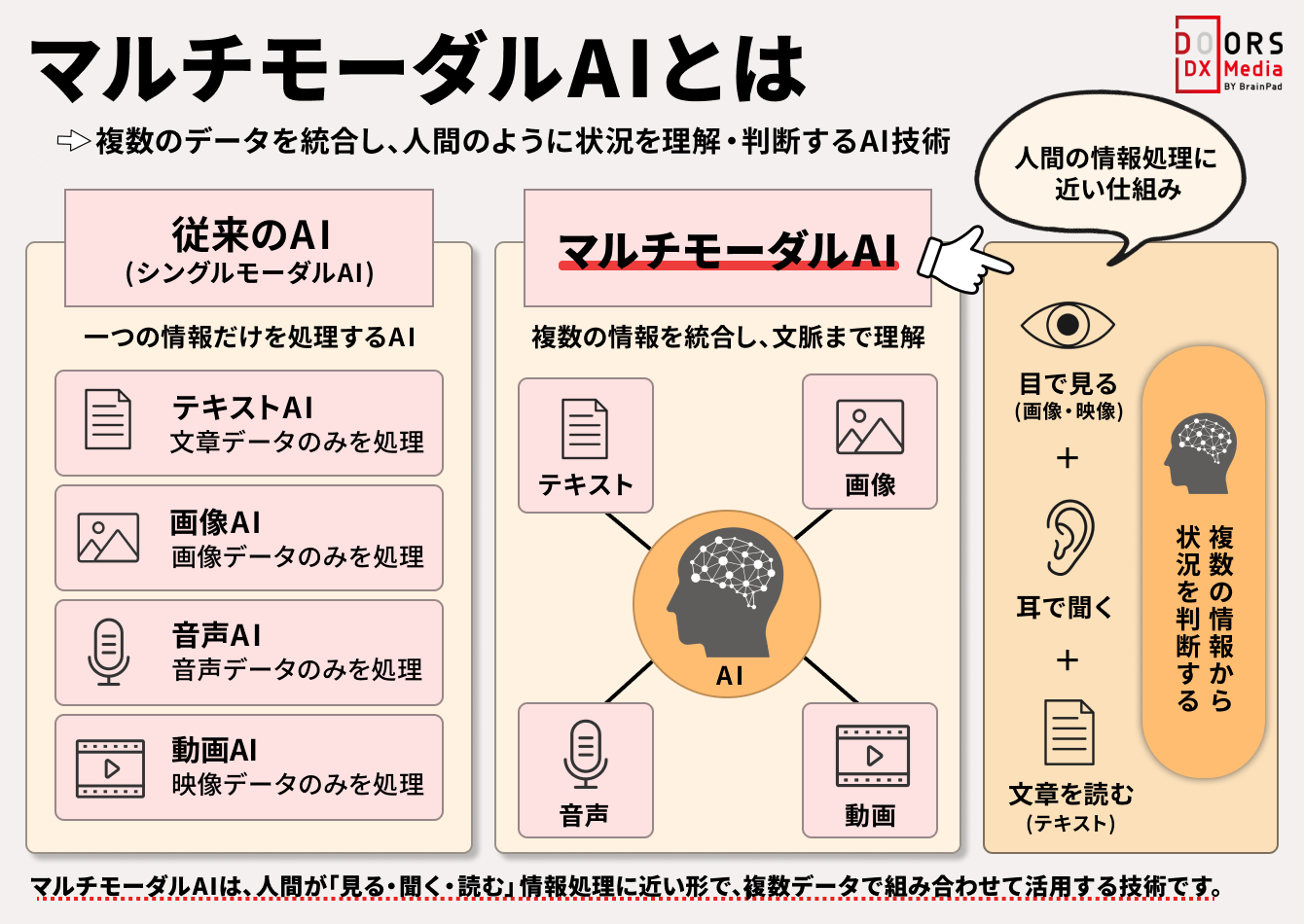
マルチモーダルAIとは、画像・テキスト・音声・動画など、異なる種類の情報をまとめて理解し、判断や生成を行うAI技術です。文章だけ、画像だけを扱う従来のAIと異なり、複数の情報を組み合わせて文脈まで捉えられる点が大きな特徴です。
人間が目で見て、耳で聞いて、文章を読んで状況を判断する流れに近い仕組みといえます。ここでは、マルチモーダルAIの基本的な考え方と、従来AIとの違いをわかりやすく整理します。
モーダルとは、AIが扱う「情報の形式」や「情報の種類」を指す言葉です。テキスト・画像・音声・動画は、それぞれ異なるモーダルに分類されます。人間に置き換えると、「目で見る情報」「耳で聞く情報」「文章として読む情報」の違いに近いイメージです。
受け取る情報が1種類だけの場合と、複数の情報を組み合わせて判断する場合では、理解の深さは大きく変わります。マルチモーダルAIを理解するうえでは、まず「情報には形式ごとの違いがある」という考え方を押さえることが重要です。
複数のモーダルを横断して扱うことで、AIはより人間に近い情報理解を目指せるようになります。
マルチモーダルAIは、画像・音声・テキスト・動画など、異なる種類の情報をまとめて理解し、判断や生成を行うAIです。単一の情報だけでは読み取りにくい文脈も、複数の情報を組み合わせることで把握しやすくなります。
例えば、画像の内容を理解しながら説明文を作成したり、音声の質問に対して画像の状況を踏まえて回答したりすることが可能です。近年はChatGPTやGeminiなどの生成AIでもマルチモーダル対応が進んでおり、AI活用の幅は大きく広がっています。
文章だけを処理するAIと比べて、より自然で柔軟なやり取りを実現しやすい点が大きな特徴です。
シングルモーダルAIとマルチモーダルAIの違いは、扱える情報の種類と活用できる業務の幅にあります。違いを簡単に整理すると、以下の通りです。
| 項目 | シングルモーダルAI | マルチモーダルAI |
|---|---|---|
| 扱う情報 | テキストのみ、画像のみなど1種類 | テキスト・画像・音声・動画など複数 |
| 得意なこと | 分類、要約、認識など単一タスク | 文脈理解、複合分析、生成 |
| 判断の特徴 | 特定条件に強い | 複数情報を組み合わせて柔軟に判断 |
| 活用例 | 文字起こし、画像分類 | 画像付き質問応答、音声+資料の要約 |
シングルモーダルAIは、単一の作業を効率よく処理したい場面に向いています。一方、複数の情報をもとにより高度な判断や自然な応答を求める場合は、マルチモーダルAIが適しています。
マルチモーダルAIが注目されているのは、画像・音声・テキストを組み合わせて扱えることで、AIが対応できる業務の幅が広がるためです。文章だけでは伝わりにくい状況も、画像や音声を組み合わせることで補いやすくなります。
単一の情報だけでは読み取りにくい文脈を補完できるため、業務自動化や高度な意思決定への応用も期待されています。
ここでは、マルチモーダルAIが必要とされる背景を整理します。
マルチモーダルAIが注目される理由のひとつは、複数の情報を組み合わせて文脈を理解しやすい点です。テキストだけ、画像だけといった単一の情報では、意図や状況を十分に読み取れない場面があります。
マルチモーダルAIは、画像・音声・テキストを横断して処理し、情報同士の関係を踏まえて判断します。画像の内容と説明文、音声のニュアンスをまとめて理解できるため、より自然で精度の高い応答が可能です。
人が目や耳から得た情報を総合して判断する流れに近く、従来のAIより柔軟な情報理解を実現できます。
【関連記事】
マルチエージェントシステムとは?概要や構造から導入するメリットまでを解説
生成AIの進化に伴い、マルチモーダルAIへの需要も高まっています。テキスト生成だけでは、現在のビジネスニーズを十分に満たしにくくなっていることが大きな理由です。
ChatGPTやGemini、Claudeなどの生成AIでも、画像理解をはじめとする複数モーダルへの対応が進んでいます。ユーザーが求めるやり取りも、文章入力だけでなく、画像を見せて質問したり、音声で指示したりする形へ変化しています。
生成AIの実用性をさらに高めるうえで、複数形式の情報を扱えるマルチモーダルAIは重要な技術です。
【関連記事】
生成AIとは?AIとの違いから仕組みや種類・活用事例まで幅広く解説
マルチモーダルAIは、業務自動化の対象を大きく広げる技術です。従来のAIは文章中心の処理が主流でしたが、近年は画像・音声・動画まで活用範囲が広がっています。
製造業では図面や検査画像の解析、医療では画像診断の支援、カスタマーサポートでは通話音声と会話ログの分析など、実務での活用が進んでいます。複数の情報をまとめて処理できるため、人による確認や判断の負担を軽減しやすい点も魅力です。
より具体的なユースケースを知りたい場合は、以下のマルチモーダルAIの事例をまとめた関連記事も参考になります。
【関連記事】
マルチモーダルAIの導入事例を紹介!代表モデルや業界別の活用方法とは?
マルチモーダルAIは、画像・音声・テキストなど異なる形式のデータをAIが理解しやすい形に変換し、関連性を整理しながら判断や生成を行う仕組みで動いています。学習時に情報同士の関係を学び、利用時にその知識をもとに回答を生成するイメージです。
専門的に見える技術ですが、全体の流れはシンプルです。
| ステップ | 処理内容 |
|---|---|
| ①入力 | 画像・音声・テキストなどの情報を受け取る |
| ②変換 | エンコーダでAIが扱える数値データへ変換する |
| ③理解 | Transformer(Attention機構を含む)で情報の関係性や文脈を整理する |
| ④出力 | 文章・画像・回答として結果を生成する |
複数の情報をそのまま処理しているわけではなく、一度共通の形に変換し、意味のつながりを読み取ったうえで回答を作成している点が特徴です。
ここでは、それぞれの仕組みを順番にわかりやすく解説します。
マルチモーダルAIでは、まず画像・音声・テキスト・動画など、異なる形式のデータを入力として受け取ります。複数の情報を同時に扱うことで、単一の情報だけでは読み取りにくい文脈や意図、状況の関係性まで捉えやすくなる点が特徴です。
例えば、画像と質問文を組み合わせて内容を説明したり、音声と関連資料をあわせて読み取り、発言の背景まで踏まえて要点を整理したりできます。ひとつの情報だけでは判断しにくい場面でも、複数の情報を組み合わせることで、より適切な理解につなげることが可能です。
この入力工程が、後続の変換・理解・出力の精度を左右する土台となります。
マルチモーダルAIでは、異なる形式のデータをAIが処理できる共通の形へ変換する工程が必須です。画像や音声は、そのままではテキストと同じ基準で比較しにくいためです。
その役割を担うのがエンコーダです。エンコーダは、画像や音声の特徴を抽出し、AIが計算できる数値データへ変換します。
変換後は、異なる種類の情報を同じ基準で扱えるようになり、画像とテキストの意味的な関係も判断しやすくなります。マルチモーダルAIが複数の情報を統合して理解できるのは、この変換工程があるからです。
マルチモーダルAIが複数の情報から適切な意味を読み取れるのは、重要な情報を選びながら処理する仕組みを備えているからです。入力されたすべての情報を同じ重みで扱うと、文脈を正確に捉えにくくなります。
その中心となるのが、Attention機構を備えたTransformerです。Attentionは、入力情報の中から関連性の高い要素を見極め、優先的に処理します。画像の特定領域と文章中の言葉を結び付けて理解することも可能です。
一方でTransformerは、こうした関係性を整理しながら全体の文脈を捉えます。自然な応答や高精度な理解を支える中核技術といえます。
マルチモーダルAIは、入力情報を変換・統合・解析し、最適な回答を生成する仕組みです。段階的に情報を処理することで、文脈に沿った自然な出力が可能になります。
まず、入力された画像や音声、テキストをエンコーダで数値データへ変換します。続いて、Attention機構を備えたTransformerが情報同士の関係を整理し、質問の意図や文脈を解析する流れです。
その結果をもとに、適切な文章や画像を予測し、最終的な出力へ変換します。自然な対話や的確な回答を実現できる背景には、この一連の処理が行われているためです。
マルチモーダルAIは、テキスト・画像・音声・動画など複数のデータを横断的に扱えるため、従来のAIより広い範囲の業務に活用できます。画像や動画の内容を文章化したり、音声と文書を組み合わせて要約したり、テキストから画像や動画を生成したりすることも可能です。
ここでは、マルチモーダルAIでできる代表的なことを解説します。
マルチモーダルAIは、画像や動画の内容を理解し、文章として整理できます。視覚情報を読み取り、意味のある言葉へ変換できる点が強みです。
Webサイトの画像に説明文を自動で付けたり、SNS投稿用の紹介文を作成したりする活用がすでに進んでいます。動画にも対応しており、防犯映像から異常を検知して報告したり、試合映像から重要シーンを抽出して要約したりすることも可能です。
製造業の外観検査や医療画像の解析支援にも応用が広がっています。人の目で確認し、内容を文章にまとめる作業を大きく減らせる点が、実務上の大きなメリットです。
マルチモーダルAIは、音声と文書を組み合わせて要約や検索を行うことが可能です。形式の異なる情報をまとめて扱えるため、情報整理の精度と効率が向上します。
会議の録音データと配布資料を同時に読み込ませれば、発言内容だけでなく資料の文脈も踏まえた議事録を作成できます。社内マニュアルや図表入り資料の検索にも有効で、音声による質問から必要な情報を探し出す使い方も可能です。
コールセンターでは、通話内容を分析しながら対応マニュアルを参照し、回答候補を提示する活用も進んでいます。情報活用のスピードを高めたい企業に有効な技術です。
マルチモーダルな機能を持つ生成AIでは、テキストの指示から画像や動画を生成できます。情報を理解するだけでなく、新しいコンテンツを生み出せる点も大きな特徴です。
例えば、「青空の下を走る犬」と入力すれば、その内容に沿った画像を短時間で生成することが可能です。近年は動画生成も進化しており、文章から短い映像を作る技術も実用化が進みつつあります。
広告用バナーやプレゼン資料の素材作成、試作品のイメージ共有など、クリエイティブ業務の効率化に役立ちます。一方で、著作権や内容の正確性の確認は欠かせません。便利さと管理の両立が重要です。
マルチモーダルAIは、検索やレコメンドの精度も高めます。テキストだけでは捉えにくい好みや雰囲気まで判断材料にできるためです。
例を挙げると、ECサイトでは、閲覧履歴だけでなく商品画像の特徴やデザイン傾向まで分析し、好みに近い商品を提案できます。「写真に似た服を探したい」といった視覚ベースの検索にも対応しやすくなります。
動画配信サービスでも、映像の雰囲気や音楽の傾向を踏まえた推薦が可能です。ユーザーが適切な言葉を思いつかなくても目的の情報へたどり着きやすくなり、顧客体験の向上や売上改善にもつながります。
【関連記事】
【セミナーダイジェスト】0件ヒットからの脱却!小売ECで導入が進む次世代の検索体験
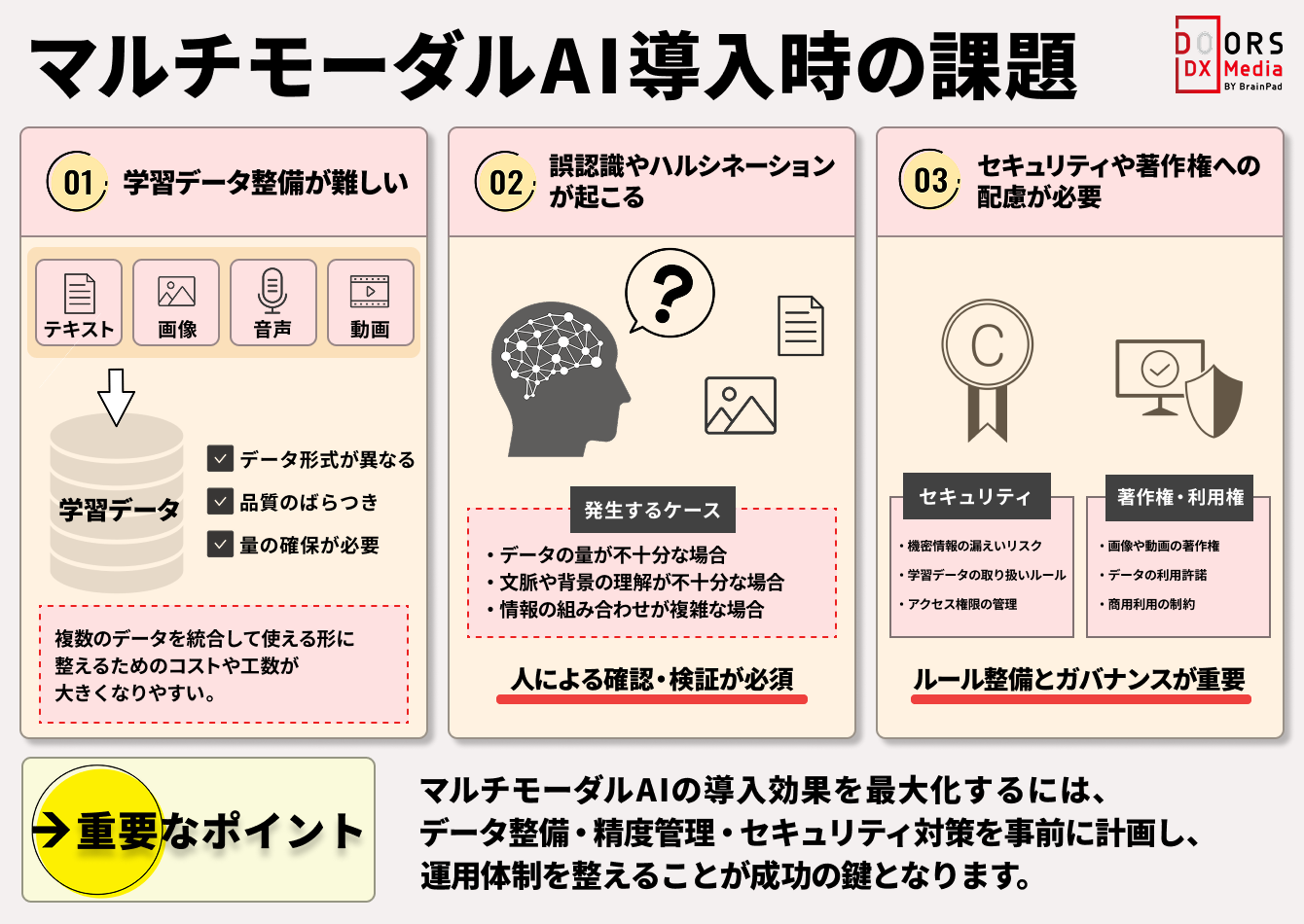
マルチモーダルAIは高性能である一方、学習や運用には課題もあります。画像・音声・テキストなど複数のデータを扱うため、データ整備や精度管理、セキュリティ対策の難易度が高くなりやすいためです。
導入効果を高めるには、メリットだけでなくリスクや運用上の注意点も理解しておく必要があります。
ここでは、マルチモーダルAIを導入する際に押さえておきたい主な課題を解説します。
マルチモーダルAIの導入では、学習データの整備が大きな課題になります。画像・音声・テキストなど複数の情報を組み合わせて学習するため、単一データを扱うAIより準備の難易度が高くなります。
| 項目 | シングルモーダルAI | マルチモーダルAI |
|---|---|---|
| 必要なデータ | 1種類 | 複数種類 |
| データ整備 | 比較的シンプル | 対応付けが必要 |
| 保管コスト | 低め | 高くなりやすい |
| 運用負荷 | 比較的低い | 高め |
動画であれば映像と音声、関連する説明文を正しく対応付ける必要があり、どれか一つでも品質が低いとAIの判断精度に影響する可能性があります。導入を成功させるには、AIモデルの性能だけでなく、継続してデータを整備・管理できる体制づくりまで見据えることが重要です。
マルチモーダルAIは高性能ですが、誤認識や誤回答のリスクを完全には避けられません。扱う情報が増えるほど、AIの解釈にズレが生じる余地も広がるためです。
画像と音声が食い違う内容を示している場合、AIが誤った文脈で判断することがあります。事実ではない内容を自然な文章で出力するハルシネーションも課題です。
特に、医療・製造・自動運転のように判断ミスの影響が大きい領域では、AIの結果をそのまま採用するのは危険です。人による確認を前提とした運用設計は必須となります。
マルチモーダルAIの活用では、セキュリティと著作権への配慮が不可欠です。画像・音声・文書まで幅広い情報を扱うため、リスクも多面的になります。
社内資料や会議音声を外部AIへ入力すれば、機密情報が意図せず漏れる可能性があります。学習に利用した画像や動画が著作権上の問題を含むケースもあるでしょう。
さらに、音声や映像を悪用したなりすまし被害も現実的な脅威です。利便性だけに目を向けるのではなく、利用ルールやデータ管理の方針を整えたうえで導入を進める必要があります。
マルチモーダルAIは、AIエージェントやロボティクスとの統合が進むことで、今後さらに活用領域が広がると考えられています。複数の情報を理解するだけでなく、状況に応じて判断し、リアルタイムに行動へつなげる技術としての発展も期待されています。
ここでは、AIエージェント・ロボティクス・リアルタイム処理の観点から、マルチモーダルAIがもたらす未来を解説します。
AIエージェントは「質問に答える存在」から「業務実行を支援する存在」へ進化すると考えられています。画像・音声・テキストをまとめて理解できるため、人間の意図や状況をより正確に読み取り、複数のタスクを横断して処理しやすくなるからです。
例えば、会議中の発言内容と資料を同時に読み取り、要点整理やタスク抽出、次のアクション提案まで行う活用が考えられます。将来的には、分析結果を提示するだけでなく、システム操作や業務手続きまで自律的に進める場面も増えるでしょう。
人間の役割は、作業の実行からAIの判断を管理し、方向づける立場へと変化していく可能性があります。
【関連記事】
AIエージェントとは何か?
Vertical AI(バーティカルAIエージェント)がもたらす可能性と事例から見る導入メリットを解説
マルチモーダルAIは、ロボットの判断力と柔軟性を大きく高める技術として注目されています。人間のように視覚情報だけでなく、音声や各種センサーデータも組み合わせて状況を把握でき、変化の多い現場にも対応しやすくなるからです。
例えば製造現場や物流倉庫では、人の音声指示や動作を理解しながら、安全に作業を補助するロボットの実用化が進むでしょう。形状が異なる商品を扱うピッキングや、人の往来が多い施設内の移動支援などにも活用が期待されています。
深刻化する労働力不足を補う選択肢としても、重要性が高まっています。
【関連記事】
製造業で導入が進むAIエージェントの最新事例やメリットを詳しく解説
マルチモーダルAIは、瞬時の判断が求められる領域でも活用が広がると見られています。複数の情報を同時に処理し、状況変化に応じて即座に判断できる点が大きな強みです。
例えば自動運転では、カメラ映像・距離情報・ドライバーの視線なども含めて分析し、危険を早期に検知します。監視分野では映像と音声を組み合わせて異常を素早く察知でき、リアルタイム翻訳でも、会話だけでなく資料や画面情報を踏まえた翻訳が可能になりつつあります。
今後は交通制御や都市インフラなど、社会全体を支える領域への活用も進むでしょう。
マルチモーダルAIは、画像・音声・テキストなど複数の情報を統合して扱えるAIです。一方で、生成AIやディープラーニングとの違いが分かりにくいと感じる人も少なくありません。
ここからは、マルチモーダルAIに関するよくある質問に対して、結論を先に示しながらわかりやすく回答します。
A. 生成AIはコンテンツを作るAI、マルチモーダルAIは複数の情報を理解・統合するAIです。
生成AIは、文章・画像・音声・動画など、新しいコンテンツを生み出すことを主な目的としています。一方、マルチモーダルAIは、画像・音声・テキストなど異なる形式の情報をまとめて理解し、判断する技術です。
両者は完全に別ではなく、近年の生成AIにはマルチモーダル機能を備えたものも増えています。マルチモーダルAIは、生成AIの活用範囲を広げる重要な技術です。
A. ディープラーニングはAIの基盤技術、マルチモーダルAIはその技術を活用した応用分野です。
ディープラーニングは、AIがデータから特徴やパターンを学ぶための基盤技術です。画像認識や音声認識など、多くのAIで使われています。
一方、マルチモーダルAIは、その技術を使って複数の情報をまとめて扱う仕組みです。技術そのものと活用方法の違いとして理解するとわかりやすいでしょう。
A. 医療、製造、EC、カスタマーサポートなど、幅広い業界で活用されています。
マルチモーダルAIは、複数の情報を組み合わせて判断できるため、幅広い業務で活用されています。
例えば製造業では異常検知、医療では診断支援、ECでは商品レコメンド、カスタマーサポートでは通話分析などに活用されています。単一データでは難しい文脈理解ができる点が強みです。
【関連記事】
医療分野のAI活用―社会実装に向けてのディスカッションで見えてきたこと
マルチモーダルAIとは、画像・音声・動画・テキストなど複数の情報を統合して理解し、判断や生成を行うAIです。従来のAIよりも人間に近い形で文脈を読み取り、複合的な処理を行える点に特徴があります。
生成AIの進化により、画像理解、音声処理、動画解析、検索やレコメンドの高度化など、活用範囲は広がっています。今後はAIエージェントやロボティクスとの連携により、判断から実行までを支援する技術として重要性が高まるでしょう。
マルチモーダルAIの活用を検討する際は、仕組みと課題を理解したうえで、自社の業務に合う導入方法を見極めることが大切です。AI活用やデータ活用でお困りの際は、お気軽にブレインパッドへご相談ください。
あなたにオススメの記事

2023.12.01
生成AI(ジェネレーティブAI)とは?ChatGPTとの違いや仕組み・種類・活用事例

2023.09.21
DX(デジタルトランスフォーメーション)とは?今さら聞けない意味・定義を分かりやすく解説【2024年最新】

2023.11.24
【現役社員が解説】データサイエンティストとは?仕事内容やAI・DX時代に必要なスキル

2023.09.08
DX事例26選:6つの業界別に紹介~有名企業はどんなDXをやっている?~【2024年最新版】

2023.08.23
LLM(大規模言語モデル)とは?生成AIとの違いや活用事例・課題

2024.03.22
生成AIの評価指標・ベンチマークとそれらに関連する問題点や限界を解説
















