



メルマガ登録
-
テーマから探す
-
技術から探す
-
業界・事例から探す
-
関連トレンドから探す
テーマから探す
技術から探す
業界・事例から探す
関連トレンドから探す

データとAIに関する世界最大規模のカンファレンス「Databricks Data + AI Summit 2026」(DAIS 2026)が、米国サンフランシスコで開催されました。
現地3万人、オンライン含め10万人以上と過去最大のカンファレンスで浮き彫りになったのは、AIブームの「その先」にある現実的な課題と解決策です。
これまでの「AIを活用するための基盤」から、企業固有の文脈を理解し自律的に動く「AIエージェントが働くための基盤」へと、Databricksは大きな進化を遂げました。
本記事では、ブレインパッドの社員が現地にて肌で感じた熱量とともに、2026年にすべきアップデートや事例まで、データとAIを事業成果につなげるための最前線の知見を総まとめしてお届けします。



「Data + AI Summit」は、Databricks社が主催するデータとAIに関する世界最大規模のカンファレンスです。2026年は、6月15日から18日までの4日間にわたり、米国サンフランシスコにて開催されました。
本イベントには、世界中からデータエンジニアやデータサイエンティストといった技術者はもちろん、企業の経営層やDX(デジタルトランスフォーメーション)を牽引するビジネスリーダーが一堂に集結します。会場では、データとAIに関わる最新技術の発表や、先進的なビジネスユースケースに基づく熱気あふれる議論が連日交わされました。

今年のSummitは過去最大規模となり、現地参加は174か国から31,309名となりました。オンライン視聴も含めると計10万人以上が参加する巨大なテクノロジーの祭典となっています。特に注目すべきは、日本国内での注目度の高さです。今年は日本からも500名以上が現地へ足を運んでいました。
現地でさまざまな方と直接お話しさせていただきましたが、体感としては「今年が初参加」という方が6割以上を占めていた印象です。このことからも、日本中でデータやAIのビジネス活用に対する期待感が、かつてないほど高まっていることを肌で感じました。
私たちブレインパッドは、「データ活用の促進を通じて持続可能な未来をつくる」というパーパスを掲げています。
進化し続けるデータとAIを、いかにして具体的な「ビジネス成果」に結びつけるのか。その最前線の知見と熱気を体感し、ビジネス実装を拡大するためにも、ブレインパッドとしても今年初めて本Summitに参加いたしました。
本記事では、現地で体感した熱量そのままに、Summit全体を通じて見えてきた最新技術の大きな潮流や、具体的な事例発表の内容について、次章から詳しく紐解いていきます。
6月16日、17日の2日間、計6時間にわたって開催されたKeynote(基調講演)では、共同創業者兼CEOのAli Ghodsi氏をはじめとする各責任者が登壇し、これからのDatabricksの全体像が語られました。

今年のDatabricksを読み解く上で欠かせないのが、プラットフォームのコンセプトが従来の「Data Intelligence Platform」から「Databricks DATA+AI Platform」へと刷新された点です。
2026年のKeynoteでは、Open Infrastructure、Agentic Data、Unified Governance、Agentic Work、Agentic Development、Agentic Appsという構成が示され、データ基盤、ガバナンス、エージェント開発、業務アプリケーションまでを一体として扱う方向性が打ち出されました。
この変化はプラットフォームの構造だけでなく、メッセージングにも明確に表れています。2025年までは「AI / BI」というキーワードが並列に語られることもありましたが、今年はAIエージェントを中心とした見せ方がより強くなっています。AI活用が広がった後に生じる文脈理解、統制、コスト、選択肢の管理といった課題に対して、Databricksがプラットフォーム全体で対応しようとしていることが印象的なSummitでした。
Keynote全体を通じて強調されていたのが、「Context」「Control」「Cost」「Choice」という4つのCです。

中でも、新しく追加された「Context」が特に重要な役割を担っています。
「Choice」と「Control」という強固な土台があるからこそ、「Context」が真の価値を発揮するというプラットフォームの基本思想が示されました。
この4つのCを軸に、「Databricks DATA+AI Platform」の全体像は大きく以下の5つの領域で示されました。それぞれの最新アップデートについて、図の下から順に見ていきます。

Databricksの基本思想である「Choice(選択の自由)」の中核を担うのが、オープンなインフラストラクチャです。
今年のKeynoteには、Apache IcebergのクリエイターであるRyan Blue氏も登壇しました。Iceberg v3によってデータフォーマットの統合が進み、今後は「Delta用」「Iceberg用」とデータを複製・管理する必要がなくなり、単一のマスターデータセットで統合管理できるようになる予定であることが明かされました。
AIエージェント時代に求められる圧倒的なスケールと同時実行性に応えるため、データスタックがリアルタイム基盤へと劇的にアップグレードされました。
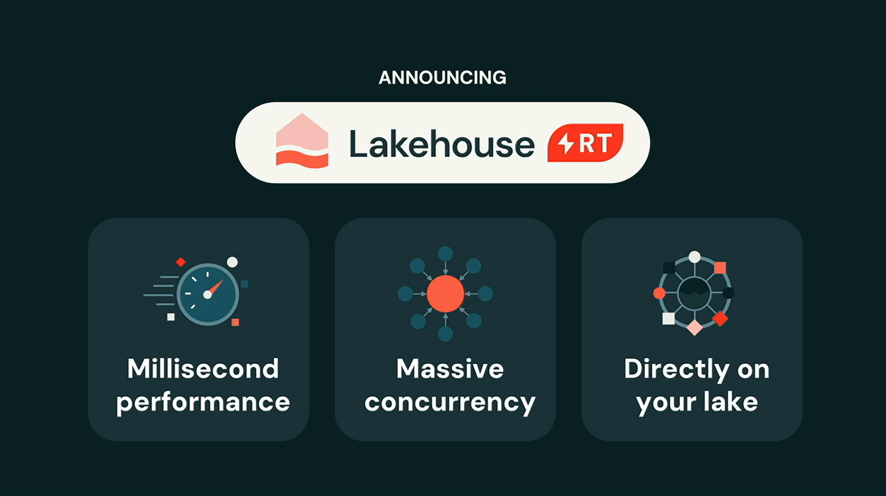
データやAIのガバナンス、そしてコスト管理(Control & Cost)を担う領域です。
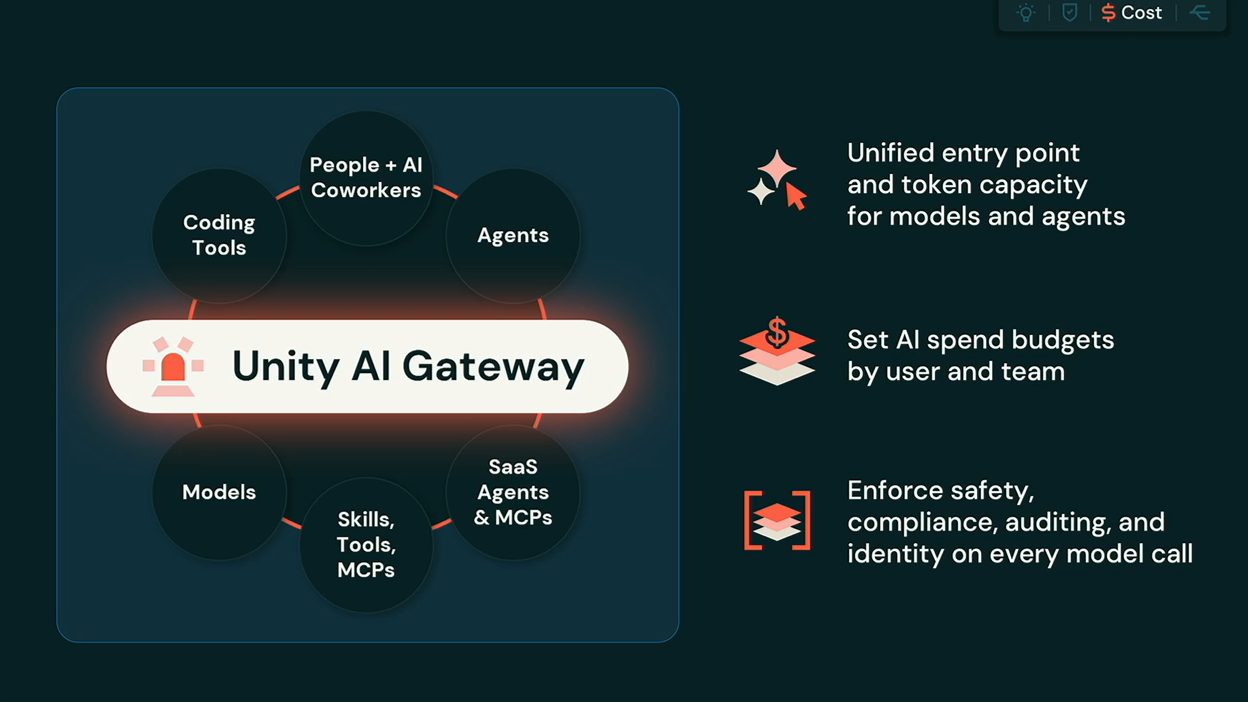
今年の目玉とも言える、業務自動化とAI開発を支える非常に重要な領域です。関連機能は「Genie」ブランドに統一され、CEOのAli氏が掲げる「データスマートなAI Coworker」の実現を目指します。

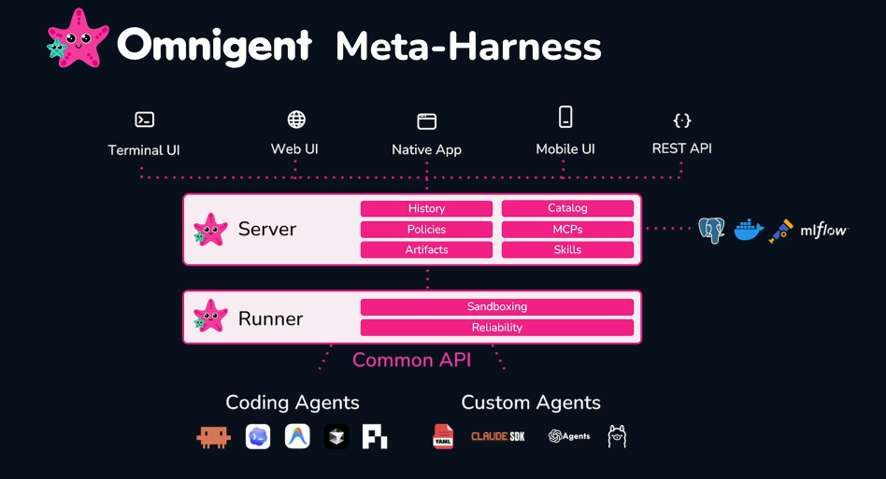
今回のKeynoteで、CDP(顧客データ基盤)やSIEM(セキュリティ情報イベント管理)が、DatabricksのLakehouse上でネイティブに稼働するようになりました。

今回のKeynoteで示された通り、Databricksは「Choice」「Control」「Cost」という強固な土台の上に「Context」を乗せることで、企業に圧倒的な競争優位をもたらす唯一無二のプラットフォームへと進化しました。
しかし一方で、どれほど強力な機能が提供されても、組織内でデータやAI活用が分断(サイロ化)されていては、「Context」の質を高める効果は限定的になってしまいます。
組織横断でデータやエージェントをシームレスに活用し、サイロ化を解消すること。これは単なるシステム上の課題ではなく、企業の経営層が真っ先に向き合うべき重要な「経営課題」であると、今回のSummitを通じて強く感じさせられました。
2章で見た通り、2025年のDAISではLakehouseとUnity Catalogを中心に、データとAIの利用者を広げる方向性が示されていました。これに対して2026年は、その土台を維持しながらAIエージェントが企業内の文脈を理解し、統制を受け、複数の実行環境で継続的に動作するための基盤整備へと重心が移っています。
この変化をデータサイエンスの視点で見ると、単に新しいエージェント機能が増えたという話ではなく、データサイエンティストや機械学習エンジニアが重視すべき設計対象と役割の比重が変わり始めていると捉えられます。
従来の機械学習プロジェクトでは、価値の中心はモデルそのものであり、データ収集、特徴量設計、モデル開発、評価を通じてより高い精度を実現することが主な関心事でした。生成AIの登場後は、基盤モデルを前提に、プロンプト設計やRAG、エージェント設計によって業務価値を引き出すことが重要になりました。
今回のDAISで印象的だったのは、AIエージェントを作ることそのものよりも、企業システムの中でどう運用し、継続的な価値につなげるかへ議論の重心が移っていた点です。
2章で紹介したContext・Control・Cost・Choiceという4つの観点は、Databricks DATA+AI Platform全体を貫く設計思想です。AIエージェントを企業で運用するという観点から見ると、その設計思想を象徴していたのが、Genie Ontology、Unity AI Gateway、Omnigentでした。
それぞれ企業固有の文脈、ガバナンス、複数のエージェント実行環境を統合・制御する基盤という異なる役割を担っています。個々の機能は異なりますが、共通しているのは、企業環境でAIエージェントを運用するうえで必要になる周辺基盤を整備している点です。
これらの領域自体は新しいものではありません。企業知識の管理、アクセス制御、コスト管理、実行基盤、運用監視はいずれも以前から存在していました。しかし2026年のDAISでは、それらを個別の技術としてではなく、AIエージェントを企業へ組み込むための一つの設計思想として整理して示しています。ここに今年のDatabricksの大きな変化を感じました。
この変化を踏まえると、データサイエンティストや機械学習エンジニアが重視すべき設計対象にも変化が生じます。従来からMLOpsやデータガバナンスなど、モデル以外の領域も重要でした。
しかし今後は、それらに加えて、企業知識をどのようなコンテキストとして設計するのか、エージェントにどの権限を与えるのか、どのモデルや実行環境を選択するのか、どの程度のコストで運用できるのかといった要素が、企業でAIエージェントを活用する仕組み全体の品質を左右する重要な設計要素として、これまで以上に重みを増していくと考えています。
この変化は、従来BIやデータマネジメントの文脈で扱われてきた領域にも影響します。KPI定義、業務用語、アクセス権限、セマンティックレイヤなどは、人がデータを正しく理解・利用するための情報として整備されてきました。
しかしAIエージェントが業務判断やアクションに関与するようになると、それらは人間向けの補助情報にとどまりません。エージェントが企業固有の知識や業務文脈を理解し、適切な判断やアクションを行うためのコンテキストとしての意味合いが強くなります。言い換えれば、「人のためのデータ設計」が、そのまま「AIのためのコンテキスト設計」としての意味を持ち始めています。
こうした設計対象の変化に加え、データサイエンティストや機械学習エンジニアが担う従来の運用面での役割にも一部変化が見られます。例えば今回発表されたGenie ZeroOpsは、パイプラインやMLモデルを自律的に監視し、原因分析や修正提案、場合によっては自動修正まで行うバックグラウンドエージェントです。もちろん、これによってMLOpsが不要になるわけではありません。
しかし、監視や障害調査といった運用業務の一部がエージェントへ委ねられることで、人間は個々の運用作業そのものではなく、評価基準や運用方針、ガバナンスなど、より上流の設計へ注力する比重が高まっていくと考えています。
2025年から2026年にかけて見えた変化は、個々の機能追加以上に、その背後にある設計思想の変化でした。Databricksの発表からは、AI活用における設計の重心が、「モデルやエージェントをどう作るか」から、「企業システムの中でAIをどう運用し、継続的な価値につなげるか」へ移り始めていることが読み取れます。この変化は、データサイエンティストや機械学習エンジニアにとっても、今後向き合うべき重要な視点の一つになると考えています。
衛生陶器大手のKohler社がサプライチェーン業務における判断構造をマルチエージェントとともに変えてきており、日本企業においても、非常に参考になると考えます。
ブレインパッドとしても、本事例と同様の思想から、需給エージェントオファリングをリリースしております。

サプライチェーン・AIエージェントの本丸は、再判断力を求めていくことだと捉えて、身に染みております。背景として、企業のサプライチェーン業務はこれまで現場の調整力やベテランの経験に支えられ、第3次AIブーム以降、需要予測、発注自動化などの仕組みを導入し、部門間の擦り合わせとともに業務適用してきました。
しかしながら、今後は人手不足、物流混乱、原材料の高騰だけでなく、需要変動の速さ、地政学リスクなどに対して、吐き出される予測数値も含めて、人がなんとか調整する限界があります。
そのときに、どれだけ早く、正しく、全体最適で判断できるか。今後必要となるのは、需給判断を属人的な職人芸から、エージェントとともにアジリティのある需給判断に変えることだと受け取ることができる良い事例でした。
スポーツブランド大手のアディダス社がデータ分析の現場が抱える課題を「仮想アナリスト」によっていかに解決し事業成果に直結させるかという、非常に実践的な「青写真(Blueprint)」が示されました。
エンタープライズでAIを実装する上での重要なポイントを紐解きます。
多くの企業がデータ基盤を構築し、見栄えの良いダッシュボードによるセルフサービス化を進めてきました。しかし、ビジネスの現場から生まれるのは「なぜ先週のコンバージョン率が下がったのか?」といった、より深く複雑な「Why」の問いです。
ビジネスユーザーはダッシュボードを見た後にデータアナリストに分析を依頼してしまい、アナリストの貴重なリソースがコンテキストに依存した定型的なタスクに奪われてしまうという問題が発生していました。
この問題を解決するためにアディダス社が構築したのが、インテリジェントな仮想アナリストである「DIVA (Data Intelligent Virtual Analyst)」です。DIVAは単なる事実の報告だけでなく、多角的にデータを分析し、ビジネスユーザーの「なぜ」に答えることを目的としています。
DIVAの裏側では、LLMを安全かつ正確に機能させるための堅牢なアーキテクチャが構築されています。単にLLMをデータに繋ぐのではなく、以下の6つの層(レイヤー)を連携させているのが特徴です。

アディダス社は、AIの自律性を高める前にユーザーからの「信頼(Trust)」を獲得する必要があるとし、段階的なアプローチを採用しています。

一般的なAIチャットボットが「質問 → LLM → 回答」という単純なフローを辿るのに対し、エンタープライズレベルのDIVAはより複雑で厳格なステップを踏みます。
まず、ユーザーがアクセス権限を持つデータのみに絞り込む「認証(Auth)」を行います。その後、直接LLMに質問を投げるのではなく、過去の分析履歴やセマンティック情報を集約して「コンテキスト(文脈)」を構築します。
続いて質問を小さな分析タスクに分解し、並列で調査を実行。生成された回答がビジネスルールと整合しているか検証を行った上で、最終的な回答とともに「その背後にあるSQLや参照元などのロジック」を提示します。
セッションの最後には、AI実装のポイントが語られました。
1点目のコンテキスト(Context)の重要性は、今回のSummitでのKeynoteでも強調されているポイントです。組織のコンテキストをいかに高い質で構築することができるかがより重要になってくると考えられます。
また、AIが使える状態にしておくデータ整備、ユーザーに合わせたアクセス権限はいずれもDatabricksの強みを発揮して実現ができます。
これらの知見は、今後データとAIを活用して事業成果の創出を目指す日本企業にとっても、極めて示唆に富む実践的な事例と言えます。
今回のDAIS 2026を通じて強く感じたのは、データ・AIの活用が「業務への組み込み」へ着実に移り始めているということです。
AIエージェントが企業の業務判断やアクションに関わるようになると、単にデータを集めるだけでは不十分です。売上、在庫、顧客、案件、LTVといった言葉が、その企業の中で何を意味するのか。そしてその背景には何があり、どのデータを公式なものとして扱うのか。どのKPI定義を優先するのか。こうしたContextが整っていなければ、事業判断や業務自動化に使える状態にはなりません。
Databricksの怒涛の発表は、現在考えられるData&AI領域の少し先の市場・技術トレンドを全部乗せしたような形で且つ、強くて速い開発力を非常に感じました。
今後、企業に求められるのは、AIを前提としたBPR(ビジネスプロセス・リエンジニアリング)が重要になってくると確信しております。
データとAIを事業成果につなげる本質は、AIを導入することそのものではありません。企業固有の業務文脈をAIが正しく理解し、人とAIが協働して、より良い判断を積み重ねられる状態を作ることにあります。私たちも、データとAIを単なる技術導入で終わらせず、企業の業務や意思決定の変化につなげるための取り組みを、より一層深めていきたいと考えています。
最後は今回のDAISでの戦利品を掲載して、締めさせていただきます!

あなたにオススメの記事

2023.12.01
生成AI(ジェネレーティブAI)とは?ChatGPTとの違いや仕組み・種類・活用事例

2023.09.21
DX(デジタルトランスフォーメーション)とは?今さら聞けない意味・定義を分かりやすく解説【2024年最新】

2023.11.24
【現役社員が解説】データサイエンティストとは?仕事内容やAI・DX時代に必要なスキル

2023.09.08
DX事例26選:6つの業界別に紹介~有名企業はどんなDXをやっている?~【2024年最新版】

2023.08.23
LLM(大規模言語モデル)とは?生成AIとの違いや活用事例・課題

2024.03.22
生成AIの評価指標・ベンチマークとそれらに関連する問題点や限界を解説
















