



メルマガ登録
-
テーマから探す
-
技術から探す
-
業界・事例から探す
-
関連トレンドから探す
テーマから探す
技術から探す
業界・事例から探す
関連トレンドから探す

弊社では機械学習・分析に関わる案件が多く、その過程で大量データを扱うことも少なくありません。
特に非常に大きいデータを扱う場合、HadoopやSpark等の分散処理基盤を利用してデータを加工したり、最終的にはデータウェアハウス(以後、DWH)を構築・登録を行い、SQLを利用してデータの内容を確認したりします。


ところで、みなさんはDWHと聞いて、何を思い浮かべるでしょうか? おそらく、以下のようなイメージではないでしょうか?
確かにクラウドが登場する前、いわゆるオンプレミス主流の時代のDWHは上記のイメージでかつ、安定した運用を行うためには専門的な知識を保有した技術者が必要でした。
昨今、GCP、AWS、Azure等のクラウドにもDWHのサービスが用意されており、機械学習・分析の作業にもよく利用されるようになってきております。
例えば、Amazon RedShift、Azure Synapse、 BigQueryなどが代表的なもので、単独のDWHサービスではSnowflakeが有名ではないでしょうか。
これらのDWHサービスは、昔とは違い
と、多少専門的な知識が必要な場面はありますが、昔に比べれば非常に容易に導入することができるようになってきています。
これに加え、大量データを素早く処理するために分散処理等の様々な工夫が行われています。 ここまでの機能を保持しながら、DWHをデータの保存の目的のみに利用するだけでは、非常にもったいなくありませんか?というのが今回のお話です。
ビッグデータという言葉がさかんに言われる前のシステム開発では、ファイルを直接読み、メモリ上でデータを集計したり、OracleやMysqlのようなRDBMS、DWHにデータを取り込みデータを集計したりしていました。
データ量が増えた場合は、処理を行うサーバのスペックをあげたり、プログラムの工夫を行ったりすること速度改善を行ってきました。
ただ、これらのソフトウェアは1台のサーバ上のみで動くように設計されており、ビッグデータ時代になり、取り扱うデータ量が大幅に増加していくにつれて、どんなに高性能なサーバーを用意したとしても1台では処理に限界があり、想定時間内に処理を終えることができなくなりました。
そこで現れたのがHadoop、Spark等に代表される分散処理基盤になります。これらの分散処理基盤は複数のサーバに分けて処理を行うことをあらかじめ想定しており、大量データを複数のサーバーに分散して処理をすることで、この問題を克服してきました。
一見救いの手に見える分散処理基盤ですが、大量データを効率よく、かつ安定して処理を実施させるためには、処理効率やメモリ管理を意識した高度なプログラミングが必要で、分散処理基盤環境自体チューニングが必要不可欠となります。また、これに対応するには専門的な知識を保有したエンジニアが必要になってきます。
昨今、GCP、AWS、Azureに代表されるクラウドにも、この分散基盤構築を比較的容易に構築するサービスも出てきており、構築作業自体は比較的容易になりましたが、引き続き高度なプログラミングが必要となり、分散処理基盤環境自体チューニングが不要になったわけではありません。したがって運用するには、引き続き専門的なエンジニアが必要なことは変わりなく、決して容易なものになったとは言えません。ですので、まだまだ大量データを扱った処理を安定して運用することは容易ではないと考えます。
そこで、クラウドのDWHサービスをを利用することで、専門的なエンジニアも不要で、もっと容易に安定した処理基盤を構築することができるのではないかと考えました。
では、どういう用途が考えられるでしょうか?
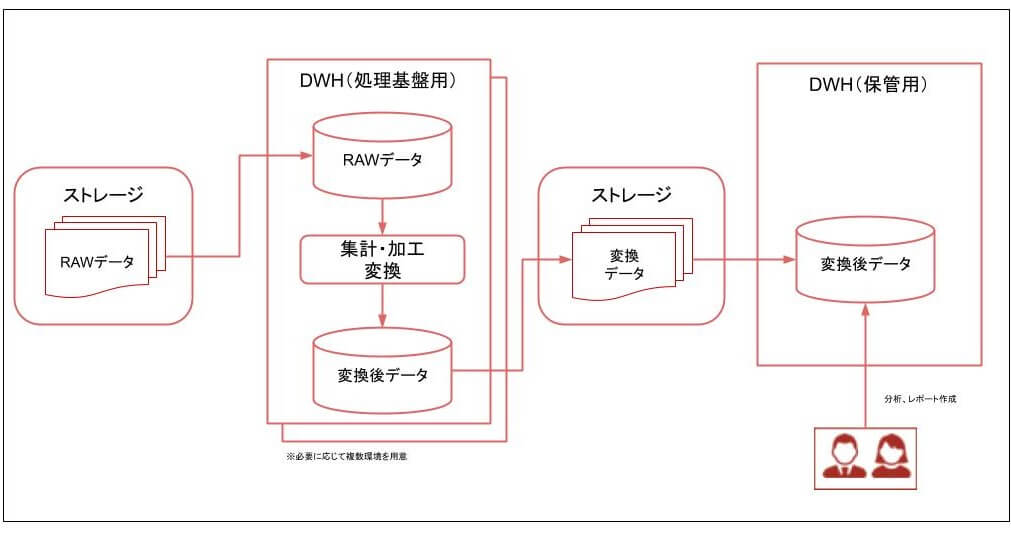
真っ先に思いつくのは前述した「分散処理基盤」としてのDWHサービスの利用です。
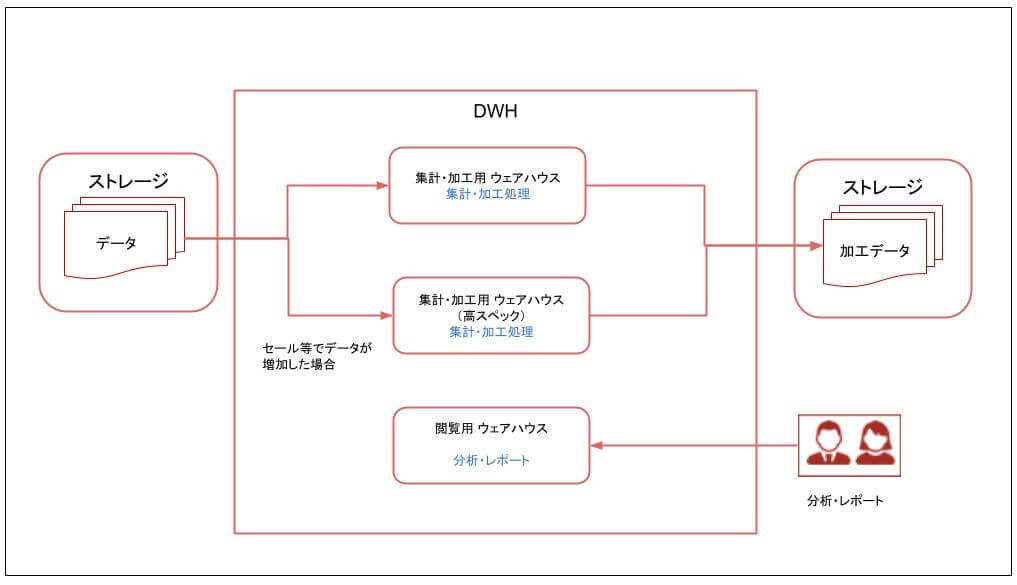
前提として、処理中にDWHからレポートの閲覧が遅くなったという事態に陥らないように、データを保存する目的のDWHとは別に、分散処理基盤専用のDWH環境を構築しておくことをお勧めします。
上記にあげたDWHサービス自体が速度改善を目的とした分散処理を行っていますので、それを利用した大量データ集計や、変換処理を行う基盤として利用するのはいかがでしょうか?
DWHサービスにデータを入れる際に意外と苦労するのが、テーブルに形式に合わせて、データの加工、形式のチェックを行う事です。
まずは細かい加工はせずに出来るだけ受領したファイルのままデータを登録し、あとはSQLを利用して内容の調査や必要なテーブルに加工していくことをおすすめします。
それぞれの作業でDWHサービスの分散処理機能を利用できるため、速度も迅速ですし、やり直しも容易になります。
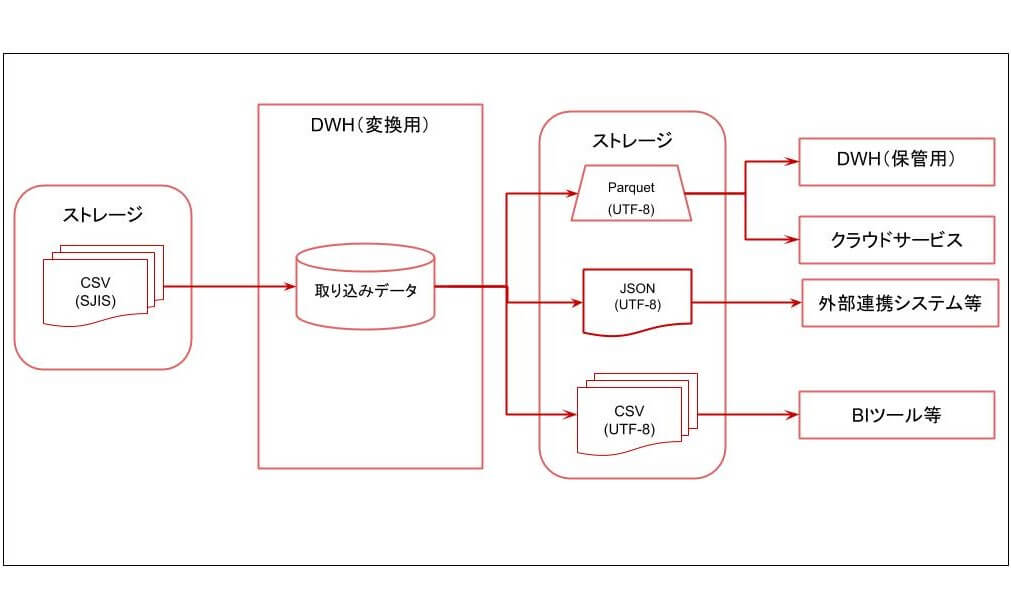
DWHサービスではデータのインポート、エクスポート機能が備わっており、UTF-8やSJIS等の文字コードの指定、CSV、JSON、Parquet等のフォーマットを指定できます。(指定できる文字コードや、フォーマットは各DWHサービスで異なります)
この機能を利用して、インポート時取り込むファイルの文字コード、フォーマットを指定し、エクスポート時に変換したい文字コードおよびフォーマットを指定するだけで、データを変換することができます。
一見、文字コードやフォーマットの変換は、DWHを利用しなくても容易に対応できそうに見えます。確かに数メガ程度の小さいサイズのファイルでかつ、1つのフォーマットに変換するのはDWHを利用しなくても容易に対応可能です。
ただ、複数のフォーマット・文字コード変換が必要になる場合や、ギガバイト・テラバイト級の大容量ファイルを扱う必要がある場合はいかがでしょうか?
この場合、複数のフォーマット変換・文字コード変換を行う処理を作成する必要がありますし、大容量ファイルを処理する基盤の構築も必要となってきます。
ここでDWHを変換サーバの処理基盤として利用することで、DWHに用意されている機能、環境をそのまま利用することで、大量データを簡単にかつ迅速に変換することができるようになるのです。
具体的な用途にも記載していますが、DWHサービスを処理基盤として利用する利点をまとめると、以下の内容が言えるのではないかと思います。
結果、高度なスキルを持ったプログラマーや、インフラエンジニアのアサインや、大規模な環境構築作業についても不要となり、スケジュール・経費の削減に繋がるのではないかと思います。
上記利点に加え、各クラウドにおけるDWHサービスを利用した際の費用削減や柔軟性を向上させるポイントを記載します。
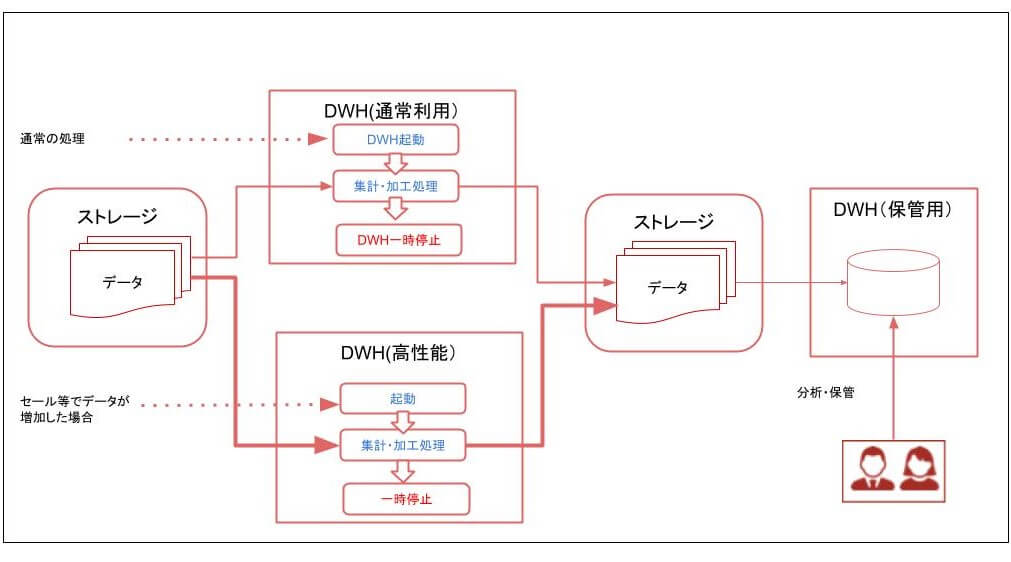
Amazon RedShift やAzure Synapse は、クラスタの起動時間が主な費用発生要因となるDWHサービスです。両サービスとも一時停止時状態では費用が発生しません。(ディスク使用料等は発生しますが非常に安価です)
ですので、DWHを構築後一時停止しておき、利用するときに起動させ、利用終了後また一時停止することで、大幅な費用削減が可能になります。
更に一時テーブルを利用すれば、DWH内にデータが保存されないため、保存ディスク使用量さえも削減することができます(ただし、処理の状態がDWH内に残らないため、問題発生時の調査が難しくなるため注意が必要です)。
また、ECサイトのセール時など、一定期間のみアクセス量が増えるタイミングでは、DWHのスペックを一時的に上げるか、通常利用するDWHと、セール時のみ利用する高スペックなDWHをあらかじめ用意しておき、都度利用するDWHを変更することで、常に特定の時間内に処理を終了できる環境を容易に構築することができます。
BigQueryはGCPが予め用意したクラスタの一部利用するサービスで、費用発生要因はサーバの起動時間ではなく、SQLで検索したデータ量の多さになります。
そもそもクラスタの停止という概念がなく、Amazon RedShift やAzure Synapseと同様の工夫ではなく、SQLを工夫して出来るだけ検索するデータ量を減らす工夫が必要になりますが、具体的な内容については本記事の範疇ではありません。
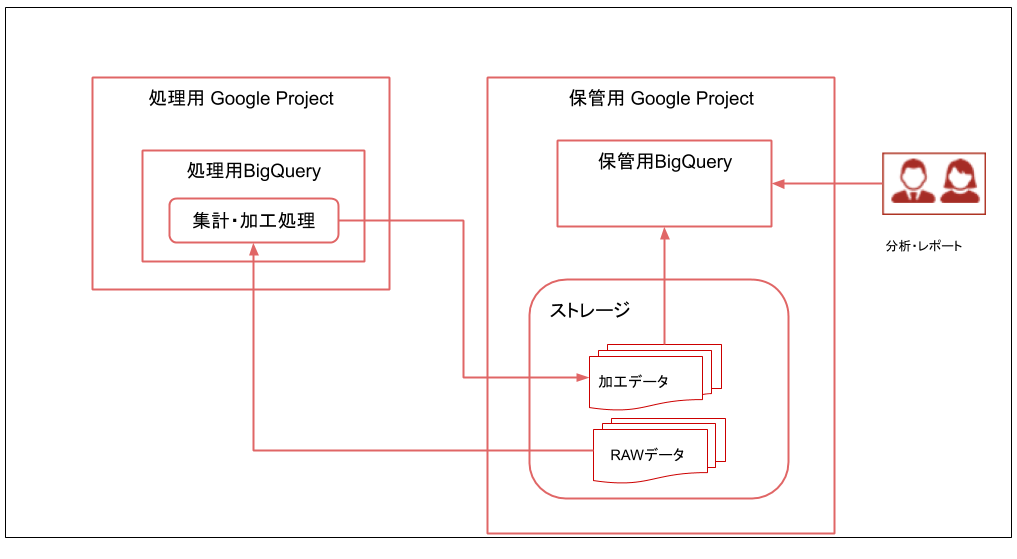
またBigQueryといえども、処理基盤として利用して大量データの集計を行っている間に、分析作業等でデータを読み込み作業をすると性能の劣化が発生することがあります。そのため、お互いの処理の影響を及ぼさないように、構成として処理用のDWHと、データ保存用のDWHに分けることをお勧めします。
ただし、BigQueryはGCPのプロジェクトに対して1つのDWHしか構築できないため、処理用のプロジェクトと、データ保存用のプロジェクトに分ける場合は、別々のプロジェクトに分ける必要があります。
昨今、有名になってきたDWHサービスで、特徴はウェアハウス(処理を行うサーバ)と、データを保存するディスクが分離されているアーキテクチャを持っており、ウェアハウスを分ける事で、
のような場合でも、お互いに干渉せず性能の劣化が発生しません。
弊社でよくある例として、処理に時間がかかるバッチ処理が行われていても、並行して分析官がSQLを利用していても、お互いに影響なく処理を実施できるため、複雑なSQLを実施したが故にバッチ処理の終了に影響を及ぼしてしまったということをなくす事ができます。
上記理由から、データ保存用のDWHと、処理基盤のDWHの処理がお互いに影響しないため、それぞれ別に環境を構築する必要がなくシンプルな構成になります。
また、費用が発生する主な要素はウェアハウスの起動時間になりますが、起動自体も1秒程度で終わりますし、利用しなくなった場合の自動停止機能もあり、不必要な課金が発生しないようになっています。
ウェアハウスも、色々なスペックが容易されており、大量データを処理する場合は高スペックなウェアハウスを利用することで処理時間を短縮することができます。
いかがでしたでしょうか? もちろん、HadoopやSpark等の分散処理基盤上でしかできない細かい処理もありますが、大部分の処理はDWHとSQL、関数を使用して対応できるのではないでしょうか?
DWHによっては、多少チューニングを行う知識が必要なものもありますが、別途処理基盤を構築するよりも簡単ですし、環境構築や、特別なエンジニアを用意する必要性を考えても大きなメリットがあるのではないかと思います。
既存の案件はもちろん、新しい案件を実施する前に、一度是非、ご検討いただければと思います。
DX基盤に関する記事はこちら
・企業DX推進に必要な4つの基盤と橋渡し役の存在
・DXのデータ活用基盤としての3大クラウド-AWS、Azure、GCPの比較
あなたにオススメの記事

2023.12.01
生成AI(ジェネレーティブAI)とは?ChatGPTとの違いや仕組み・種類・活用事例

2023.09.21
DX(デジタルトランスフォーメーション)とは?今さら聞けない意味・定義を分かりやすく解説【2024年最新】

2023.11.24
【現役社員が解説】データサイエンティストとは?仕事内容やAI・DX時代に必要なスキル

2023.09.08
DX事例26選:6つの業界別に紹介~有名企業はどんなDXをやっている?~【2024年最新版】

2023.08.23
LLM(大規模言語モデル)とは?生成AIとの違いや活用事例・課題

2024.03.22
生成AIの評価指標・ベンチマークとそれらに関連する問題点や限界を解説













