



メルマガ登録
-
テーマから探す
-
技術から探す
-
業界・事例から探す
-
関連トレンドから探す
テーマから探す
技術から探す
業界・事例から探す
関連トレンドから探す

私は現在、主にPoC後のシステム化案件を担当しています。
以前、弊社栗原執筆の記事「機械学習プロジェクトを推進するにあたって大切なこと ~DX推進時の「企画・PoC 」フェーズの落とし穴にはまらないために~」で、「企画・PoC(Proof of Concept:概念実証)」フェーズでの注意点を紹介しました。
そこで今回は、PoCで適切な企画ができたという前提のもとで、機械学習プロジェクトのシステム化を効率よく進めるにはどのようなチームが必要かという点について筆者の経験をもとにお話しできればと思います。


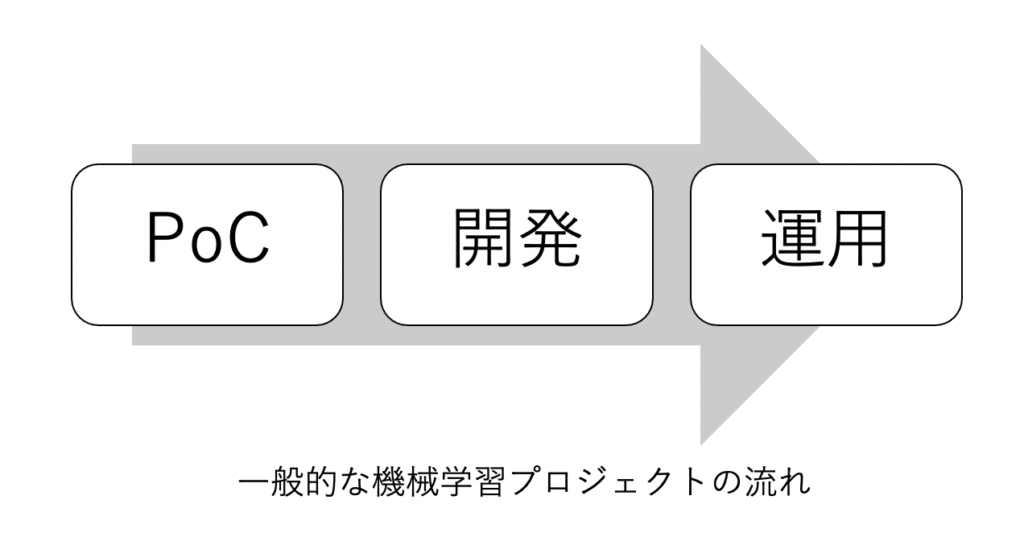
機械学習プロジェクトは一般的に上記の流れで実施されます。
この流れを淀みなく遂行することができれば、機械学習プロジェクトは成功といえます。
ただ、淀みなく遂行するのがなかなか難しいという問題があります。というのも、各プロセスで必要とされる技能が異なってくるためです。
例えば、
といったものが必要になります。結果、それぞれのプロセスをそれが得意な企業や人に別々に依頼するという状況が散見されます。
「得意な企業や人に依頼しているのだから問題ないのでは?」と思われるかもしれませんが、これは誤りと考えています。なぜなら、こと機械学習プロジェクトで開発するシステムでは上記のプロセスが「互いに有機的に」つながり合っているからです。
これは機械学習プロジェクトが上記プロセスを一通りこなすだけで完了するものではなく、下記のようにプロセスの反復でフィードバックを得つつ、少しずつ改善を加えて完成度を高めていくという性質を持っていることによります。
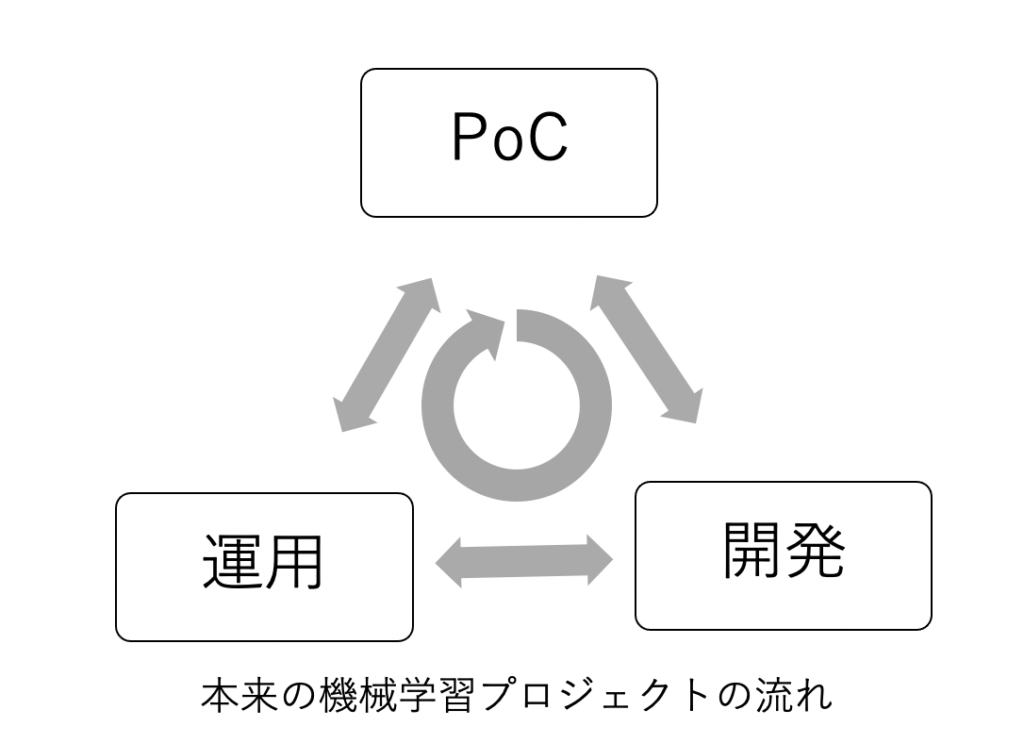
この性質により、各プロセスでの変更が全てのプロセスに影響してしまいます。
そのため、変更が発生した場合、各プロセスを別の企業に依頼すると、プロセス間でコミュニケーションロスによる担当者間での認識のずれが生じます。これが一度のプロセスであれば大きなズレにならないかもしれませんが、反復のプロセスでは小さなズレがさらにズレを生み、雪だるま式にズレが大きくなっていきます。
結果、いつまでも機械学習プロジェクトの成果物が使える状態にならないといったことや、最悪、システム化前にプロジェクトの予算凍結といったことに発展してしまいます。
実際、PoC時に利用できる環境やデータセットと運用/開発時に利用できる環境やデータセットが異なることにより頓挫してしまうプロジェクトや、運用負荷を考慮しないまま行われたプロジェクトで運用負荷が増大し、反復のプロセスを回すことができなくなってしまうプロジェクトを数多く見てきました。
こういったことを起こさないようにするためには、どうすれば良いのでしょうか?
ここからは、筆者の経験をもとに機械学習プロジェクトを進める上で適切なチーム編成について紹介したいと思います。
機械学習プロジェクトで筆者が経験してきたチーム編成には下記の様な編成があります。
ここではそれぞれのチーム編成でのメリット、デメリットを示した上で筆者の考える適切なチーム編成について紹介します。
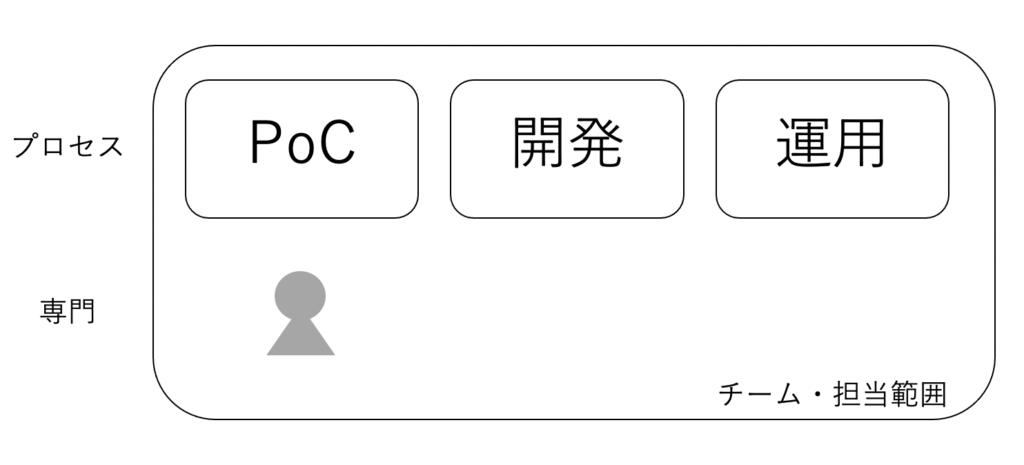
こちらは、筆者が主にPoCを担当していた時に経験したチーム編成です。この編成では、基本的にPoC-開発-運用までを分析官のみで担当していました。
この編成のメリットは、分析官内で知識レベルが揃っているためコミュニケーションロスが少なく、素早くシステム化まで持っていけることです。
一方で下記のような問題が発生していました。
上記のようなデメリットが蓄積し、システムの失敗が多発し、最終的には業務が既存機能のリカバリをするという運用業務ばかりを担当するという結果になってしまいました。分析官が得意な分析〜新機能提案業務ができなくなり、苦手なリカバリばかりを担当するようになってしまったのです。
これは企業にとっても担当者にとっても、なかなかの悪夢といえるでしょう。
このチーム編成は機械学習プロジェクトの初期には魅力的な選択肢ですが、PoC担当者にスーパーエンジニアがいない限り上記のように技術的負債を積み上げることになります。
そのため、可能な限りこのチーム編成(特に分析官1人チーム)は避けるべきだと思われます。
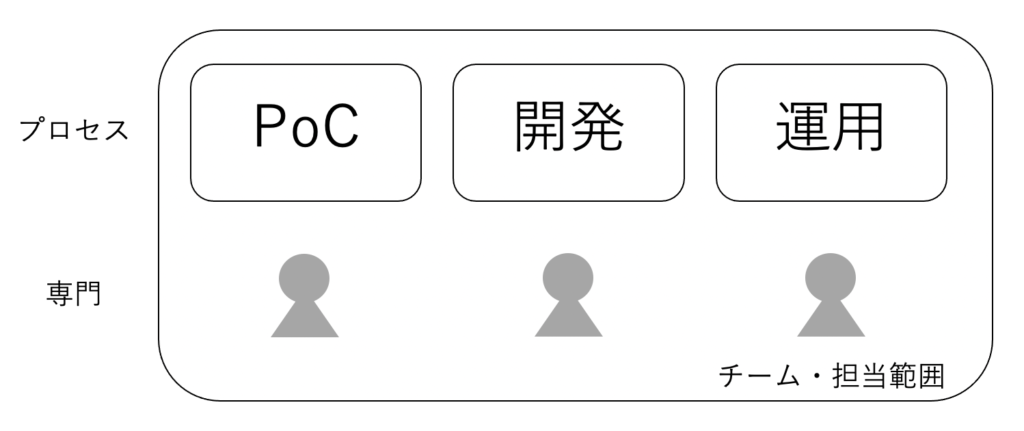
こちらは筆者がPoCと運用業務を兼任していた時に経験していたチーム編成です。
この編成のメリットは、それぞれの専門をもつメンバーが揃っていることにより、システム化を見据えた機械学習プロジェクトを素早く回せることです。
一方で下記のような問題を抱えています。
上記のような問題はありますが、筆者はこの編成において最も良いパフォーマンスを発揮できました。
これは、専門性を持つチームメンバーと素早くコミュニケーションをとることでリカバリ等を素早くこなし、些事に気を取られることなく専門分野に集中することができたためです。また、異なる専門性を持つメンバーとの知識交換により知識レベルが上がった点も大きかったと思います。
初期の立ち上げに少し時間がかかる点、別々の専門性を持つメンバーが必要という問題はありますが、このチーム編成は非常に良い選択肢だと思います。
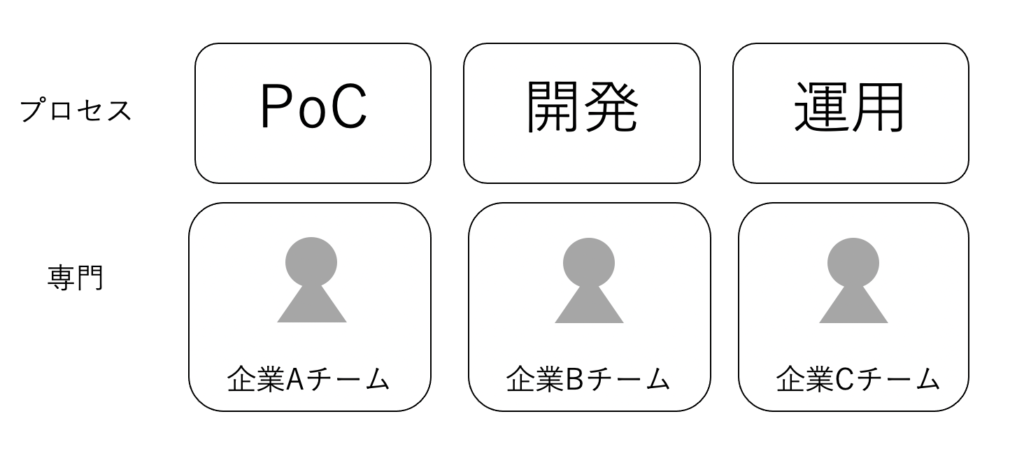
こちらはプロジェクトの開発プロセスのみを担当した際に経験したチーム編成です。PoCと運用のプロセスは別の企業が担当していました。そのため、自分の担当外のプロセスについては最低限の知識しか持っていない状態でした。
規模の大きいプロジェクトでは、こういった形で上記のプロセスを別々の企業が担当するということが多々あります。
この編成のメリットは、その時に必要なプロセスだけに予算をつけることができることによるコスト削減効果が大きいことだと思います。
ただ下記のような問題を抱えてしまいます。
これらの問題は厳格なルール等を定めることで一見避けることができそうですが、発生しそうな問題の全てを事前に把握しておくことは不可能に近いため、多くの場合は後の工程で問題が表れます。
特に上記プロセスの反復である機械学習プロジェクトにおいては、経験上大きな問題に発展する可能性が高いです。
そのため、プロセスごとに別企業が担当するというこのプロセスは基本的にオススメしません。
ただ、自社に専門性を持つ人材を抱えていないということもあると思います。こういった場合には、プロセスごとに別企業へ業務を依頼するのではなく、複数企業から人材を集めてプロジェクト全体を担当するチームを作ることで、こういった問題をある程度回避できます。
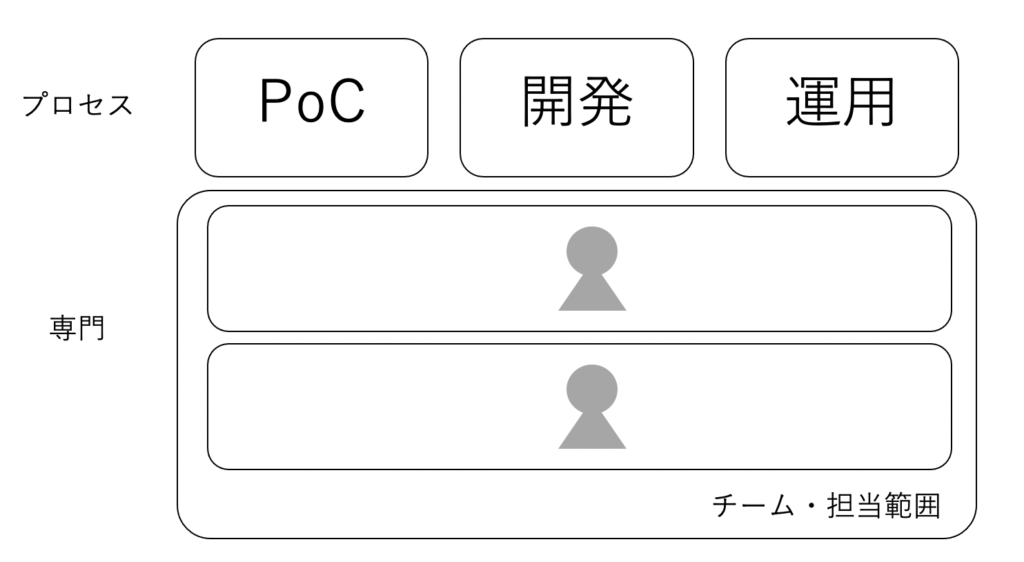
こちらは現在のブレインパッドで一般的なチーム編成です。
専門分野に濃淡はありつつも、全てのプロセスに一定以上、専門分野に通じたメンバーを集めたチームになっています。
この編成のメリットには下記のようなメリットがあります。
問題の1つ1つにリソースを集中することができるため、各プロセスでの課題解決速度が向上する
これらメリットのうち特に「素早くPoC-開発−運用プロセスのサイクルの高速化」は日々めまぐるしく変化するビジネス環境に適応し、DXの「データの活用を通じてビジネスを変革する」という目的を実現するために重要になってきます。当社ではこの実現に向けてこの編成を採用しました。
ただ、下記のような問題を抱えています。
どちらの問題も人材の少なさに起因するものです。企業の内外を問わず、全プロセスに一定以上の専門分野に通じたMLエンジニア、データサイエンティストを多く抱えているのであれば、ワンチーム体制でこの編成にするのがベストだと思います。

以上が、ここまでご説明した4つのチーム編成を簡単にまとめたものです。
今回は、筆者の経験をもとに機械学習プロジェクトを成功させるためにはどのようなチーム編成が望ましいかという点についてお話しました。どの編成にも、メリット・デメリットはあるため、この編成にすれば必ず成功するというものではありません。ただ、チーム編成は確実にプロジェクトの成否に関わる一要因ですので、プロジェクト立ち上げ時に是非ご一考いただければと思います。
あなたにオススメの記事

2023.12.01
生成AI(ジェネレーティブAI)とは?ChatGPTとの違いや仕組み・種類・活用事例

2023.09.21
DX(デジタルトランスフォーメーション)とは?今さら聞けない意味・定義を分かりやすく解説【2024年最新】

2023.11.24
【現役社員が解説】データサイエンティストとは?仕事内容やAI・DX時代に必要なスキル

2023.09.08
DX事例26選:6つの業界別に紹介~有名企業はどんなDXをやっている?~【2024年最新版】

2023.08.23
LLM(大規模言語モデル)とは?生成AIとの違いや活用事例・課題

2024.03.22
生成AIの評価指標・ベンチマークとそれらに関連する問題点や限界を解説













