



メルマガ登録
-
テーマから探す
-
技術から探す
-
業界・事例から探す
-
関連トレンドから探す
テーマから探す
技術から探す
業界・事例から探す
関連トレンドから探す

機械学習とは、コンピュータがデータからパターンやルールを自動的に学び、予測や判断を行う技術です。AI(人工知能)を実現するための中核技術のひとつであり、画像認識・需要予測・レコメンドなど、私たちが日常的に利用する多くのサービスを支えています。
あらかじめ人間がすべての手順を書き下すのではなく、データから学習してモデルを構築する点に特徴があり、現在ではディープラーニングやアルゴリズムの進化を背景に、製造・小売・金融など幅広い業界で活用が広がっています。
本記事では、機械学習の仕組みやAI・ディープラーニングとの違い、代表的な手法、活用事例、構築の流れまでを、初心者の方にもわかりやすく整理して解説します。
機械学習はAIを実現するための代表的な技術の一つです。人間が細かなルールを設定するのではなく、データからパターンや規則性を学習し、予測や判断を行う点が特徴です。
従来のプログラムでは、判断のルールを人間が一つひとつ書き下す必要がありました。しかし現実世界の事象は複雑で、すべてのルールを人間が記述するのは困難です。
機械学習では、大量のデータから規則性や特徴を抽出し、判断に利用できるモデルを構築します。この「データから学習する」という性質こそが従来型のAIとの大きな違いであり、詳細は後の章で改めて整理します。
機械学習については、以下の記事でも分かりやすく説明していますのでご参照ください。
【関連記事】
入社1年目が教わる「はじめての人工知能」第5回:人工知能(AI)を支える「機械学習」の全体像
機械学習は、過去の経験や事象から得られたデータをもとに、機械(コンピュータ)にそこに存在するパターンやルールを自動的に見つけさせる手法です。ここでいうパターンやルールとは、たとえば「過去に商品Aを購入した人は、その後に商品Bを購入しやすい」「この種の画像を『犬』として認識する」といった規則性を指します。
大量のデータをもとに、人間では処理が難しい規模の分析や予測を効率的に行えるようにすることが、機械学習を活用する目的です。
機械学習を理解するうえで欠かせないのが、「アルゴリズム」と「モデル」という2つの概念です。アルゴリズムとは、データをどのように処理し学習させるかを定めた「手順」や「ルール」のことです。
そして、このアルゴリズムにデータを与えて学習させた結果として得られる、入力と出力の関係を表現したものが「モデル」です。機械学習では、適切なアルゴリズムを選び、質の高いデータで学習させることで、精度の高いモデルを構築します。
AIという大きな枠組みの中で、機械学習はこのモデルを通じて「データから学ぶ知能」を実現する役割を担っています。
機械学習によって実現できることは多岐にわたりますが、代表的なものとして「予測」「分類」「異常検知」「推薦(レコメンド)」「自然言語処理」が挙げられます。たとえば予測では将来の売上や需要を見通し、分類では画像やメールを自動でカテゴリ分けし、異常検知では製造ラインの不良品や不正取引を見つけ出します。
推薦は、ユーザーの好みに合った商品やコンテンツを提示する仕組みで、ECサイトや動画配信サービスで広く使われています。予測・分類・異常検知・レコメンド・自然言語処理は、人間が行うと時間のかかる判断や処理を、機械学習によって効率化できる代表的な活用領域です。
これらはいずれも、人間が行うと時間のかかる判断や処理を、機械学習によって高速かつ大規模に自動化したものです。それぞれの具体的な活用事例については、後の章で詳しく紹介します。
機械学習という考え方自体は古くから存在しますが、近年これほど注目を集めている背景には、大きく3つの要因があります。
1つ目は、インターネットやIoT、スマートフォンの普及による「データ量の爆発的な増加」です。学習の材料となるデータが豊富に得られるようになったことで、モデルの精度を高めやすくなりました。
2つ目は、GPUやクラウドの発展による「計算性能の向上とコスト低下」です。かつては膨大な計算資源を必要とした学習が、現実的なコストで実行できるようになりました。
そして3つ目が、ChatGPTに代表される「生成AIの普及」です。生成AIの登場により、AIやその基盤である機械学習への社会的な関心が一気に高まりました。この3つの要因が重なり、機械学習は今やDX(デジタルトランスフォーメーション)や業務自動化を支える基盤技術として、企業の競争力を左右する存在になっています。
機械学習は、データから特徴を学習し、その結果をもとに予測や分類を行う仕組みです。学習データを使ってモデルを構築し、新しいデータに対して推論を行うことで、業務自動化や高度な分析を実現します。
この章では、機械学習が実際にどのような流れで動作しているのかを順を追って解説します。
機械学習の仕組みを理解するには、「学習データ」「特徴量」「モデル」という3つの要素の関係を押さえることが重要です。学習データとは、モデルに学ばせるための材料となるデータで、画像・テキスト・センサー値・購買履歴などさまざまな形式があります。
特徴量とは、学習データから抽出・加工した、予測や判断の手がかりとなる情報のことです。たとえば需要予測であれば「曜日」「天候」「過去の販売数」などが、画像認識であれば「輪郭」「色合い」「形状」などが特徴量にあたります。
機械学習では、このような特徴量をもとにデータの傾向や規則性を学習します。そして、学習によって得られた入力データと予測結果の関係性を表現したものがモデルです。つまり、学習データから特徴量を抽出し、アルゴリズムによってモデルを構築する流れが、機械学習の基本的な仕組みとなります。
機械学習の処理は、大きく「学習フェーズ」と「推論フェーズ」の2つに分けられます。
学習フェーズでは、学習データと正解の対応関係をもとに、モデル内部のパラメータを少しずつ更新しながら、誤差が小さくなるように調整していきます。学習が進むほどモデルはデータの傾向を捉え、精度の高い予測ができるようになります。
一方の推論フェーズでは、学習を終えたモデルに、それまで見たことのない新しいデータを入力し、予測や分類の結果を得ます。たとえば学習済みの需要予測モデルに来週の気象予報を入力すれば、来週の売上見込みを算出できます。学習で得た知見を未知のデータに応用できるからこそ、機械学習は予測や自動化の手段として価値を発揮します。
実務では、まず学習フェーズで十分な精度のモデルを作り、その後、本番環境で推論フェーズを継続的に運用していくのが一般的な流れです。
学習したモデルが実際に役立つかどうかを判断するには、精度の評価が欠かせません。評価には、学習に使っていない「テストデータ」や「検証データ」を用います。学習に使ったデータだけで評価すると、モデルが本当に汎用的な性能を持つのかを正しく測れないためです。
ここで注意すべきなのが「過学習(オーバーフィッティング)」です。
過学習とは、モデルが学習データに過剰に適合してしまい、学習データに対しては高い精度を示すのに、新しいデータに対してはうまく予測できない状態を指します。たとえ学習データでの精度が99%であっても、過学習が起きていれば実用には耐えません。
こうした事態を防ぐため、テストデータでの評価を通じてモデルの汎化性能を確認し、必要に応じて特徴量やパラメータを調整します。精度評価は、機械学習を「使えるモデル」に仕上げるための重要な工程です。
AIは人間の知的活動を再現する技術全体を指し、機械学習はその中の一分野です。ディープラーニングはさらに機械学習の一種であり、多層のニューラルネットワークを用いる点に特徴があります。この章では、「AI > 機械学習 > ディープラーニング」という包含関係を整理しながら、関連する用語との違いを順に解説します。
補足として、機械学習の一種であるディープラーニングが活用されたAIとして「生成AI」があります。生成AIの代表的なサービスとしてChatGPTがあります。生成AIや大規模言語モデル(LLM)の多くは、ディープラーニング技術を基盤として発展しています。
【関連記事】
生成AI(ジェネレーティブAI)とは?仕組みやChatGPTとの関連性を解説
ChatGPTとは?使い方・始め方・仕組み・最新の活用事例を一挙ご紹介!
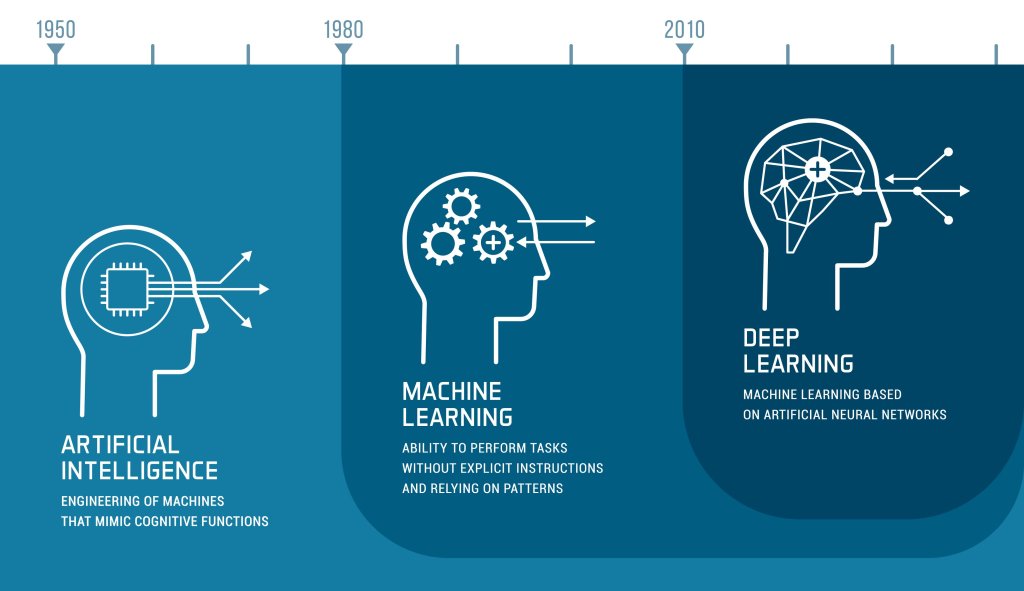
DXの一手段がAIであり、AIを実現する技術のひとつが機械学習、さらに機械学習の一手法がディープラーニングという関係
AIやディープラーニング、DXについては以下の記事もご参照ください。
【関連記事】
入社1年目が教わる「はじめての人工知能」第1回:人工知能(AI)とはなにか
入社1年目が教わる「はじめての人工知能」第5回:人工知能(AI)を支える「機械学習」の全体像
DX(デジタルトランスフォーメーション)とは?「DX=IT活用」ではない。正しく理解したいDXの意義と推進のポイント
AI(人工知能)の定義は研究者の間でも完全には確定していませんが、おおむね「人間の知能・知性を代替する機械の総称」と理解されています。
AIは非常に広い概念であり、機械学習はそのAIを実現するための要素技術のひとつにすぎません。両者の関係を整理すると、AIは「人間のような知的処理を行う」という目的に近い概念であり、機械学習は「データから学習する」という、その目的を実現するための代表的な手段、と位置づけられます。
AIの中には、機械学習を使わずにルールベースで動作するものもありますが、近年「AI」と呼ばれる技術の多くは、機械学習を基盤としています。つまり、機械学習はAIという大きな枠組みを支える中核技術といえます。
ディープラーニング(深層学習)は、機械学習の手法のひとつです。人間の神経回路を模した情報処理モデルを「ニューラルネットワーク」と呼び、ディープラーニングはこのニューラルネットワークの層を幾層にも深く重ねたものを指します。
従来の機械学習では、どの特徴量に注目すべきかを人間が設計する必要がありました。一方ディープラーニングは、多層構造のニューラルネットワークによって、データから特徴表現を自動的に学習できる点が特徴です。
この特徴によって、画像・音声・自然言語といった複雑なデータでも高い精度を実現できるようになりました。ChatGPTに代表される生成AIや大規模言語モデル(LLM)も、このディープラーニングの延長線上にある技術です。
機械学習とよく似た技術として「統計学」が挙げられますが、両者は目的の置き方に違いがあります。統計学は、データの背後にある構造や関係性を「説明」することに重きを置きます。なぜそうなるのか、どの要因が結果にどう影響しているのかを明らかにすることが主な関心事です。
一方、機械学習は「予測」の精度を高めることに重きを置きます。なぜそうなるのかという説明よりも、未知のデータに対していかに正確に予測・分類できるかが重視されます。
もちろん両者は対立するものではなく、統計学の理論は機械学習の土台にもなっており、実務では「説明」と「予測」の両面を組み合わせて使うことが少なくありません。目的に応じて、説明重視なら統計学的アプローチを、予測重視なら機械学習的アプローチを選ぶという理解が役立ちます。
機械学習は、学習方法の違いによって「教師あり学習」「教師なし学習」「強化学習」の3種類に大きく分類されます。それぞれ用途や得意とする課題が異なり、解決したい問題に応じて使い分けられます。この章では、それぞれの仕組みと特徴を順に見ていきます。
【関連記事】
入社1年目が教わる「はじめての人工知能」第6回:人工知能(AI)を支える「機械学習」の手法
教師あり学習とは、データと「正解(ラベル)」をセットでコンピュータに与え、その対応関係を学ばせる手法です。
たとえば犬の画像とともに「これは犬である」という正解データを与えることで、コンピュータは犬を判別できるようになります。この正解データを「教師データ」と呼びます。
教師あり学習は、大きく「分類」と「回帰」に分けられます。分類は、メールを「迷惑メールかどうか」で振り分けるように、データをカテゴリに割り当てるタスクです。回帰は、来月の売上金額のように連続した数値を予測するタスクで、需要予測などに用いられます。
過去の実績データが豊富な業務と相性がよく、データに答えがあるぶん学習が安定しやすく、精度の評価もしやすいというメリットがあります。
教師なし学習とは、その名のとおり正解(教師データ)を与えず、データだけからパターンや構造を発見させる手法です。何が正解かが事前にわからない場合でも、データに潜む傾向やまとまりを引き出せる点が特徴です。
代表的な手法が「クラスタリング(クラスター分析)」です。クラスタリングは、データが持つ特徴を基準に自然なグループ分けを行う手法で、たとえば購買データから似た嗜好を持つ顧客層を自動的に抽出する「顧客セグメンテーション」に活用されます。
ほかにも、多数の項目を少数の指標にまとめて分析しやすくする「次元削減」などがあります。何を発見すべきかが事前に明確でなくても、データから新たな知見を引き出せるのが教師なし学習の魅力です。
強化学習とは、コンピュータが試行錯誤を繰り返しながら最適な行動を学習する手法です。何らかの行動を選択して報酬(スコア)を得るという処理を繰り返すことで、報酬が最大化するような行動はどのようなものかを学習していきます。
強化学習が広く知られるきっかけとなったのが、ゲームAIの分野です。2015年から2017年にかけて囲碁のトップ棋士を次々と破った「AlphaGo」も、強化学習を活用していました。
近年では、ロボットの動作制御を学習させるロボティクスの分野や、刻々と状況が変わる広告配信・推薦システムなど、動的で変化の多い環境での意思決定にも応用が広がっています。この3つの手法は優劣で選ぶものではなく、解決したい課題の性質に応じて適切に使い分けることが重要です。
機械学習は、予測・認識・分析といったタスクを自動化できるため、多くの業界で活用されています。製造業の品質管理から小売の需要予測、Webサービスのレコメンドまで活用領域は年々拡大しており、近年は生成AIとの組み合わせによって新たな用途も生まれています。
ここでは、ブレインパッドの支援事例を交えながら代表的な活用例を紹介します。
レコメンド最適化とは、ユーザーの行動データをもとに、一人ひとりに最も適した情報や商品を提示する取り組みです。不動産情報サイト「LIFULL HOME’S」では、膨大な物件情報の中から、いつでも偏りなく多様な物件をユーザーに見せることが課題でした。
そこで、エンドユーザー・不動産会社・自社サービスの「三方よし」を実現するために、機械学習と数理最適化を組み合わせた物件表示の最適化に取り組みました。
ルールベースでは到達できなかった全体最適を、データドリブンなアプローチで実現したことで、ユーザーには多様な物件との出会いを、広告主には継続的な掲載機会を提供できる仕組みを構築しています。
【関連記事】
LIFULL HOME′Sが“広告主”と“エンドユーザー”との「三方よし」を実現する数理最適化の裏側
需要予測とは、過去の販売実績や季節要因などをもとに、将来の販売数や必要な在庫量を見通す取り組みです。需要の見込みが立たないまま発注すると、欠品による販売機会の損失や、過剰在庫によるコスト増といった課題が生じます。
機械学習を用いた需要予測では、天候・曜日・イベント・過去のトレンドなど多様な要因を取り込み、人手では難しい精度の予測を実現します。この需要予測により在庫の適正化や発注の効率化が進み、サプライチェーン全体のコスト削減につながります。需要予測の精度向上は、物流の効率化や食品ロスの削減といった社会的な課題の解決にも貢献します。
【関連記事】
【前編】未来を見据えた伊藤忠「流通DX」のリアル ~BrainPad DX Conference 2022~テーマ別 企業DX対談
価格最適化とは、需要や在庫、競合価格などのデータをもとに、利益を最大化する価格を導き出す取り組みです。その代表例が、状況に応じて価格を動かす「ダイナミックプライシング」です。
従来、価格設定は担当者の勘や経験に頼る部分が大きく、すべての商品に最適な価格を付けるのは困難でした。機械学習を活用すれば、価格弾力性(価格変動に対して需要がどれだけ変化するか)を推定し、「集客のために値下げすべき商品」と「多少値上げしても利益を確保できる商品」を見極められます。
インフレ圧力やDXの加速を背景に、データ駆動型のプライシングはここ数年で急速に普及が進んでいる領域です。
【関連記事】
小売DX最前線:データドリブン価格最適化の実践ガイド
画像認識を活用した外観検査・異常検知とは、製品や設備の画像データを分析し、傷や欠陥、劣化など通常状態とは異なる特徴を検出する技術です。製造業の現場では、目視検査の属人化や人手不足、品質のばらつきが長年の課題となってきました。
機械学習、とりわけディープラーニングによる画像認識を導入することで、製品検査や異常検知などの作業を効率化し、品質確認の精度向上や作業負担の軽減につなげられます。
ただし、不良品データのように発生頻度の低いデータが十分に集まらないケースでは、正常データをもとに異常を検知する手法や、教師なし学習を活用したアプローチが採用されることもあります。導入前には、期待できる効果や運用体制を整理し、現場業務に適した形で活用する必要があります。
【関連記事】
「異常検知・外観検査DX」における機械学習導入のポイント
機械学習モデルは、AIツールを導入するだけでは完成しません。データ収集からモデル学習、精度評価、運用改善まで、複数の工程を継続的に回していく必要があります。
ここでは、機械学習プロジェクトを「PoC(概念実証)で終わらせない」ために押さえておきたい工程を、順を追って解説します。
最初の工程は、データの収集とクレンジング(整形)です。まずは解きたい課題に関連するデータを集めます。社内に蓄積された業務データのほか、IoTセンサーや外部のオープンデータも有力な情報源になります。
ただし、集めたデータの多くはそのままでは学習に使えません。欠損値(抜けているデータ)の補完、外れ値やノイズの除去、表記ゆれの統一、フォーマットの変換といったクレンジングを行い、機械学習で扱える状態に整える必要があります。間違った情報や欠けたデータをそのまま使えば、予測精度は下がり、最終的な意思決定にも悪影響を及ぼします。
実務上、プロジェクト全体の工数の半分以上がこの工程に費やされることも珍しくなく、データの品質がモデルの精度を左右する土台となります。
データが整ったら、次はアルゴリズムの選定とモデルの学習です。重要なのは、解きたい課題の性質に応じて適切なアルゴリズムを選ぶことです。将来の数値を予測したいなら教師あり学習の回帰、データをグループ分けしたいなら教師なし学習のクラスタリング、というように、課題によって適した手法は異なります。
アルゴリズムを選んだら、前処理済みのデータを与えてモデルを学習させます。同じデータでもアルゴリズムの選び方によって結果が大きく変わるため、複数の手法を試して比較することも一般的です。
課題に対して最適なモデルを見極めるには、機械学習そのものへの知識と、試行錯誤を重ねる地道なプロセスが求められます。
学習したモデルは、テストデータを用いて評価し、必要に応じて調整します。正解率や誤差といった指標で精度を測定し、過学習が起きていないかを確認します。精度が不十分な場合は、特徴量の見直しやハイパーパラメータ(学習の設定値)の調整、データの追加収集に立ち返り、改善を繰り返します。
そして忘れてはならないのが、運用開始後の継続的なメンテナンスです。現実世界のデータは時間とともに変化するため、一度作ったモデルの精度は徐々に劣化していきます。精度を監視し、定期的に再学習や改修を行う運用設計が欠かせません。
PoCの段階で止まってしまうプロジェクトが多い理由の一つは、この継続運用までを見据えた体制が整っていないことにあります。中長期のロードマップを描き、業務改善に結びつけ続けることが、機械学習プロジェクトを成功に導くカギです。
機械学習で得た予測を、ビジネス上の打ち手にまでつなげる方法論として注目されているのが「数理最適化」です。データを活用するという観点において、実は機械学習・深層学習は手段のひとつに過ぎません。ブレインパッドの事例を紹介しつつ、ビジネスで数理最適化を実施するための手順やポイントについて説明します。
数理最適化とは、最適なアクションを決定するための方法論です。機械学習は主に未来の予測値を算出するのに使われる方法ですが、数理最適化はその予測値を使って、シミュレーションを行い、意思決定を自動化します。数理最適化は機械学習プロジェクト、およびビジネスの意思決定を加速させる非常に強力なツールです。
つまり、機械学習による「予測」だけでは最終的な判断が人に委ねられたままですが、数理最適化を組み合わせることで「結局どう行動すべきか」という意思決定までを自動化できます。両者は競合する技術ではなく、互いの役割を補い合う相互補完の関係にあり、組み合わせることでデータ活用の効果を最大限に引き出せます。

【関連記事】【前編】数理最適化の新時代到来~最適化→予測でDXは加速する~

【関連記事】【後編】数理最適化の新時代到来~最適化→予測でDXは加速する~
数理最適化は、施設配置・シフト最適化・生産計画など古くからビジネスに活用されています。たとえば勤務シフトの作成では、従業員ごとの勤務条件や必要人数といった複雑な制約を踏まえながら、最適なシフトを自動で組み上げることができます。
実際に、シフト管理システムに数理最適化を活用することで、より少ない工数で高い精度の勤務シフト作成を実現した事例もあります。従来は担当者が時間をかけて手作業で調整していた業務を自動化することで、工数削減と精度向上の両立につながっています。
【参考】高精度な勤務シフト作成の自動化
逆問題とは、出力結果から入力値を推定する問題を指します。機械学習を含め、一般的には実績データや観測データなどの入力値から出力結果を推定・予測するものですが、これを逆方向から考える、つまり「こうありたい」という結果から、それを実現する条件を求める問題であるため「逆問題」と呼ばれます。
たとえば「来月の優良顧客数を一定数まで増やしたい」という目標(結果)を先に設定し、そこから逆算して「どのような施策を打てばよいか」を導き出すといった使い方が考えられます。機械学習による予測と数理最適化を組み合わせることで、人間が受け入れやすい自然な解釈を伴った打ち手を導き出せる点が、逆問題解析の新たな可能性として注目されています。

【関連記事】「逆問題解析」~人間が受け入れやすい 、自然な解釈を生む数理最適化の新たな活用法~

【関連記事】意思決定を支援する技術「数理最適化」の最前線
最後に、機械学習について寄せられることの多い質問にお答えします。
代表的な分類は、教師あり学習、教師なし学習、強化学習の3つです。教師あり学習はラベル付きデータ、教師なし学習はラベルなしデータ、強化学習は報酬を最大化する行動学習を扱います。
教師あり学習は、正解が与えられた過去データから予測や分類のルールを学ぶ手法で、需要予測や画像分類などに使われます。教師なし学習は、正解のないデータからパターンやまとまりを見つける手法で、顧客のグループ分けなどに用いられます。
強化学習は、試行錯誤を通じて報酬が最大になる行動を学ぶ手法で、ゲームAIやロボット制御に活用されます。解決したい課題に応じて使い分けることが大切です。
予測・判別・分類が必要な業務と相性がよく、需要予測、画像認識、異常検知、自然言語処理などで広く活用されます。ビジネスの現場では、来客予測や検査の自動化といった形で実装されやすいのが特徴です。
具体的には、小売・流通での需要予測や在庫最適化、製造業での外観検査・異常検知、マーケティングでのレコメンドや顧客分析、コールセンターでの問い合わせ対応支援など、業種を問わず幅広い領域で導入が進んでいます。
「過去のデータから将来を予測したい」「人手による判断を自動化したい」という課題があれば、機械学習の活用を検討する価値があります。
一律に「件数が多いほど良い」とはいえません。データの質、すなわち正確さ・最新性・偏りの少なさが重要で、これらが学習や利活用の前提になります。
たとえば、件数が多くても誤りや欠損、偏りの多いデータでは、かえって予測精度を下げてしまうことがあります。逆に、量はそれほど多くなくても、質が高く目的に合ったデータであれば、実用的なモデルを構築できるケースもあります。
重要なのは量と質のバランスであり、目的に照らして「どのようなデータを、どれだけの質で集めるか」を見極めることが、機械学習を成功させる出発点となります。
機械学習とは、データに含まれるパターンやルールをコンピュータ自身に学習させ、予測や分類を可能にする技術です。AIを実現するための中核技術であり、ディープラーニングを含むさまざまな手法によって、需要予測・画像認識・自然言語処理・レコメンド・異常検知など、幅広い領域で実用化が進んでいます。
さらに、機械学習の予測結果を数理最適化と組み合わせることで、単なる「予測」を超えた「意思決定の自動化」までを射程に収めることができます。
生成AIの台頭によりAI活用への期待がいっそう高まる今、機械学習はAI・生成AI時代を支える基盤技術として、ますます重要性を増しています。データ量の増加や計算性能の向上を背景に、その活用範囲は今後さらに広がっていくでしょう。
自社のどの業務に機械学習を活かせるかという視点を持つことが、データ活用時代の競争力につながっていきます。
あなたにオススメの記事

2023.12.01
生成AI(ジェネレーティブAI)とは?ChatGPTとの違いや仕組み・種類・活用事例

2023.09.21
DX(デジタルトランスフォーメーション)とは?今さら聞けない意味・定義を分かりやすく解説【2024年最新】

2023.11.24
【現役社員が解説】データサイエンティストとは?仕事内容やAI・DX時代に必要なスキル

2023.09.08
DX事例26選:6つの業界別に紹介~有名企業はどんなDXをやっている?~【2024年最新版】

2023.08.23
LLM(大規模言語モデル)とは?生成AIとの違いや活用事例・課題

2024.03.22
生成AIの評価指標・ベンチマークとそれらに関連する問題点や限界を解説













