



メルマガ登録
-
テーマから探す
-
技術から探す
-
業界・事例から探す
-
関連トレンドから探す
テーマから探す
技術から探す
業界・事例から探す
関連トレンドから探す

データエンジニアリング本部 アナリティクスエンジニア部に所属している安田国裕です。
私の経歴を簡単に説明すると、前職ではいわゆるSIerで大小の様々なシステム開発を経験した後に、アーキテクトとして開発の基礎を支えたり、機械学習・クラウド・コンテナなどの技術を調査し、社内外に広める部署で働いていました。
データエンジニアリング本部におけるアナリティクスエンジニアの役割としては、分析環境の整備から分析で扱うデータ管理、モデルの運用などの分析システム開発を見据えたエンジニアリングの支援となっています。
この業務についてこれから詳しく説明していきます。

興味のある人にとっては釈迦に説法ではありますが、次のステップを踏んでそれぞれ分析システムを既存システムと連携し、デジタル・トランスフォーメーション(DX)の実現に向けて計画されていることが多いかと思います。
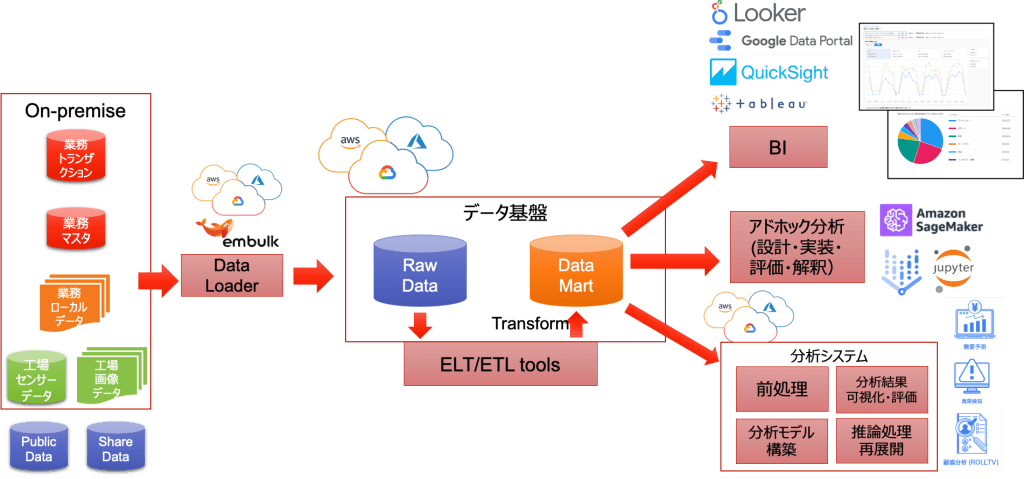
それぞれで仕組みの必要性を説明し、必要な体制についても少し触れたいと思います。
データ分析の実現性検証(PoC)の先のシステム開発や運用計画で、どのようなことを考慮するのかをイメージしてもらえればと思います。そのため、簡単なデータサイエンスの知識はある前提で、エンジニアリングに焦点を当てて進めます。
分析システムのロードマップを敷いてプロジェクトを進めるにあたり、データ分析の「PoC止まり」の壁を聞いたことがある方もいらっしゃると思います。PoC止まりの壁とは、実現性検証だけでプロジェクトが中止になってしまうことが多く発生し、リスクばかりに目がいって新たな企画が出難い悪循環に陥っている状況を指します。弊社で払拭のために行っている取り組みの一環も少し紹介したいと思います。
まずは、データ基盤と可視化について、日々の何らかのセンサー・データやトランザクション・データを蓄積する基盤があると、BIのダッシュボードを使ってKPI(重要業績評価指標)をリアルタイムに表現することが容易になります。
他にもエクセルでアドホックにデータ分析を行うことで、定量的に意思決定を行うきっかけになります。この蓄積されたデータを活用して、モデルのトレーニングやバッチ予測を行う分析システムを合理的に実現出来るようになります。
データ基盤と連携する時には一般的に次のことを行います。
業務で統一されたデータ型やフォーマットを定義するデータスキーマのバリデーションを行い品質を保つようにします。
また、バリデーションエラーやシステムエラーで修正してリトライされても、漏れや重複なく一意性が保たれるようにデータパイプライン(図2)を設計する必要があります。
扱うモデルには、機械学習モデルや数理最適手法を用いたアルゴリズムがあります。
代表例
データの種類・解きたい課題により実現する手法は様々です。
次のようなきっかけでモデルの精度に影響がある場合には、モデルを更新する仕組みも当然必要になります。
更新の頻度が少ない場合には、Jupyterノートブックや簡単なスクリプトで定期的に人が対応しても、猫の手を借りて対応しても構いません。
しかし、再利用のスニペットコードなどの場合にはオペレーションミスが起きることも多いと思います。そういった場合にはモジュール分割を綺麗に行った上で、必要なエラー処理などを行い簡単なスクリプトにすることでも対応出来ます。
一方で、頻度が多い場合には、データ取り込みからモデル更新やモデルの評価まで広い範囲で仕組み化することで、効率的に分析業務を行うコスト・メリットが出てきます。
継続的にモデルを更新する際に、蓄積したデータを使ってモデルをトレーニングすることで合理的なシステムを実現出来るようになります。
トレーニングの頻度は入力データの傾向などにより変わってきます。月1もあれば週1ということもあります。
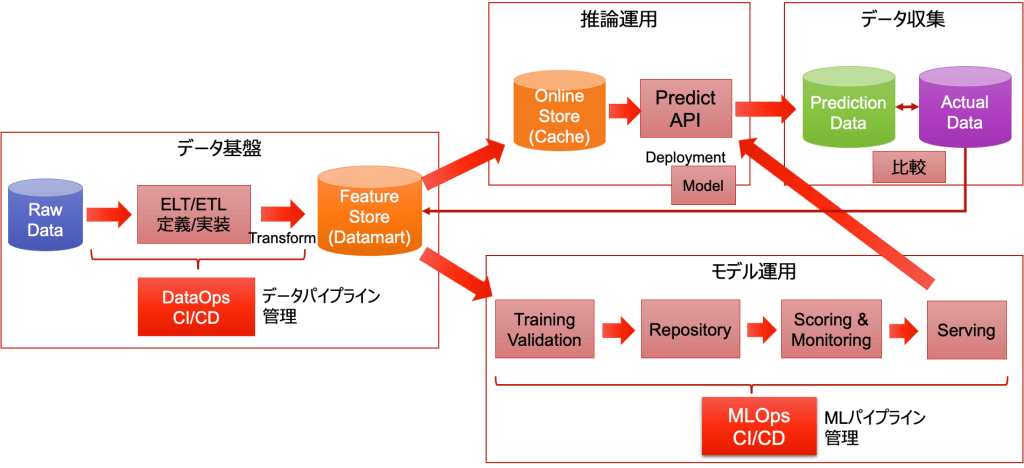
特徴量の数が同じ場合には、データを入れ替えて学習することになります。この場合はコードの変更を伴わずに、トレーニングの処理を定期的に再実行出来るようにMLパイプライン(図2)としてまとめておくことが多いです。
特徴量の数が変わる場合には、コードの変更が伴います。もし変更をシステムとして許容するように設計するならば、影響範囲を少なくするように工夫することがあります。
どの期間をトレーニング・データとするか、評価にはどの期間のデータを使うか、モデルのトレーニングに含まないようにズラすなどしてデータ・リーケージ(※)に注意が必要です。また、現新モデルで比較する際に同じ評価データを使ってフェアに行うことも重要です。
(※予測の時点で利用出来るない未来の情報などを含んでモデルをトレーニングした場合に、将来収集するデータに過度に適合してしまっている。)
上記のモデルの更新可否を判断するために、次の目的で可視化を行うことが良くあります。
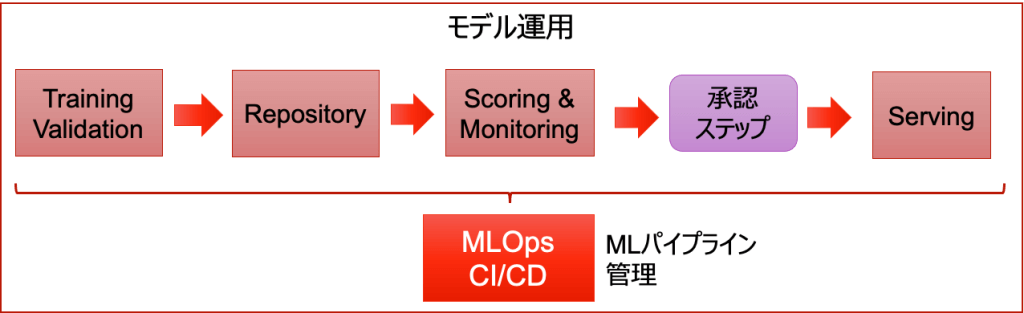
複数人で先ほどのチェックを参考に多角的にモデルを評価した上で、最終的には人間がモデルを入れ替えるかどうかの判断を行うことが多いです。複数の評価項目があり、一定のルールでは判断し難いためです。
トレーニングパイプラインの後のデプロイ前に、このジャッジを行う承認ステップ(図3)を入れておくと、かなりの部分が自動化されスマートに実行できます。
予測結果をどのように利用したいかの要件により、リアルタイムまたはバッチのシステムを検討することになります。(早い段階で利用イメージが付くことが多いです。)
モデルを動かす仕組みとしてはユースケースによって次のパターンがあります。
利用方法
サービス提供方法
学習時と同じように蓄積されたデータを使って予測を実施することになります。その予測結果を業務システムにデータ連携し、日々の業務を効率化させるために利用します。
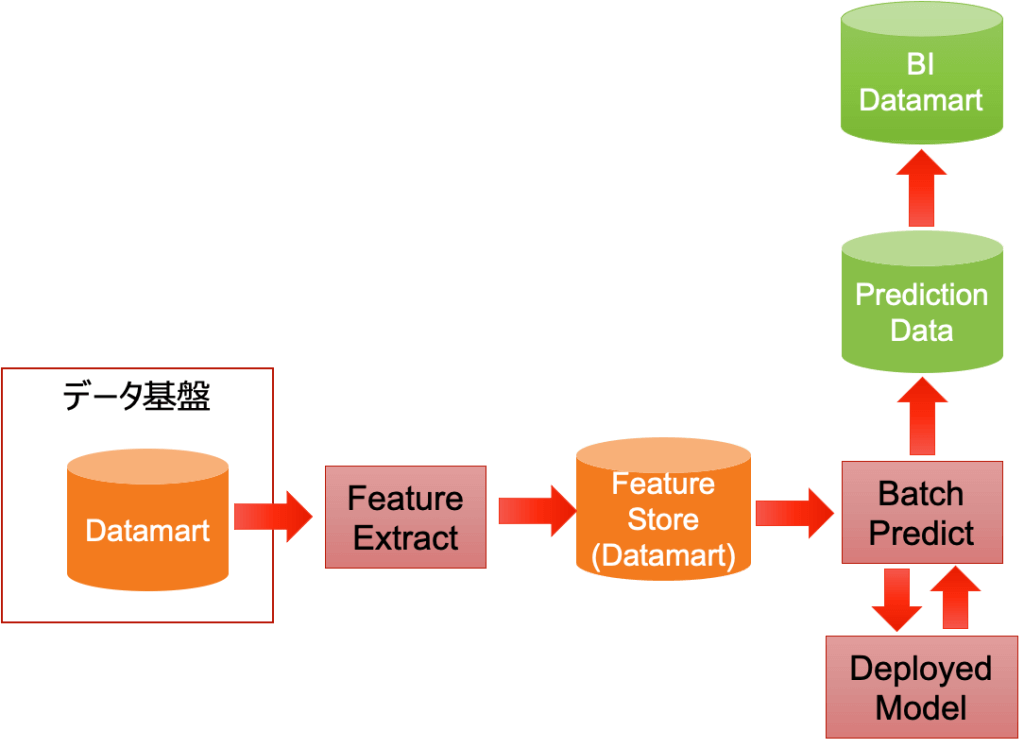
蓄積されたデータを使わずに、リクエストに必要な特徴量を載せて実行することになります。結果を保持する場所は、どこで評価を行うかによって変わってきます。
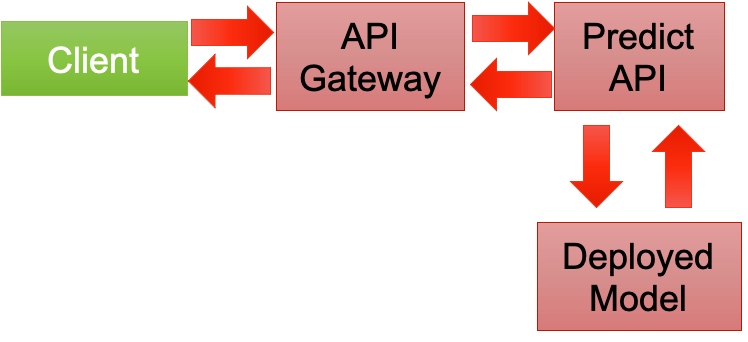
予測する値の組み合わせが決まっているのであれば、まとめて全ての組み合わせの予測を求めてキャッシュに載せておき、モデルを使った予測をいちいち実行することなく、そのキャッシュから結果を折り返すことで、低遅延にレスポンスを返すことが出来ます。レコメンドエンジンで良く使われます。
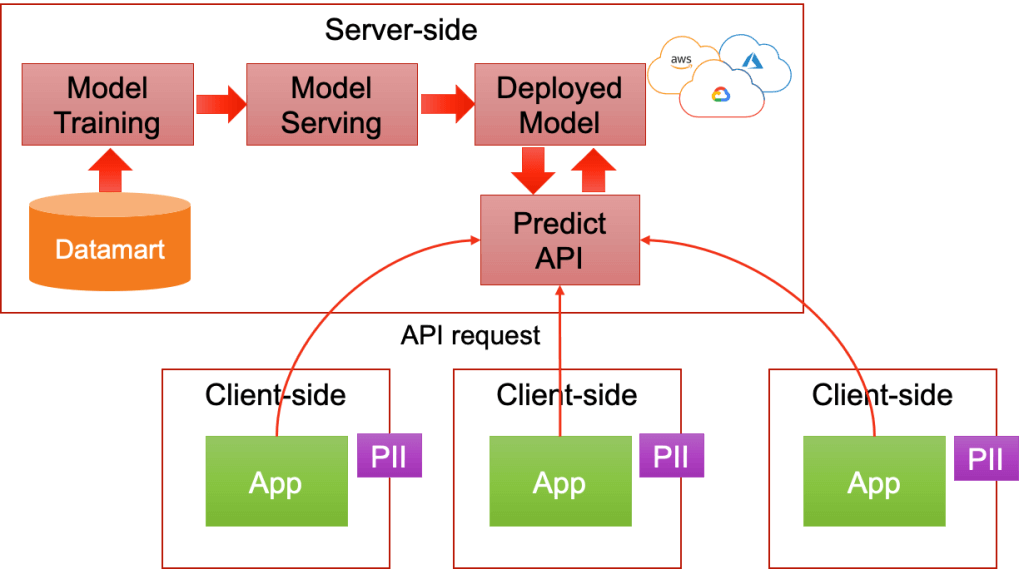
クラウドで学習したモデルをそのままデプロイする方法は、各クラウドベンダーの機械学習サービス Vertex AI/SageMakerを使うと手軽にサービスを提供することが出来るようになってきています。プロトタイプを使って素早く実地テストを行いたい時に効果的な手段です。
セキュリティに考慮した通信のアクセス制限と機密情報をマスクしてAPIを呼び出す必要が出て来ます。
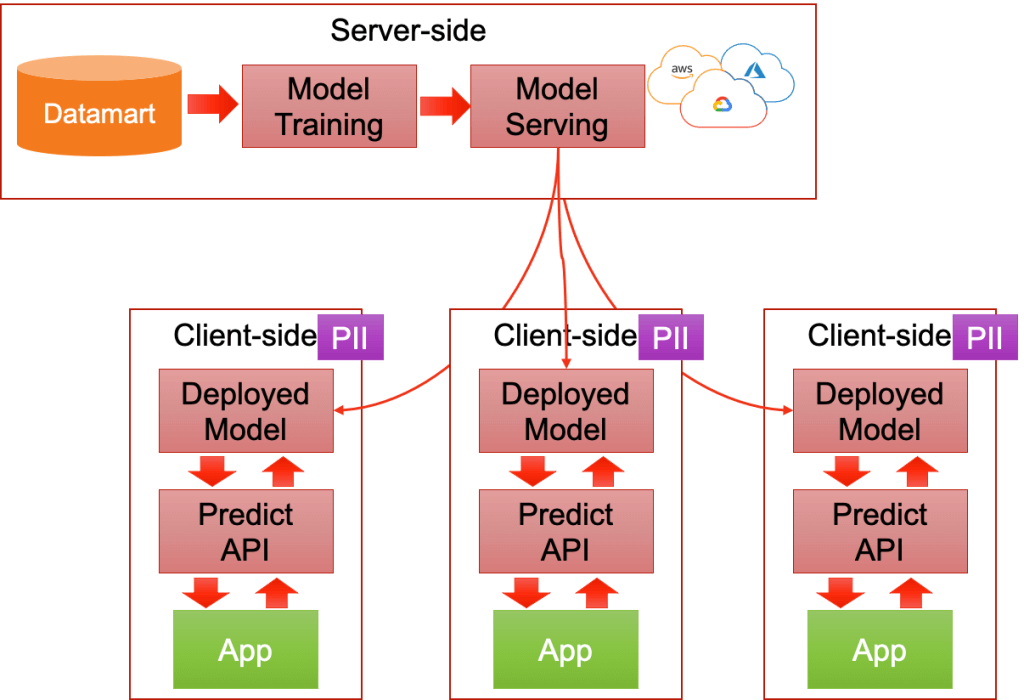
クラウドで学習したモデルをエッジ端末にデプロイする方法では、モデルファイルをエッジ環境に合わせて形式を変換して動かすことになります。また、ポータビリティが優れたコンテナで提供する方法もあります。
各クラウドベンダーでデプロイやモニタリングするライブラリを使う方法もあります。素早く実地テストしたい場合には活用していきます。
エッジ端末で学習した結果をクラウドに吸い上げて連携させるフェデレーションラーニングという構成も出て来ているようです。
モデルをトレーニングする際やバッチ予測ではデータ量や特徴量の数などによって並列処理が効果的である場合、GPUやHPCを使うこともあります。また、クラスタ上で並列分散で同時実行数を上げる仕組みを考えることもあります。
他にも、性能要件に合うように、CPUの空いてる場合に効率的に使われるようにベクトル化する方法、行列のマルチコア並列計算ライブラリ、マルチプロセス、コンテナを分散処理する方法など、状況によって使い分けて考えます。
モデルをトレーニングするところはスケジューラで定期実行させることが多いですが、予測を動かす部分ではユーザーインターフェースを用意することもあります。
予測データの入力から、予測・最適化実行、予測結果出力などを行うことが多いです。
結果の見せ方によって様々ですが一例として次があります。
最近では分析アプリケーションを分析コードと同じPythonで書けてPandasなどで表やグラフを扱いやすくしたライブラリが増えて来ています。Streamlit やPlotly Dashを使うことでデータサイエンティストのアプリ開発への敷居は下がっています。分析アプリ開発者にとってはプロトタイプを開発し易いライブラリとなっています。
ただし、機能要件によっては合わないことがあります。細かいところでカスタマイズが難しく、凝ったUI/UXの実現は厳しいです。また、動かすためのプラットフォームやDevOpsの環境はクラウドサービスを組み合わせて考える必要が出てきます。
課題に対して仮設モデルをいくつか作って実現性を検証します。次に業務で十分に利用できるまで、モデルの精度向上を行います。
モデルだけで判断させる完全自動化を目指すのではなく、最終的には人が判断し、多少の修正は許容する半自動化を目指すことが多いです。
次に簡易的にシステムに組み込むフィールドテストを経て、本格的な分析システムの開発フェーズに入ります。
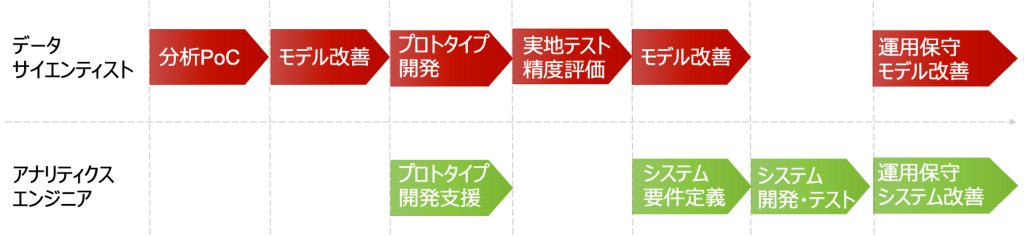
まずは、データサイエンティストないしはコンサルティング部隊で分析の実現性を検証します。(Proof of Concept)
使えるようにモデルの対応範囲を増やすことや精度を改善した後に、実地テスト用にプロトタイプ開発を行います。理想的には先のシステム化を見据えて、早い段階でアナリティクス・エンジニアがサポートして行きます。
本番システム開発では要件定義、設計、開発、テストとよくある開発ステップを踏むことが多いです。
運用保守にて、継続的にモデルやシステムを改善していくことになります。
単にAIを導入することで一部の業務へのコスト削減や業務効率を狙うとコスト・メリットが出難いことが多いです。ユーザにはデータを活用した新たな付加価値を提供する必要性を訴えるべきです。
例えば、パワーポイントやノートブックでデータ分析の結果を報告するだけでなく、分析アプリのプロトタイプを早い段階で提供することが効果的です。ユーザ体験を提供することで、分析結果を活用してもらう具体的なイメージを持ってもらい、データを使った変革へのきっかけになります。多方面への広がりの可能性にもなります。
また、データ基盤〜可視化〜分析システムへとステップアップすることも大事です。データ駆動で業務改善を行うマインドを浸透させながら導入すると、ユーザが徐々にデータによる説得力を身に付けた上で分析システムを受け入れる環境が整ってきます。
データ分析の周辺システムにおいて、データ基盤の構築からBIによる可視化、分析モデルの運用、予測処理周辺の仕組み、分析アプリまで、一部分ですが、そこでどういった考慮が必要かをお分かりいただけたのではないでしょうか。
PoC止まりではなく、データ分析から分析システム開発まで、DXを見据えてビジネスプロセスを抜本的に変えて、顧客に新たな価値を提供を行いたいときは、ぜひ弊社にお問い合わせいただけますと幸いです。
▼DXの定義や意味をより深く知りたい方はこちらもご覧ください
「DX=IT活用」ではない!正しく理解したいDX(デジタル・トランスフォーメーション)とは?意義と推進のポイント

あなたにオススメの記事

2023.12.01
生成AI(ジェネレーティブAI)とは?ChatGPTとの違いや仕組み・種類・活用事例

2023.09.21
DX(デジタルトランスフォーメーション)とは?今さら聞けない意味・定義を分かりやすく解説【2024年最新】

2023.11.24
【現役社員が解説】データサイエンティストとは?仕事内容やAI・DX時代に必要なスキル

2023.09.08
DX事例26選:6つの業界別に紹介~有名企業はどんなDXをやっている?~【2024年最新版】

2023.08.23
LLM(大規模言語モデル)とは?生成AIとの違いや活用事例・課題

2024.03.22
生成AIの評価指標・ベンチマークとそれらに関連する問題点や限界を解説













