



メルマガ登録
-
テーマから探す
-
技術から探す
-
業界・事例から探す
-
関連トレンドから探す
テーマから探す
技術から探す
業界・事例から探す
関連トレンドから探す


筆者はブレインパッドで、業務・オペレーション改善に関するコンサルティングを担当しています。今回は「サプライチェーンマネジメントにおけるDX」について、ご紹介したいと思います。
サプライチェーンとは、原材料の調達から、製造・生産、保管、物流・配送、販売といった各拠点を経て、最終消費者の手に渡るまでの生産・流通プロセスの全体を言います。
—————————————————————————————————————————
【川上】モノの流れ(供給)→
原材料・部品調達(サプライヤー) ⇄ 製造・生産(メーカー) ⇄ 物流(物流事業者/卸売業者) ⇄ 販売(小売業者) ⇄ 消費(エンドユーザー)
←情報の流れ(需要)【川下】
—————————————————————————————————————————
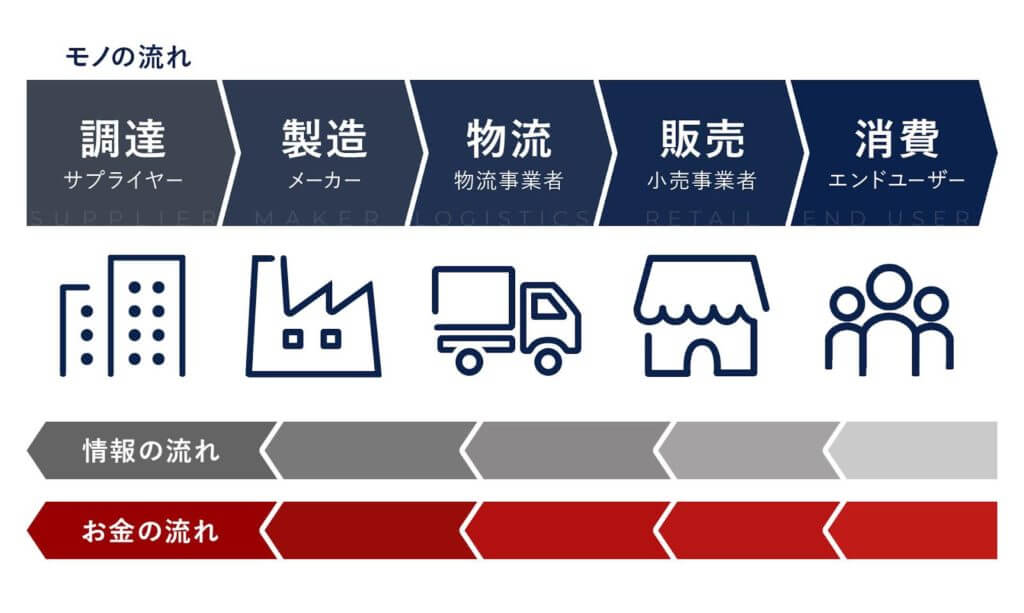
一般に、データによるサプライチェーンの改善は、各企業単体で入手可能な情報のみで取り組むよりも、サプライチェーンの企業を跨いだ上流・下流から共有・連携されたデータを活用する事で大きな効果を発揮します。
例えば、商品の個体管理番号を共通化しそのデータを蓄積すれば、下流に位置する会社は「何が・どこに・どれだけ」生産されていて在庫されているのか把握できるようになります。
他方、上流に位置する会社は、「何が・どこに・どれだけ」売れているのか把握でき、それに基づいた自社製品の生産・調達計画が立てられます。

「2024年問題」で日本の物流になにが起きるのか、より深く知りたい方はこちらもご覧ください。
サプライチェーンでDXを行うとなると、数々の問題点が出てくるので、それらをひとつひとつ解決していく地道な工程が必要になります。
特に弊社が得意とするAI(人工知能)の需要予測に関する分野は、導入に対するクライアント側の期待値が非常に大きいのですが、その内容や工程が一般には理解されにくい「ブラックボックス」になっているケースが多く、それ故に導入の適用範囲・プロセス・効果を誤解されているケースを多くお見かけします。
同業他社の導入事例などを参考に「需要予測の向上で精度・利益率を○%上げられるか?」といったご相談を受けることが多いのですが、こういった問いに活動前から答えることは不可能であり、データを見る前に言い切ってしまうことは、不誠実であるとさえ考えています。
また、「御社の需要予測(ソリューション)の特徴は?」など、門外不出の「秘伝のたれ」のようなものがあり、それを適用すれば、さまざまな需要予測ができるようになるといった誤解をされている方もいらっしゃるのですが、通常は世界中にいる研究者が開発した様々な手法を、問題の状態によって適宜使い分けることが多く、プログラムなどのアセットの有無というよりも、対峙している問題がどのような類の問題か見分け、それに応じ適切なアプローチを取っていく「プロの目の存在」が何より重要になってきます。
実現に向けた時間軸を考える際にも課題があります。全ての検討の基礎となるデータについてどんなデータが揃い/集められるかがケースバイケースでかなり差があり、実際に手を付けてみなければわからないことが多いのです。データの管理をシステムの実装・運用を契約しているベンダーに任せ、データは溜めてはいるものの分析を行った経験が薄く、データがどのような状態にあるのか把握されていない状況も多く見られます。
そのため、AIの導入プロジェクトにおいては、単に「需要予測ソリューション」のような静的なシステム・パッケージ導入の活動として捉えるのではなく、導入に際してのROI(投資利益率)の算定、検討アプローチ・スケジュールの立案を実際のデータを触りながら行い、場合によっては実行プランをアップデートしていくという、動的なプロセスとして捉えることが重要と考えます。
「どこに難所があり、どこから手を付けるのが効果的か」といった実情を把握しないまま設計された計画は、非現実な効果やスケジュールで彩られた「机上の空論」で終わってしまう可能性が高く、元々の計画進行に拘って無理矢理遂行したプロジェクトは、手段と目的を見誤り、最終的に(不必要な)大規模な見直しを迫られることになります。
機械学習等で予測モデルを構築する際に重要となってくるのは、アルゴリズムに読ませる「きれいなデータ」の整備です。
きれいなデータというのは、必要な情報が矛盾やダブり等の「曖昧さ」がなく整っている、いわば「蒸留」されたデータのことです。
クライアント側から「データは大量にあります」と伺う事がありますが、そのデータは多くの場合、分析を前提としておらず、現状業務の「単なるログ」として残っている場合が多いので、そのまま(分析・活用という観点)では使えないケースが多いです。
例えば、同商品をマイナーチェンジした際の商品コードが、あるときは別コードを採番、あるときはそのままでバラバラな運用で管理されており、どの期間の売上データに記録されている商品が実態としてどの商品を指し示しているのかわからない、といったことがあります。発売日や発売期間の情報が正確に入力されておらず、さらに発売日前に一部店舗がフライングで販売してしまったデータが含まれているといったこともあります。
その時点においての「業務運用」という観点では、それが大きな問題とならず業務が回ったかもしれません。しかし、数年経った後に「業務改善」をそのデータを使って当時の状況を定量的に振り返る必要が生じた場合に、精緻な分析をすることは困難になります。
非常に地味な作業ですが、サプライチェーン全体で効率化を図っていく際には、このようなデータについて、1つずつ原因の調査・修正(正確には個々の課題に対する対応方針の策定など)を行っていく必要があります。
実は現場のアナリスト、データサイエンティストが、多くの時間と頭を使う工程です。
データをアナリストやデータサイエンティストに渡して、「素晴らしいアルゴリズムを考えてもらえさえすれば、すぐにAIが導入できる」というような期待をされている方には厳しい現実という印象を持たれるかもしれませんが、検討当初はこのような「過去の遺産」と対峙せねばならず、精度の高い予測値が出るという分かりやすい結果はすぐに出ません。
後編では、私が実際に支援させていただいた事例を紹介しつつ、サプライチェーンマネジメント実現のポイントを探ります。
この記事の続きはこちら
【後編】DXに必要なのはデータを「蒸留」させるプロセス ~巨大流通企業の「サプライチェーンDX」を成功に導く勘所~
あなたにオススメの記事

2023.12.01
生成AI(ジェネレーティブAI)とは?ChatGPTとの違いや仕組み・種類・活用事例

2023.09.21
DX(デジタルトランスフォーメーション)とは?今さら聞けない意味・定義を分かりやすく解説【2024年最新】

2023.11.24
【現役社員が解説】データサイエンティストとは?仕事内容やAI・DX時代に必要なスキル

2023.09.08
DX事例26選:6つの業界別に紹介~有名企業はどんなDXをやっている?~【2024年最新版】

2023.08.23
LLM(大規模言語モデル)とは?生成AIとの違いや活用事例・課題

2024.03.22
生成AIの評価指標・ベンチマークとそれらに関連する問題点や限界を解説













