



メルマガ登録
-
テーマから探す
-
技術から探す
-
業界・事例から探す
-
関連トレンドから探す
テーマから探す
技術から探す
業界・事例から探す
関連トレンドから探す

4日間にわたり大きな盛り上がりを見せた「Snowflake Summit 2026」が幕を閉じました。今年のテーマである「Making AI Real for Business」が示す通り、AIを本番実装しAgentic Enterpriseになるための方法が余すところなく伝えられたサミットでした。3日目のBuilders Keynoteが直前で中止になるハプニングがありながらも、4日間で多数の情報が発信されました。本記事では、「Snowflake Summit 2026」の総まとめとして、ブレインパッドの視点でサミットで発表された技術の深掘り、ブレインパッドメンバーが参加したセッションの情報、そのほかサミット中のこぼれ話など、全体を振り返る内容をお届けします。


今年のサミットで発表された技術は数多くありますが、振り返ってみると、その多くは一本の線でつながっています。それは「AIエージェントが、企業のコンテキストを理解し、ガバナンスの効いた範囲で、実際の業務行動まで担う」という線です。Keynoteで語られた「モデルそのものは、もはや差別化要因ではない。競合も同じモデルを使えるからだ」というメッセージのとおり、勝負所はモデルの外側——データとコンテキスト、そしてそれを安全に運用する仕組みへと完全に移りました。本章では、注目の発表を振り返ったうえで、私たちブレインパッドが現場支援の経験に基づいて考えた「これから企業に求められること」を読み解いていきます。
まず、本記事で繰り返し登場する主要な発表を整理します。詳細は速報記事もあわせてご覧ください。
ここからは、これらの技術が組み合わさったとき、企業の現場で何が起きるのかを考えていきます。
技術の羅列だけでは、自社の景色は浮かびにくいものです。そこで、「法人営業」の現場を例に、今回の発表が束になったときの将来像を描いてみます。
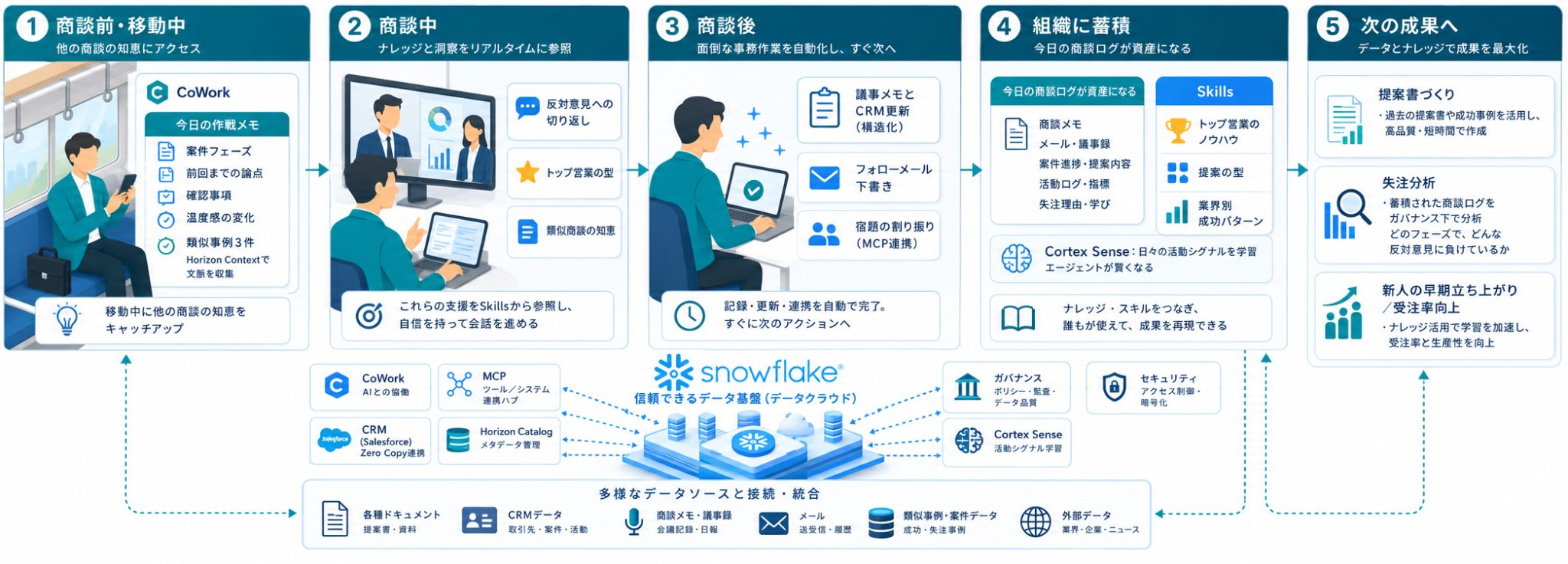
朝、行きの電車の中。営業担当者はスマホからCoWorkに「今日の商談先について教えて」と話しかけます。専属エージェントがMCP経由で社内のデータを横断し、移動時間のうちに「今日の作戦メモ」が届く。中身はこんな具合です。
これまで先輩への聞き込みでしか手に入らなかった「他の商談の知恵」に、誰もが移動時間のうちに辿り着けるわけです。
見落とせないのは、この担当者が「すべてのデータ」を見ているわけではない点です。CRMのデータはゼロコピーでSnowflakeに入り、Horizon Catalogのガバナンスの内側で扱われます。類似事例は参照できても権限のない顧客の連絡先や金額はマスキングされ、外部へのエクスポートはデータムーブメントポリシーが手前でブロックする。Keynoteのデモで示されたとおり、「誰でも聞ける」と「何でも見える」は別物として設計できます。
そして商談本番。Web会議は録音され、文字起こしが構造化されてCRMへ、そしてゼロコピーでSnowflakeへ流れ込みます。本当の変化が始まるのは、むしろ商談が終わったあと。会議室を出た時点で、エージェントはすでに動き始めています。
この蓄積が一番効いてくるのが、トップ営業の暗黙知です。話の組み立て方や切り返しのパターンを音声データから抽出し、Skillsとして記述できれば、スキルカタログを通じて組織全体で共有できる。新人の専属エージェントに、トップ営業の型と過去の類似商談の知恵が最初から備わっている状態も、夢物語ではなくなってきました。
商談の前後が変われば、その先の業務も連鎖して変わります。今回の機能群に引きつけるなら、たとえばこんなシーンです。
CoWorkで誰もがデータにアクセスでき、MCPでエージェントが実際のアクションまで取れるようになる。この便利さは、裏返せばリスクの拡大でもあります。たとえば、誰もが役員のカレンダーに予定を入れられてしまったら。エージェントが気を利かせて、確認前のメールを顧客に送ってしまったら。実際、Keynoteのデモではエージェントがその場でメールやSlackメッセージを送信する場面があり、会場が沸く一方で、私たちは「これが本番業務なら、どこに承認を挟むべきか」を考えずにはいられませんでした。
Snowflakeもこの問いに正面から答えています。
Opening Keynoteの記事でも触れた「ガバナンスの境界を、データからAIの行動へ広げる」という方向性が、Platform Keynoteでは具体的な機能群として裏付けられた格好です。「つながる範囲」を広げる発表と、ガバナンスを「行動」まで効かせる発表が常にセットで語られていたことこそ、本番実装を本気で見据えている証だと受け止めました。
ここまでの将来像には、ひとつの大前提があります。エージェントが参照するデータが、AIの読める形で蓄積されていることです。

「AI-Ready」と言葉にするのは簡単ですが、データをその形にするのは、多くの場合IT部門やDX部門ではなく、現場の担当者です。商談メモを書くのも、報告資料をつくるのも現場であり、その人たちの入力の仕方を変化させない限り、Horizon Contextがどれだけシグナルを集めても、肝心の中身が空っぽのままになってしまいます。
だからこそ先決なのは、現場に「データがきれいになったら、こんな良いことがある」を先に体感してもらうことだと考えています。幸い、CoWorkはその体感装置として優秀です。整備されたデータ領域でエージェントに質問し、数秒で答えが返ってくる体験を一度味わえば、「自分のデータも食わせたい」という動機が現場側から生まれます。最初の一歩は大げさなものでなくて構いません。これまでPowerPointの図の中に埋めていた数字を、Excelのテーブル形式でためる——それくらいの一歩から、AI-Readyへの道は始まります。
もう一段難しいのが、まだデータになっていない知識、すなわち暗黙知です。私たちは2つのアプローチが要ると考えています。
ひとつは、「ないデータを集める努力」です。ベテランの判断基準を構造化して聞き出す取り組みに加え、現実的に効くのは音声です。商談や会議をどれだけ録音できるかで、後から導き出せる暗黙知の量が変わります。AI_COMPLETEが音声・動画を入力として扱えるようになった今、「録音する文化」そのものが競争力の源泉になりつつあります。

Skillsについても同じことが言えます。生成AIの活用支援の現場では、優秀な個人がプロンプトや手順を磨き上げても、それが個人の中で完結してしまうケースが非常に多いのです。皆さんの組織にも、思い当たる節があるのではないでしょうか。今回スキルカタログが発表されたことで、個人の工夫を組織で共有・再利用するための地盤は整いました。あとは、磨いた型を自分の手元に閉じず、当たり前にカタログへ載せていく——そんな共有の文化を育てていけるかが、暗黙知が組織にたまるかどうかの分かれ目になります。
もうひとつは、「すでにあるデータをAI-Readyに整備し、更新し続ける仕組み」です。ここで興味深かったのが、あるセッションで紹介された「コンテキストエージェント」の発想でした。人がAIに聞くのではなく、AIが業務データやクエリ履歴を読み解いたうえで「ここが曖昧です。どちらの定義が正ですか」と人に聞きに来る。この向きの反転によって、メタデータ記述の精度が約60%から約95%まで上がったという報告もありました。すべてを人手で文書化するのは現実的でない一方、すべてを自動に任せるのも危うい。指標の定義変更のように業務の根幹に関わる情報は人の承認を挟み、それ以外は自動更新に任せる——この線引きの設計こそが、Horizon ContextやCortex Sense、Skillsを活かす土台になります。
最後に、これらすべてを貫く考え方として、コンテキストエンジニアリングに触れます。
Keynoteの「モデルは差別化要因ではない」という指摘は、まさにそのとおりだと感じます。さらに言えば、モデルだけでなくプラットフォームのサービス機能も、各社の発表を見る限り急速に同質化していきます。最後に残る差は、自社の業務・指標・判断基準を機械可読な形で蓄積したコンテキスト、つまり企業のIPそのものです。
だからこそ、コンテキストは「リポジトリ」として一元的に管理し、特定のプラットフォームやモデルに縛られず付け替えられる状態にしておくことが重要になります。サミットのセッションでも、メトリクス定義やオントロジー、Skillsをオープンな形式のリポジトリとして保持し、SnowflakeにもほかのプラットフォームにもMCP経由のAIツールにも展開できる構成が示されていました。コンテキストを一度きりの設定ではなく、作る・検証する(想定ユーザーごとのテスト質問でシミュレーションする)・運用する・エージェントの実行トレースから改善する、というライフサイクルで回す。これは、データを使い捨ての資料ではなく、品質保証とオーナーを持つ「プロダクト」として扱う発想にほかなりません。
AIエージェントの時代において、企業の競争力は「どのモデルを使うか」ではなく「自社のコンテキストをどれだけ深く、安全に、運用可能な形でエンジニアリングできているか」で決まる——。4日間の発表を貫いていたのは、この一点だったと私たちは考えています。
次章では、こうした視点を持つブレインパッドのメンバーが、実際に現地で参加したセッションの中から特に印象的だったものをご紹介します。
本サミットでは、グローバルから集まった登壇者から500を超えるセッションが発表されました。今回ブレインパッドは、「経営層」「データサイエンティスト」「アライアンスセールス」という3つの異なる専門領域を持つメンバーで参加したので、各自の視点から「Snowflake Summit 2026」の注目セッションを紹介します。
データエンジニアリングの現場を長く歩んできたAJ Steers氏のセッションです。氏が突きつけたのは「あなたのデータプロダクトのユーザーは、もはや人間ではなくエージェントである」というパラダイムシフト。エージェントは会議室でオンボーディングできない代わりにドキュメントを確実に読むため、コンテキストの置き場所を整備し、ミスのたびにエージェント自身にドキュメントを改善させる運用の型が示されました。一定の失敗率を織り込んで設計せよという指摘も、今年のテーマ「Making AI Real for Business」に通じる現実的な視点です。
私たちが特に目を見張ったのは、後半のライブデモです。MCPは外部の業務ツールを呼び出す仕組みとして語られることが多いですが、このセッションでは、ツールがチャットの中にUIそのものを返していました。コネクタの一覧が画面に展開され、フィルタで絞り込み、同期履歴へとドリルダウンしていく。会話の流れの中に、操作できるダッシュボードが現れる体験です。
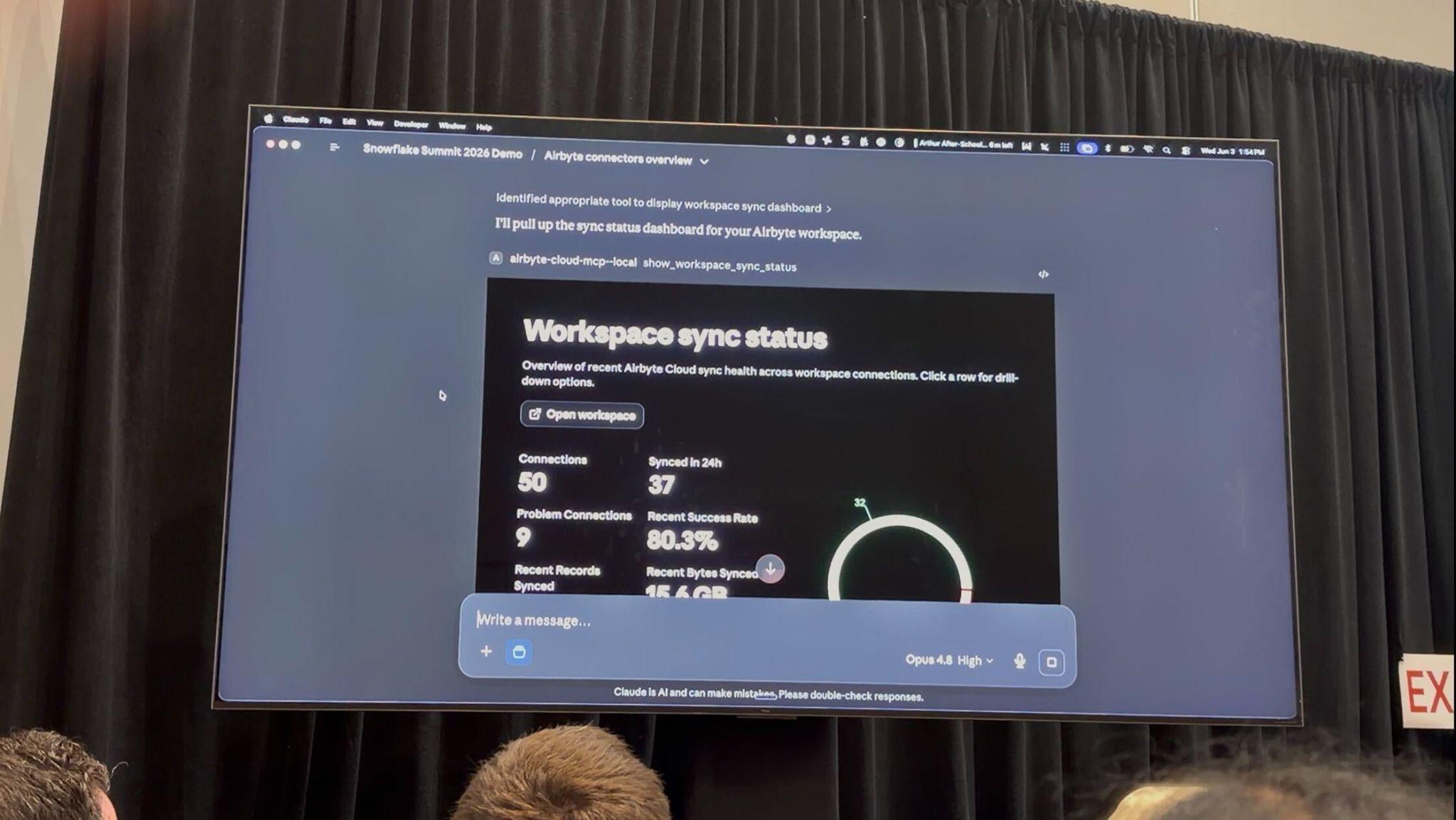
生成AIを使う際、チャットに文字が延々と流れ続け、気づけば人間の処理能力を超える情報量に埋もれてしまった――そんな経験は、皆さんにもあるのではないでしょうか。このデモが示したのは、その答えのひとつです。結果はUIとして一目で見渡せ、続きの操作は画面から直接行い、さらにツール側には「人間の承認の証跡がなければ実行できない」設計を仕込める。文字の洪水を読み解く作業が、見て、触って、確かめる体験に置き換わっていく感覚があり、エージェント時代のデータ活用支援を考えるうえで、私たちにとっても大きなヒントをもらったセッションでした。
データカタログを手がけるAtlanの共同創業者、Prukalpa Sankar氏らによるセッションです。冒頭で示されたのは、多くの組織が一度は通る道でした。気合いの入ったシステムプロンプトとセマンティックモデルで分析エージェントを作り、「売上はいくら?」には見事に答える。ところが現場に展開した途端、「なぜ今週はドライブスルーの待ち時間が悪化したのか」といった”なぜ”の質問で立ち往生してしまう――。
一方、社内最高のアナリストが持つ知識をコンテキストとして備えたエージェントは違います。ここでいうコンテキストとは、たとえば次のようなものです。
これらを携えたエージェントは、「ダブルパティバーガーの提供で13秒長くかかり、影響はシングルレーン店舗に限られ、週11,000〜14,000ドルの機会損失が出ている」という、打ち手につながる答えまで返せる。この対比が、セッション全体の出発点でした。
そのうえで紹介されたのが、こうしたコンテキストを「コンテキストリポジトリ」として束ね、ライフサイクルで管理する考え方です。構築には、ある顧客で5ヶ月を要したという生々しい話もありました。エッジケースを潰しては新たなエッジケースが顔を出す、終わりの見えない作業。これに対しデモで示されたのは、エージェントと人間が役割分担しながらリポジトリを育てる、次のような一連の流れです。
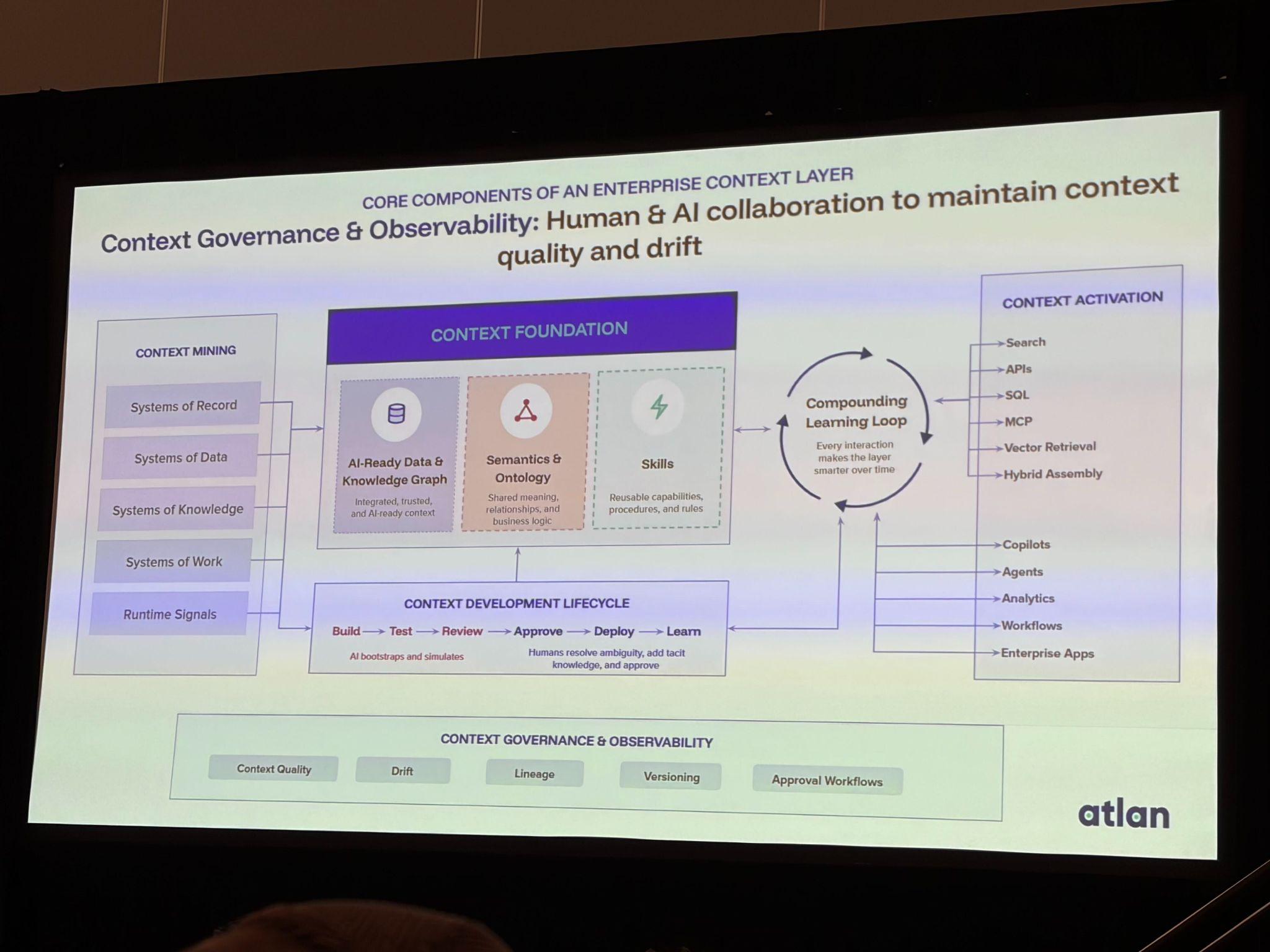
本記事でも繰り返し触れてきたコンテキストエンジニアリングですが、我々にとって新鮮だったのは、コンテキストを個人のプロンプト術ではなく、リポジトリで管理し、テストし、デプロイする「プロダクト」として扱うという発想です。同じ指標なのに部署によって数字が合わない、エージェントを作るたびに同じ業務知識をゼロから教え直している――そんな経験をお持ちの方も多いのではないでしょうか。個人の頭の中やプロンプトの断片に散らばっていた業務知識を、組織の資産として一箇所に集め、版を重ねて育てていく。Sankar氏の「Context is your IP(コンテキストこそが知的財産)」というメッセージは、これからのAI活用のあり方を考えるうえで痺れる一言でした。
AIエージェントを全社規模で本番稼働させるための具体的な青写真を示したのが、Booking.comの本セッションです。彼らは、ビジネス部門からのデータ照会に対する回答時間を「数日」から「数秒」へと劇的に短縮し、意思決定と製品の市場投入スピードを飛躍的に向上させました。しかし、真に注目すべきはその圧倒的なROIを生み出した裏側の運用設計と泥臭いチューニングにあります。
全社展開にあたり、同社はエンドユーザーとデータ専門家のペルソナを明確に分離しました。開発環境で構築されたセマンティックビューは、マージリクエストをトリガーとした自動CI/CDパイプラインを経て本番環境へデプロイされ、エンタープライズの厳格なガバナンスとガードレールを担保しています。さらに、エージェントの回答精度を維持するため、監査ログを定常的に監視し、カスタム指示や検証済みクエリを反復的に改善し続けるという、データサイエンスの基本に忠実なアプローチがとられていました。 また、単一のテキストベースの応答から脱却するため、Cortex Analystからマルチモーダル対応のSnowflake Intelligenceへと移行し、可視化や外部ツール連携(MCP)の自由度を獲得しています。今後はCortex Knowledge Extension(CKE)を用いた外部データの統合や、Cortex Snap Searchによるウェブ検索への拡張も視野に入れているとのことです。
この「ガバナンスとアジリティの両立」および「ログドリブンな継続的精度改善」は、日本の大企業がAIを本番実装する上で必ず直面する壁に対する完璧なアンサーです。このベストプラクティスをベースラインとし、さらに自社独自のナレッジグラフや外部LLMをMCP経由で高度にオーケストレーションすることで、日本企業の複雑な業務ドメインに特化した「真のAgentic Enterprise」の実装が推進されます。
ブレインパッドは今回、経営層から2名(西村COO・富樫執行役員)が現地入りし、一般には公開されないエグゼクティブ限定セッション(『How to Scale AI in the Enterprise』や『The C-Suite AI Mandate』など)に参加しました。
そこでグローバルのトップリーダーたちが議論していたのは、技術の進化そのものではなく、AIを本番実装する上で立ちはだかる「人と組織」「ガバナンス」の壁でした。全体のメッセージを3つに凝縮してお伝えします。
日本企業はどのように「Agentic Enterprise」へと舵を切るべきか――。
2026年7月9日(木)開催の「Snowflake Summit 2026 Recapイベント」では、本トピックについて弊社COOの西村よりさらに深く解説し、日本のエンタープライズ経営層がいま取り組むべき具体的なアクションをお伝えします。
この度、ブレインパッドでは「Snowflake Summit 2026」の最新情報をもとにしたRecapセミナー【BrainPad × Snowflake】Snowflake Summit 2026 Recap -AI Data Cloud のビジネス実装ロードマップ-を開催する運びとなりました。
当日は、Snowflake社による最新技術の総括に加え、弊社からは経営層・データサイエンティストの視点からSnowflake Summit 2026のテーマである「Making AI Real」を実現するために経営陣が下すべき投資判断や実装アプローチを解説します。
ブレインパッドオフィスにてオフライン開催となります。当日はセミナーに加え、軽食を交えた懇親会(ネットワーキング)もご用意しております。個別のご相談や情報交換の場としてぜひご活用ください。
■ 開催概要
【BrainPad × Snowflake】Snowflake Summit 2026 Recap -AI Data Cloud のビジネス実装ロードマップ-
| 日時 | 2026年7月9日(木)18:00 – 20:30(受付開始 17:30) |
| 場所 | ブレインパッド本社: 東京都港区六本木三丁目1番1号 六本木ティーキューブ(総合受付:11階) |
| 費用 | 無料(事前登録制) |
| アジェンダ | 第1部 セミナー:18:00 ~ 19:30 ・Snowflake Summit 2026 ハイライト (Snowflake合同会社 シニアパートナーソリューションエンジニア 髙橋 達矢氏) ・【経営層向けセッション】AI Data Cloudの現在地と業務実装の留意点 (ブレインパッド 副社長執行役員 COO 西村 順 ) ・【インダストリーカットセッション】各インダストリーでの「Agentic AI」の成功法 (ブレインパッド 執行役員 セールス&マーケティング担当 富樫 尚人 ) ・【技術セッション】ブレインパッド目線でのSummit発表の注目新機能 (ブレインパッド 中道・木村) 第2部 懇親会 :19:30 ~ 20:30 |
※当日の内容は変更になる場合がございます。あらかじめご了承ください。
■ お申し込み方法
ブレインパッドセミナー事務局宛にメールにてご参加者様の会社名・氏名・お役職・メールアドレスをご連絡ください。
e-mail:event@brainpad.co.jp
※申し込み順の関係により定員を超えた場合はお断りさせて頂く場合がございます。あらかじめご了承ください。
ブレインパッドとしては今回で3年目のサミット参加となりますが、4名が初参加でした。とはいえ、入念な事前準備でしっかり学び楽しむことができたので、どんな準備をしたのか、期間中はどう動いたのかを簡単に紹介します。
Snowflakeはユーザーコミュニティが活発でサミットも複数年参加のスペシャリストが多数います。事前にSnowflake社主催の案内イベントとユーザーコミュニティ主催のイベントがあるので、逃さず参加しました。これらに参加することで会場での立ち回り方や、どのセッションに注力すべきかという現地の過ごし方を鮮明にイメージすることができました。 また、ユーザーコミュニティ主催の事前イベントでは、サミットの参加者と事前にネットワーキングをすることができるので、現地で話せる人も増え、行ってよかったイベントです。
また、現地で各メンバーがどのように動くのかのスケジュールも事前にすり合わせることで、無駄のない情報収集とネットワーキングを可能にしました。
私個人の英語力といえば、「読解はできるもののスピーキングは苦手。リスニングも集中していれば理解できるが、30分のセッションを通しで聞くとどうしても聞き逃しが発生する」という、典型的な日本式の学習にとどまっています。
そんな私の頼れる相棒となったのが、4つの翻訳・文字起こしツールです。現地ではこれらを組み合わせて活用し、セッションもブース周りの情報収集も乗り切ることができました。
ブレインパッドは今回、職種の異なる5名それぞれが各自の視点でSnowflakeビジネスに関する洞察を持ち帰ることを目的に参加しました。
ブレインパッドが今回のSnowflake Summit 2026に挑む理由はこちら
サミット中はKeynoteを一緒に見て、各自の視点からディスカッションを深めた後は、日中のセッションでインプットを行うだけでなく、Snowflake社主催の数々のイベントやお客様との直接の情報交換、さらには他パートナー企業様が主催する交流会にも積極的に参加しました。世界中のデータに熱狂する人々と国や立場を越えて語り合うことができ、非常に楽しく、実りの多いネットワーキングの機会となりました。自社だけ、国内だけにとどまらない魅力がSnowflake Summitにはあふれており、今後もブレインパッドはSnowflakeの技術にとどまらない魅力も発信していきます。
4日間にわたる「Snowflake Summit 2026」を、速報と総まとめの形でお届けしてきました。昨年の「Simplicity」がAIを”試しやすくする”宣言だったとすれば、今年の「Making AI Real for Business」は、試行を本番業務の成果へ変える段階に入ったことを告げる合図でした。勝負所はモデルの性能比べから、コンテキストとガバナンス、それを支える組織の文化へと移っています。
そして、コンテキストは一晩では貯まりません。商談を録音する、図に埋めていた数字をテーブルでためる、磨いた型をカタログに載せる——地味な習慣の積み重ねが、後からじわじわ効いてくる。モデルが同質化していく時代に最後まで残る差は、そうして積み上がった企業のIPです。皆さんの組織では、明日からのどの一歩が「Real」への入り口になるでしょうか。
ブレインパッドはこれからも、データとAIのビジネス実装を技術と組織文化の両面から支えてまいります。最後までお読みいただき、ありがとうございました。
あなたにオススメの記事

2023.12.01
生成AI(ジェネレーティブAI)とは?ChatGPTとの違いや仕組み・種類・活用事例

2023.09.21
DX(デジタルトランスフォーメーション)とは?今さら聞けない意味・定義を分かりやすく解説【2024年最新】

2023.11.24
【現役社員が解説】データサイエンティストとは?仕事内容やAI・DX時代に必要なスキル

2023.09.08
DX事例26選:6つの業界別に紹介~有名企業はどんなDXをやっている?~【2024年最新版】

2023.08.23
LLM(大規模言語モデル)とは?生成AIとの違いや活用事例・課題

2024.03.22
生成AIの評価指標・ベンチマークとそれらに関連する問題点や限界を解説
















