



メルマガ登録
-
テーマから探す
-
技術から探す
-
業界・事例から探す
-
関連トレンドから探す
テーマから探す
技術から探す
業界・事例から探す
関連トレンドから探す

こんにちは。データサイエンティストの伊藤です。分析案件にアドバイザーとして関わりつつ、最新技術の調査や検証に取り組んでいます。
昨今、生成AIをはじめとするAI技術の進化は目覚ましく、レコメンデーション(推薦)の分野でも、ディープラーニングを活用した新たなアルゴリズムが次々と論文発表されています。
「最新のAIを使えば、売上はもっと上がるのではないか?」 「10年前からあるロジックなんて、もう時代遅れではないか?」
そんな疑問を持つマーケティング担当者やエンジニアの方も多いのではないでしょうか。
そこで今回、ブレインパッドのデータサイエンティスト・エンジニアチームが、自社プロダクト「Rtoaster(アールトースター)」に搭載されている定番のレコメンドロジックと、論文レベルの最新AI手法を真っ向から比較検証をしてみました。今回の性能評価においては、レコメンド結果の定量的な評価に加え、実運用における機能性、パフォーマンス(処理速度、応答時間)、コスト(導入・運用費)といった多角的な観点からも評価を実施しています。
その結果見えてきたのは、「最新こそ最強」とは限らない、ビジネス実装におけるリアルな現実でした。
今回の記事では評価結果とともに、今後の機能改善やパーソナライズに特化した最新レコメンド手法との組み合わせなど、Rtoasterレコメンドの将来的な展望についても考察します。
本題に入る前に、今回の検証のホスト役である「Rtoaster」について簡単に触れておきます。Rtoasterとは、ブレインパッドが提供する、データを戦略的に活用できる自動接客プラットフォーム。独自のアルゴリズムで、Webやアプリ上で顧客一人ひとりにあわせた最適な体験を提供するサービスです。
そのRtoasterの中核機能の1つが、今回スポットライトを当てる「レコメンド機能」です。Rtoasterのレコメンド機能※1は、グラフ理論に基づく協調フィルタリング手法として2008年に誕生して以来、多くの企業のマーケティングを裏側で支える実績のあるエンジンとして改良を重ね、現在も利用されています。
協調フィルタリング※2は、あるユーザーと購買傾向が類似している他ユーザーの購買情報をもとに、商品アイテムをランキングして当該ユーザーに推奨する仕組みです。ユーザー間の協調信号をもとに推奨アイテムをスコアリングする点で、個人の嗜好性に特化したアイテムを推奨する最新のパーソナライズドレコメンド手法とは対照的なアプローチをとります。後者の手法はパーソナライズに特化することで、フィルターバブル※3といった問題を引き起こす可能性があります。一方、協調フィルタリング手法は、複数ユーザーの協調信号を介してレコメンド内容を決定するため、工夫次第でフィルターバブルを緩和できる可能性があります。
※1 矢島 安敏、矢田佳久「ラブラシアンカーネルを用いた One-Class SVMとそのマーケティングへの応用」オペレーションズ・リサーチ 第51巻 2006年、pp. 689 – 695.
※2 協調フィルタリング、メモリベース法、モデルベース法の解説:
風間 正弘、飯塚 洸二郎、松村 優也「推薦システム実践入門―仕事で使える導入ガイド」オライリージャパン、2022年05月
※3 インターネット利用者が、自分の考え方や関心に近い情報ばかりを目にするようになり、反対の意見や異なる趣味の情報に触れにくくなる現象を指す。詳しくは、以下を参照。
フィルターバブル:Wikipedia の解説 https://ja.wikipedia.org/wiki/フィルターバブル
解説ブログ https://data.wingarc.com/ted-filter-bubble-11420#3
https://www.kaonavi.jp/dictionary/filter-bubble/
検証結果の前に、協調フィルタリングの基本原理について解説します。
例としてECサイトの場合を考えてみましょう。このECサイトにおいて購買実績のあるユーザーに対し、次に購買する可能性の高い順に商品(アイテム)を推奨(レコメンド)することが課題となります。ここで「購買傾向が似ているユーザーはその嗜好も似ている」と考えるのは自然なことです。この仮説に基づき、ユーザーAに対し、ユーザーAと購買アイテムが似ている他のユーザーが購買しているアイテムを推奨すれば、高い確率で購買すると想定できます(図1参照)。このように、複数ユーザーの購買行動の協調性に基づき、あるユーザーにレコメンドするアイテムを決定する手法を協調フィルタリングと総称します。
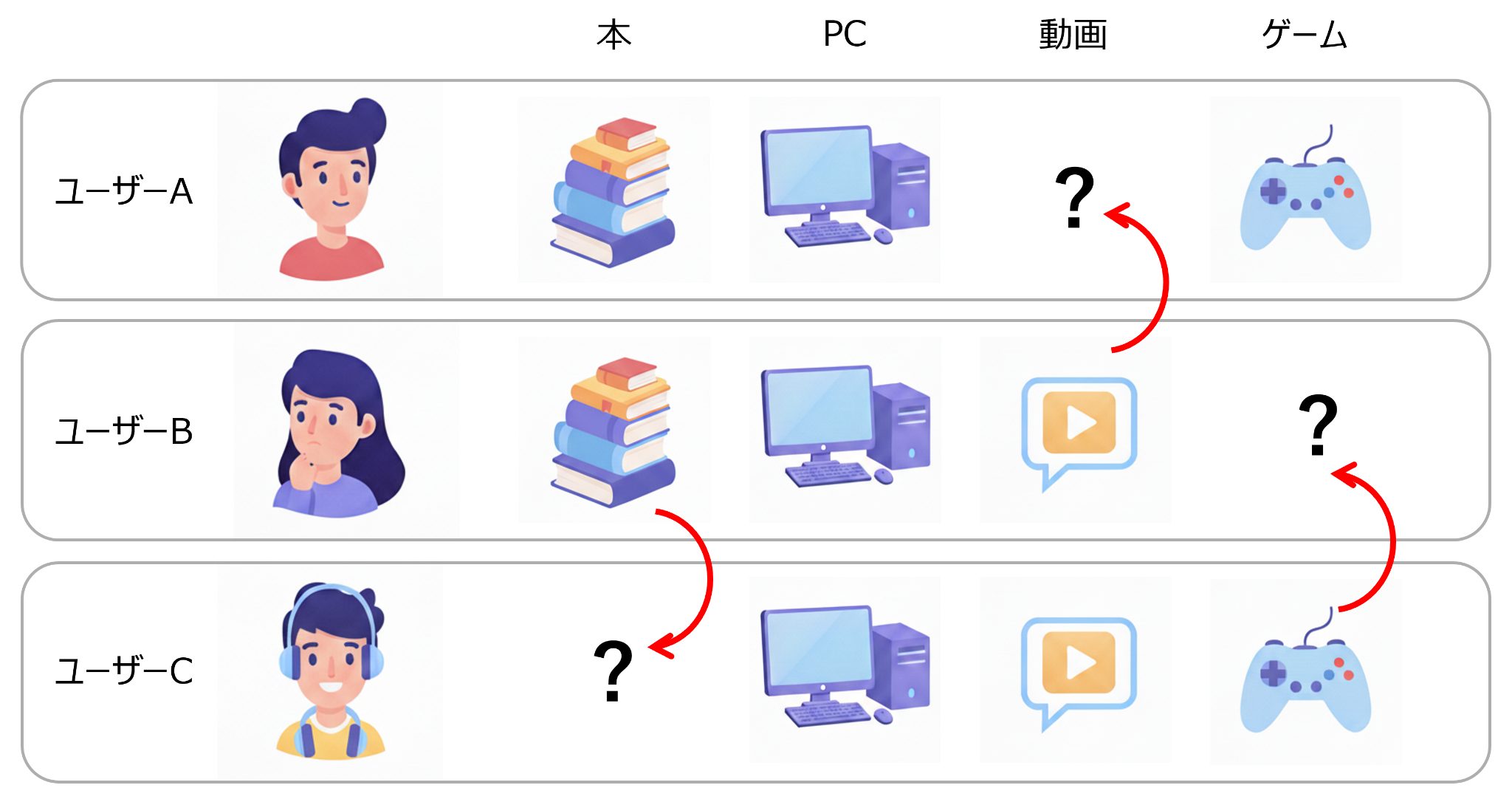
推薦システムの運用においては、ユーザーごとにレコメンドするアイテムを一つだけ決定するのではなく、購買確率の高い順にアイテムを並べたリスト(レコメンドリスト)を出力します。推薦システムのレコメンド性能は、レコメンドリストの上位 K 個(K = 5, 10, 20 など)に含まれる購買アイテム数で定義されるランキング指標によって評価できます(詳しくは、「評価指標」のパートで説明します)。
協調フィルタリングでは、ユーザー間の類似性はユーザーの購買アイテムによって特徴付けられます。つまり、ユーザー間の関係性は、ユーザーとアイテムの関係性から二次的に決定されます。そこで、ユーザーがあるアイテムを購買するという事象をユーザーとアイテムの相互作用として定義すると、ユーザーの購買履歴データはユーザー・アイテム行列として定量化できます(図2参照)。この行列の i 行 j 列成分の値は、i 番目のユーザーが j 番目のアイテムを購入したことがあれば 1、なければ 0 となります。
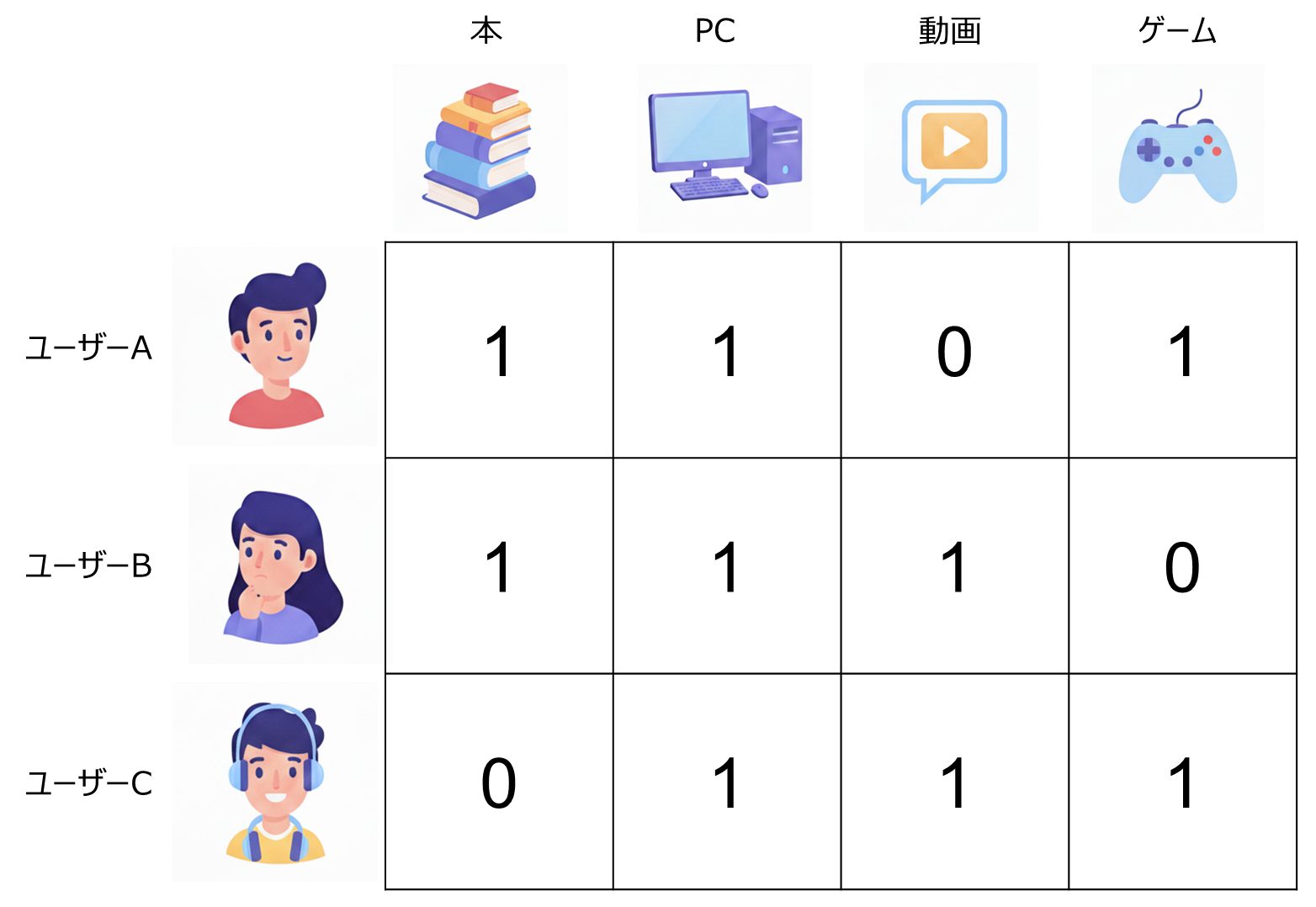
図2. ユーザー・アイテム相互作用行列
ユーザーとアイテムを種類の異なる「頂点」とし、ユーザーとアイテムの相互作用を、ユーザーとアイテムの各頂点を繋ぐ「辺」とみなせば、ユーザー・アイテム行列を「グラフ」として解釈できます。このグラフは、異種頂点を結ぶ辺しか存在しない2部グラフとなります(図3参照)。ユーザー・アイテム行列は隣り合う頂点の接続関係を表すため、グラフ理論では隣接行列と呼ばれます。
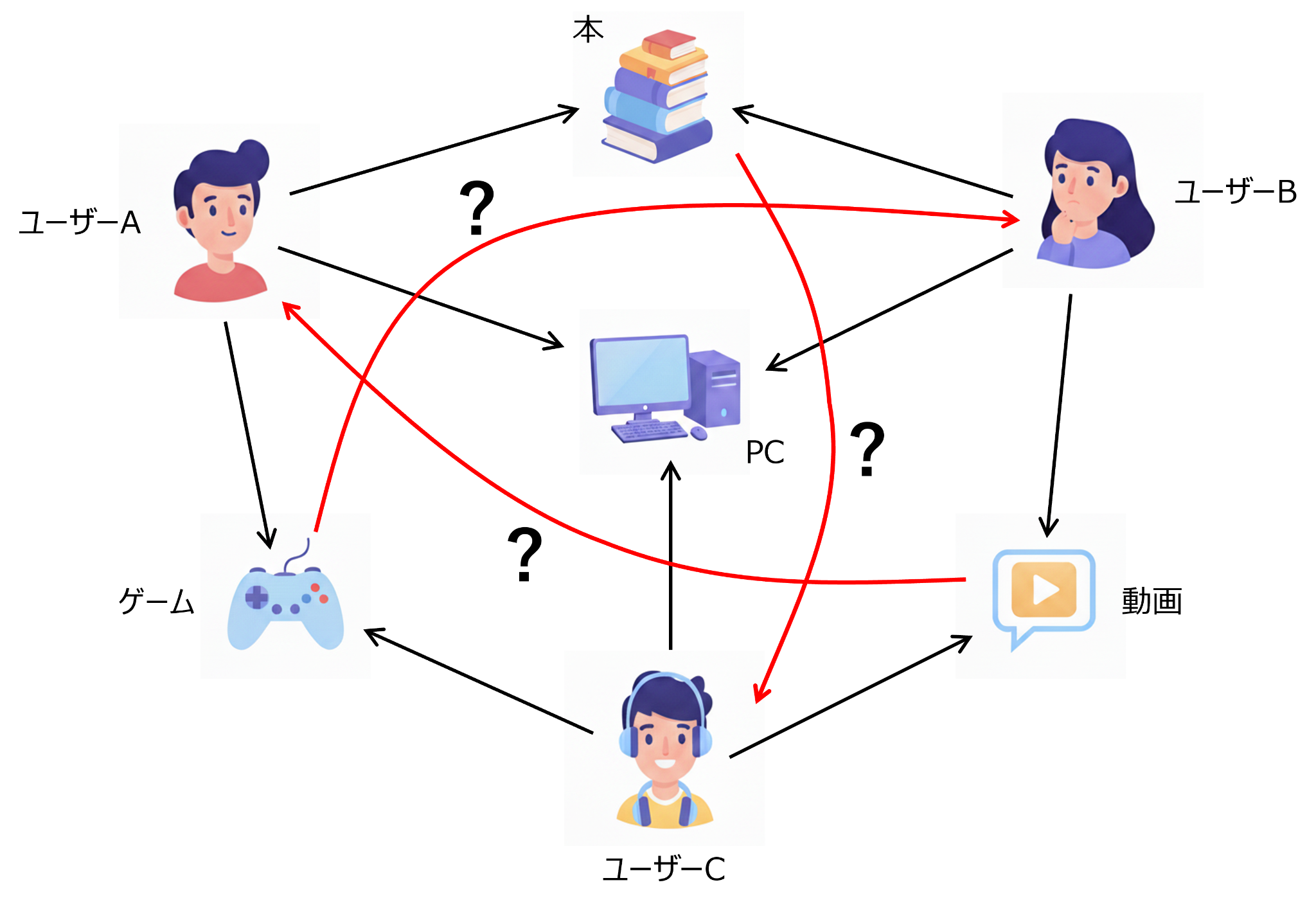
具体例を見てみましょう。例えば、ユーザーAとユーザーBがともにアイテムX(映画「タイタニック」)を視聴したことがあれば、アイテムXを介してユーザーAとユーザーBが繋がり、協調信号が伝達されます。この場合、ユーザーAは視聴していないが、ユーザーBが視聴したことがあるアイテムY(映画「ポセイドン・アドベンチャー」)をユーザーAにレコメンドします。協調フィルタリングの原理は上述の通りですが、グラフ(あるいは行列)をどのように扱うかによって、様々なアルゴリズムが考えられます。
協調フィルタリングによるレコメンド手法としては、ユーザー間の協調性をどのように評価するかによって、様々なアルゴリズムが考えられます。本稿では、ユーザー・アイテム行列(またはグラフ)の扱い方の違いにより、以下の3つのタイプを考えます。
タイプ(1)は、グラフの隣接行列(ユーザー・アイテム行列)のべき乗計算を高次にわたって実行して得られる行列の成分値に従ってアイテムをレコメンドする手法です。その時点の購買データの蓄積(メモリ)があれば、何らかの機械学習モデルを学習することなくレコメンドスコアを計算できます。メモリベース法とも呼ばれます。ちなみにRtoasterの協調フィルタリングは、この手法を採用しています。
タイプ(2)は、グラフ情報を頂点の特徴ベクトルとして集約(次元圧縮)する手法です。行列分解による手法とグラフニューラルネットワーク(Graph Neural Network, GNN)による手法があります。行列分解は、ユーザー・アイテム行列を、ユーザー特徴量を行として並べた行列Pとアイテム特徴量を列として並べた行列Qの積に分解します。ユーザー特徴量とアイテム特徴量の次元kは、モデルのハイパーパラメータとして任意に選択できます。行列分解として定評のあるアルゴリズムとしてiALS (implicit Alternating Least Square) ※4が知られています。
※4 Yifan Hu, Yehuda Koren and Chris Volinsky, “Collaborative Filtering for Implicit Feedback Datasets,” in 2008 Eighth IEEE International Conference on Data Mining, Pisa, Italy, 2008, pp. 263 – 272.
一方、グラフニューラルネットワークでは、グラフの辺を介した頂点への情報伝達をニューラルネットワークによって集約し、頂点の特徴量を計算します。例えば、グラフ畳み込みネットワーク(Graph Convolutional Network, GCN)では、グラフの各頂点に隣接する頂点の特徴量を重み付け平均することで、その頂点の特徴量を計算します。これを何層も繰り返すことで、グラフ構造を学習します。グラフ畳み込みネットワークの実装例として LightGCN※5が知られています。
※5 Xiangnan He, Kuan Deng, Xiang Wang, Yan Li, Yongdong Zhang and Meng Wang, “LightGCN: Simplifying and Powering Graph Convolution Network for Recommendation,” in SIGIR ’20: Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, 2020, pp. 639 – 648. arXiv:2002.02126
タイプ(3)は、グラフ構造の確率分布を学習する生成モデルによる手法です。画像生成で成功を収めたデノイジング拡散確率モデル(拡散モデル)を適用した手法として、DiffRec (Diffusion Recommender model) ※6が知られています。拡散モデルによるアプローチでは、グラフ構造にガウスノイズを段階的に加えて破壊します(拡散過程)。このプロセスを逆にたどってノイズ除去を繰り返し、元のグラフ構造を復元する過程をニューラルネットワークで学習します(生成過程)。
※6 Wenjie Wang, Yiyan Xu, Fuli Feng, Xinyu Lin, Xiangnan He and Tat-Seng Chua, “Diffusion Recommender Model,” in SIGIR ’23: Proceedings of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval, 2023, pp. 832 – 841. arXiv:2304.04971
タイプ(2)および(3)はともに、過去の購買データをもとに機械学習モデルを学習し、新しいデータに適用してレコメンドアイテムを推定するため、モデルベース法と呼ばれます。
今回の検証では、タイプ(1)のメモリベース法であるRtoasterのレコメンドと、近年のトップカンファレンスや論文で注目を集める手法の中から、モデルベース法としてタイプ(2)の iALS、LightGCN、タイプ(3)の DiffRecを採用し、性能比較を行いました。
今回の検証では、データセットとしてレコメンド性能評価で広く使用されている公開データを使用しました。Netflix などの動画配信サイトを想定した MovieLens-32M※7と EC サイトを想定した Amazon Books※8の2種類です。データの前処理として、(1)所定の条件によってフィルタリングを行い、(2)データをタイムスタンプをもとに時系列順に並べ、日付によって訓練 (training)・検証 (validation)・テスト (test) に分割しました。
※7 MovieLens 32M: https://grouplens.org/datasets/movielens/32m/
※8 Amazon Books: https://jmcauley.ucsd.edu/data/amazon/
上記(1)の所定の条件とは、以下の3つの条件です。
上記(2)のデータ分割においては、訓練、検証、テストの比率が 7 : 1 : 2 になるように分割しました。ユーザー群は一貫して共通しています。前処理後の各データの統計情報を以下に示します。
| 用途 | ユーザー数 | アイテム数 | 相互作用関数 | 充填率 (%) | データ期間 |
|---|---|---|---|---|---|
| 訓練 | 2,295 | 19,058 | 262,982 | 0.601 | 2017-01-01 ~ 2019-01-02 |
| 検証 | 2,295 | 6,872 | 26,349 | 0.167 | 2019-01-02 ~ 2019-04-14 |
| テスト | 2,295 | 10,055 | 38,950 | 0.161 | 2019-04-14 ~ 2019-12-31 |
訓練、検証、テストそれぞれの充填率は 0.601%、0.167%、0.161%であり、後述する Amazon Books データセットと比べて高い値となっています。ユーザーあたりの購買回数が比較的多く、モデル学習の難易度は低いため、アルゴリズムによる性能差は小さいと推測されます。
| 用途 | ユーザー数 | アイテム数 | 相互作用関数 | 充填率 (%) | データ期間 |
|---|---|---|---|---|---|
| 訓練 | 21,756 | 177,908 | 376,926 | 0.00974 | 2017-01-01 ~ 2019-01-03 |
| 検証 | 21,756 | 50,923 | 91,314 | 0.00824 | 2019-01-03 ~ 2019-04-26 |
| テスト | 21,756 | 78,114 | 149,495 | 0.00880 | 2019-04-26 ~ 2019-12-31 |
このデータセットは、訓練、検証、テストそれぞれの充填率が 0.00534%、0.00453%、 0.00484%であり、前述の MovieLens-32M の20分の1以下と非常にスパースなデータであることが分かります。ユーザーあたりの購買回数が比較的少なく、モデル学習の難易度は高いため、アルゴリズムによる性能差は大きいと推測されます。
レコメンド性能は、レコメンドリストにおけるアイテムの並び順(ランキング)の良し悪しによって評価されます。そこで、ランキングを定量的に評価する指標(ランキング指標)を定義する必要があります。ランキング指標は、レコメンドの上位K個までに含まれる適合アイテム(ユーザーが実際に購入したアイテム)の順位や割合によって定義されます。ここでは、今回の検証で使用するランキング指標の定義と意味について説明します。
ランキング指標を定義するために、以下の2つの関数を導入します。
| 関数名 | 定義式 |
|---|---|
| Hit(u, i) | ユーザー u のランキング i 番目のアイテムが適合アイテムなら 1、それ以外は 0 となる関数。適合アイテムとは、ユーザー u が実際に購入したアイテムのこと。 |
| GT(u) | ユーザー u の適合アイテム数のこと。GT(u) = Σi Hit(u, i) が成り立つ。 |
上記の関数を使って以下の 4つのランキング指標を定義できます※9※10。
| 指標 | 定義式 |
|---|---|
| Recall@K | R(u, K) = Σ1≦i≦KHit(u, i) / GT(u) ⇒ Recall@K = Σ1≦u≦N R(u, K) / N |
| Precision@K | P(u, K) = Σ1≦i≦KHit(u, i) / K ⇒ Precision@K = Σ1≦u≦N P(u, K) / N |
| MRR@K | RR(u, K) = 1 / min1≦i≦K{ i s.t Hit(u, i) = 1 } ⇒ MRR@K = Σ1≦u≦N RR(u, K) / N |
| NDCG@K | DCG(u, K) = Σ1≦i≦K (2Hit(u, i) -1) wi, wi = 1 / log2(i + 1)IDCG(u, K) = Σ1≦i≦K(u) wi, K(u) = min{ K, GT(u) }NDCG(u, K) = DCG(u, K) / IDCG(u, K) ⇒ NDCG@K = Σ1≦u≦N NDCG(u, K) / N |
上記のランキング指標の意味は以下の通りです。
Top-Kアイテムとは、ランキング上位Kに含まれるアイテムのことです。このうち、実際にユーザーに購買されたアイテムをTop-K適合アイテムと定義します。Top-K累積適合スコアとは、ランキング上位Kのi番目のアイテムが適合アイテムなら wi = 1 / log2(i + 1) を加点して得られる累積スコアのことです。これを上限値で割って正規化した値を全ユーザーで平均した指標がNDCG@Kです。
これらのランキング指標に加え、レコメンド結果の多様性を評価する指標として、カタログカバレッジ (Catalog Coverage, CC) が知られています※9。この指標は、レコメンドされたTop-Kアイテムの総数がアイテム総数に占める割合として定義されます。さらに、カタログカバレッジを適合アイテムに限定して定義した適合カタログカバレッジ (Weighted Catalog Coverage, WCC) も評価指標として用いられます。この指標が高いほど、レコメンド結果が幅広いアイテムを的確にレコメンドしていることを意味します。
今回の検証では、評価指標として、K = 20に固定したランキング指標(Recall@20、Precision@20、MRR@20、NDCG@20)およびカバレッジ指標(CC@20、WCC@20) を採用します。
※9 ランキング指標・カバレッジ指標の解説:レコメンドつれづれ ~第3回 レコメンド精度の評価方法を学ぶ~
※10 ランキング指標の解説:レコメンド指標の整理: Recall@k・MRR・MAP・nDCG
レコメンドを実際にビジネスで使うには、「早さ」と「安さ(計算リソースコスト)」の観点も不可欠です(例えば「1%の精度向上」に「10倍のコスト」を払えるか?といった検討が必要となります)。今回の検証では、同じ環境下で処理にかかる時間を計測し、コストについての評価も行いました。
モデルのハイパーパラメータは、Optuna※11による20回の探索において、検証データにおける Recall@20 が最大となる値をベストモデルとして決定しました。ベストモデルは、訓練データによる再学習(上限100エポック)を行い、テストデータに適用して各種ランキング指標を算出しました。ランキング指標のテストデータにおける推定誤差を見積もるため、ブートストラップ法によるサンプリングを100回実施し、推定値の標準偏差を評価しました。さらに、ランキング指標値のRtoasterと他手法との差が有意であるかをt検定により評価しました。以下に、MovieLens-32MとAmazon Booksにおける検証結果を示します。
※11 Optuna: ハイパーパラメータ最適化フレームワーク: https://docs-ja.optuna.org/
https://github.com/optuna/optuna
| モデル | Recall@20 | Precision@20 | MRR@20 | NDCG@20 |
|---|---|---|---|---|
| Rtoaster | 0.0414 ± 0.0019 | 0.0291 ± 0.0012 | 0.1030 ± 0.0052 | 0.0430 ± 0.0018 |
| DiffRec | 0.0497 ± 0.0021 | 0.0355 ± 0.0018 | 0.1141 ± 0.0053 | 0.0514 ± 0.0023 |
| LightGCN | 0.0337 ± 0.0018 | 0.0221 ± 0.0009 | 0.0789 ± 0.0041 | 0.0329 ± 0.0015 |
| iALS | 0.0277 ± 0.0017 | 0.0183 ± 0.0010 | 0.0583 ± 0.0035 | 0.0256 ± 0.0014 |
ランキング指標によらず、DiffRecが最も指標値が高く、Rtoasterがそれに続く結果となっています。LightGCNは、グラフ畳み込みを使って頂点への情報伝達を行いますが、メモリベースのRtoasterによる隣接行列の高次計算には及ばなかったようです。行列分解としては定評のあるiALSは、最も低い指標値となってしまいました。
MovieLens-32Mは、「データセット」の章でみたようにユーザー1人あたりの購買回数が比較的多く充填率が高いため、LightGCNは100エポックでは学習しきれなかった可能性があります。モデル学習を介さないメモリベース法であるタイプ(1)のRtoasterが、頂点への埋め込みによる情報集約を介するタイプ(2)よりも有利であったと思われます。タイプ(3)のDiffRecが高性能なのは、グラフの埋め込みによる情報集約を介さず、グラフ構造の確率分布を直接学習しているためと考えられます。
なお、Rtoasterと他手法とのランキング指標値の差は、t検定の結果、信頼度95% (p < .05) において有意でした。
| モデル | Rtoaster | DiffRec | LightGCN | iALS |
| CC@20 (%) | 5.25 | 4.55 | 1.88 | 7.05 |
| WCC@20 (%) | 1.42 | 3.48 | 0.81 | 2.70 |
CC@20は、iALSが7.05%と最も高く、次いでRtoasterの5.25%が続きます。ただし、レコメンドの多様性だけでなく的確さも考慮した場合、DiffRecが3.48%と最も高く、次いで iALSの2.70%が続きます。MovieLens-32Mのように比較的に相互作用が密なデータでは、レコメンド結果の多様性においてグラフの連結関係を行列として直接扱うiALSおよびRtoasterが有利のようです。しかし、レコメンド結果の的確さも考慮した場合、ランキング指標の性能が高いDiffRecが有利になると考えられます。
| モデル | 処理時間 (秒) | 計算コスト (US$) | 時間あたりコスト (US$ / 時間) | 計算リソース |
|---|---|---|---|---|
| Rtoaster | 19 | 0.0032 | 0.607 | CPU |
| DiffRec | 72 | 0.0173 | 0.863 | CPU + GPU |
| LightGCN | 1,625 | 0.3895 | 0.863 | CPU + GPU |
| iALS | 10 | 0.0016 | 0.607 | CPU |
処理時間での比較では、iALSの10秒が最短であり、次いでメモリベース法のRtoasterの19秒が続きます。 MovieLens-32Mは、相互作用密度が比較的に高いデータであるため、Rtosterの隣接行列の高次計算よりも、行列分解によるiALSのほうが処理時間で有利であると考えられます。一方、ニューラルネットワークを使用しているDiffRecおよびLightGCNは処理時間では不利になります。しかし、LightGCNが1,625秒とRtoasterの80倍であるのに対して、DiffRecは72秒と3.5倍に収まっています。これは、DiffRecのニューラルネットワーク構成が、LightGCNに比べて単純な構成であることによります。ただし、GPUの利用料がCPU利用料に上乗せされることから、計算コストはDiffRecでもRtoasterの5倍以上となっています。
| モデル | Recall@20 | Precision@20 | MRR@20 | NDCG@20 |
|---|---|---|---|---|
| Rtoaster | 0.00635 ± 0.00041 | 0.00196 ± 0.00011 | 0.00631 ± 0.00042 | 0.00399 ± 0.00024 |
| DiffRec | 0.01441 ± 0.00045 | 0.00414 ± 0.00013 | 0.01635 ± 0.00057 | 0.00968 ± 0.00030 |
| LightGCN | 0.00611 ± 0.00034 | 0.00162 ± 0.00007 | 0.00716 ± 0.00043 | 0.00405 ± 0.00022 |
| iALS | 0.00910 ± 0.00041 | 0.00239 ± 0.00009 | 0.00836 ± 0.00038 | 0.00539 ± 0.00019 |
Amazon Booksは、充填率が低くスパースなデータであるため、レコメンドリストの推定が全般的に難しくなっています。それでもタイプ(3)のDiffRecは、グラフ構造の確率分布を直接推定するので他手法に比べてランキング指標値は1.5倍以上となっています。次いで行列分解を使ったiALSが高性能となっています。グラフ構造がスパースであるため、行列分解による次元圧縮が功を奏したと考えられます。Rtoasterは、iALSには及びませんが、LightGCNよりは良い結果となっています。メモリベースのRtoasterが大規模データでも性能を発揮できたのに対して、LightGCNは学習が十分ではなかった可能性もあります。
なお、RtoasterとLightGCNを除く他手法とのランキング指標値の差は、t検定の結果、信頼度95% (p < .05) において有意でした。RtoasterとLightGCNとの比較においては、Precision@20を除いて有意な差が認められませんでした。
| モデル | Rtoaster | DiffRec | LightGCN | iALS |
| CC@20 (%) | 37.441 | 9.061 | 3.326 | 0.481 |
| WCC@20 (%) | 0.635 | 0.932 | 0.241 | 0.297 |
CC@20は、Rtoasterが37%と最も高く、次いでDiffRecが9%と比較的高い値を示しています。Rtoasterはメモリベース法であり、グラフ情報を次元圧縮せずそのまま使ってレコメンドスコアを計算しているからと推測されます。一方、アイテムを実際に購買された適合アイテムに限定したWCC@20では、DiffRecが0.9%と最も高く、次いでRtoasterの0.6%が続きます。Amazon Booksのようにグラフの辺の分布がスパースな場合、レコメンド結果の多様性だけならグラフ上の情報伝達を直接計算するRtoasterが有利ですが、レコメンド結果の的確さも考慮するとグラフ上の辺の分布を直接推定する DiffRec が有利であると考えられます。
| モデル | 処理時間 (秒) | 計算コスト (US$) | 時間当たりコスト (US$ / 時間) | 計算リソース |
| Rtoaster | 370 | 0.062 | 0.607 | CPU |
| DiffRec | 2,040 | 0.489 | 0.863 | CPU + GPU |
| LightGCN | 4,500 | 1.079 | 0.863 | CPU + GPU |
| iALS | 2,250 | 0.379 | 0.607 | CPU |
Amazon Booksの場合、処理時間・計算コストともにRtoasterが最速・最安です。Amazon BooksはMovieLens-32Mと比べてユーザー数、アイテム数ともに約10倍であり、ユーザー・アイテム行列が巨大になるため、iALSの行列計算でも約2,300秒かかるところ、スパース行列計算に特化したRtoasterでは 370秒と6倍速くなっています。DiffRecは2,040秒とRtoasterに次いで高速ですが、GPU を含めた計算コストは約8倍となっています。
今回、Rtoasterのレコメンド性能を、協調フィルタリングベースの各種アルゴリズムと比較検証しました。検証の観点として、レコメンド結果の正確性・多様性などの性能だけでなく、レコメンド出力のスループット・計算コストなどの効率性も取り上げました。比較した結果、MovieLens-32M、Amazon Booksの両データにおいて、性能面では拡散モデルを採用した最新手法であるDiffRecが最も良い結果でした。Rtoasterは、MovieLens-32Mのような充填率の高いデータにおいては、他手法を抑えて 2番目に良い結果となりました。Amazon Booksのようなスパースなデータでは、Rtoasterは性能面で最新の行列分解法である iALSには及ばないですが、効率性ではiALSを抑えて最も効率の良い結果となりました。以上をまとめると、
性能を重視するならDiffRecが最良のモデルですが、処理時間や計算コストといった効率性を考慮するとRtoasterが最良と考えられます。
レコメンドサービスの運用においては、レコメンド性能だけでなくレコメンドの更新頻度や費用対効果も考慮する必要があります。また、クライアントの要望を考慮したレコメンド結果におけるアイテムの重み付けなど柔軟な対応も求められます。DiffRecは、GPU利用が必須であり、計算コストを抑えつつ、処理時間を短縮することに課題があります。また、新規アイテムや新規ユーザーを取り込むごとに、モデルを一から再学習する必要があるというデメリットもあります。 一方、メモリベース法によるRtoasterのレコメンドは、性能ではDiffRecに及ばないですが、効率性と計算コストでメリットがあるため、レコメンドサービスの費用対効果を考慮すると現実的な選択肢となります。
また余談にはなりますが、今回の検証に参加したエンジニアからは
「Rtoasterが採用しているロジックは、「実用十分な高い精度」と「圧倒的なレスポンス速度・低コスト」のバランスが、現時点でのビジネス最適解であると考えています。これが、私たちが長年このロジックを磨き続けている理由です。もちろん、私たちは「古い手法だけでいい」と考えているわけではありません。今回の検証のように、最新技術のキャッチアップ・検証は常に続けています。現在はコストが見合わない最新技術も、ハードウェアの進化やアルゴリズムの軽量化によって、いずれ実用ラインに乗ってくるでしょう。その時、即座にプロダクトへ実装し、お客様に価値を届けられるよう準備をしておくこと。それが、技術とビジネスの両方を知るブレインパッドの責任だと考えています。」
との感想をもらっています。
近年、ユーザー個人の嗜好に特化したパーソナライズドレコメンドが注目されており、Two-Towerモデル※12など実運用でも取り入れられています。その基本となるアルゴリズムは、ユーザーが相互作用したアイテムの時系列情報から、次に購買する可能性が高いアイテムを予測する系列レコメンド法 (Sequential Recommendation) ※13です。系列レコメンド法には、自然言語モデル由来の各種モデルや、拡散モデルを取り込んだ各種モデルが提唱されています。特に、ニューラルネットワークで学習したユーザー特徴ベクトルとアイテム特徴ベクトルの類似度によってレコメンドスコアを計算するTwo-Towerモデルは、YouTubeを始めとするSNSサービスのパーソナライズドレコメンドの基本アルゴリズムとして実装されています。
※12 Xinyang Yi, Ji Yang, Lichan Hong, Derek Zhiyuan Cheng, Lukasz Heldt, Aditee Kumthekar, Zhe Zhao, Li Wei and Ed Chi, “Sampling-bias-corrected neural modeling for large corpus item recommendations,” in RecSys ’19: Proceedings of the 13th ACM Conference on Recommender Systems, 2019, pp. 269 – 277.
https://storage.googleapis.com/gweb-research2023-media/pubtools/5716.pdf
※13 Wang-Cheng Kang and Julian McAuley, “Self-attentive sequential recommendation,” in 2018 IEEE international conference on data mining (ICDM). IEEE, 2018, pp. 197 – 206. arXiv:1808.09781
冒頭で述べた通り、パーソナライズに特化した高精度のレコメンドは、フィルターバブルによるユーザー間の分断を誘発する負の側面が指摘されています。このような状況下で、集団知を活用した協調フィルタリング手法の重要性が高まっています。今後、系列レコメンド法と協調フィルタリングを相互補完的に改善・活用することにより、ユーザー間の知の共有と融和を促進する推薦システムの開発が期待されます。私たちは、Rtoasterのレコメンドの強みを活かしつつ、Rtoaster GenAIを始めとする生成AI技術を活用し、この社会的問題の解消に寄与するレコメンドアルゴリズムの開発を目指します。

あなたにオススメの記事

2023.12.01
生成AI(ジェネレーティブAI)とは?ChatGPTとの違いや仕組み・種類・活用事例

2023.09.21
DX(デジタルトランスフォーメーション)とは?今さら聞けない意味・定義を分かりやすく解説【2024年最新】

2023.11.24
【現役社員が解説】データサイエンティストとは?仕事内容やAI・DX時代に必要なスキル

2023.09.08
DX事例26選:6つの業界別に紹介~有名企業はどんなDXをやっている?~【2024年最新版】

2023.08.23
LLM(大規模言語モデル)とは?生成AIとの違いや活用事例・課題

2024.03.22
生成AIの評価指標・ベンチマークとそれらに関連する問題点や限界を解説













