



メルマガ登録
-
テーマから探す
-
技術から探す
-
業界・事例から探す
-
関連トレンドから探す
テーマから探す
技術から探す
業界・事例から探す
関連トレンドから探す

生成AIの進歩が目まぐるしいなか、これまでのSaaSに生成AIを組み込んだ機能がリリースされるようになっています。これに伴い生成AIを組み込んだSaaSの品質は、テストの主戦場が「機能」から「生成品質」に移ってきています。ブレインパッドは株式会社ベリサーブの支援のもと、対話型AI検索「Rtoaster GenAI」に向けた品質基準を策定して、製品の品質向上に取り組んでいます。今回の記事では、ベリサーブの執行役員である松木 晋祐氏と、ブレインパッドのエグゼクティブフェローの山崎 清仁が、プロダクトマネージャーやQAエンジニアに向けて、生成AI組み込み型SaaSのテスト段階での評価がなぜ難しく、どのように設計し直すべきかを対談を通してご紹介します。


株式会社ブレインパッド 山崎 清仁(以下、山崎)シリーズでお届けしている『ビジネスを取り巻くAI・DXの現状と未来』の10回目となります。本日は、ベリサーブの松木さんをお招きして、生成AIを組み込んだSaaSの“テスト評価”がどう変わるのかについて、お話ししていきたいと思います。どうぞよろしくお願いします。まずは、松木さんのご紹介からさせてください。松木さんは、株式会社ベリサーブの執行役員であり、研究開発部の責任者として、生成AIの評価・品質保証の取り組みをリードされていて、生成AIの品質基準づくりでも中心的な役割を担われております。
株式会社ベリサーブ 松木 晋祐(以下、松木氏)こちらこそよろしくお願いします。私は株式会社ベリサーブで、主にシステム、ソフトウェアに関する新たな品質保証技術を開発する、研究開発部門を管掌しております。実際のプロジェクトでは現場のメンバーが活躍しましたが、私はベリサーブとして俯瞰的な立ち位置で関わらせていただきました。生成AIの品質は「正しさ」だけでは測れないので、実務で回せる評価の設計をどう作るかにずっと向き合っています。
山崎 本記事ではプロダクトマネージャーやQAエンジニアの目線で、実務面についての話も深掘りできればと思います。
まず、生成AIを組み込んだプロダクトのリスクの整理から入らせてください。生成AIは、ハルシネーション、バイアス、毒性、プロンプトインジェクション、法規制対応など、従来のSaaSでは前提にしなかった品質リスクを抱えています。通常の品質検査で十分なのかという疑問があります。
松木氏 そうですね。だから「仕様通り動くか」だけでは評価しきれないという性質があります。この前提を押さえたうえで、評価軸をどう設計するかが本質的な課題になりますね。
山崎 例えば、Rtoaster GenAIのような生成AI型検索サービスは、曖昧な文脈を対話的に解釈し、検索・レコメンドを行う性質のプロダクトです。従来のキーワード検索では拾いにくい意図を扱うため、出力そのものの品質が体験価値の中心になります。
そこで気になるのが、生成AIを内包するサービス(ここではRtoaster GenAI)を提供する事業者として、品質を保証すべき範囲はどこまでと定義すればよいのでしょうか。
松木氏 確かに、事業者として「どこまでを自分たちが担保すべきか」を明確にする必要があります。ポイントは、事業者がコントロールできる部分を責任範囲として明確化することです。例えば、組み込んだクラウド事業者のLLMそのものをベンチマークすることまでは通常はやりません。
山崎 最初に松木さんに相談した際に、明確にしていただいた次の図のようにレイヤーを明確にして考えるべきということでした。
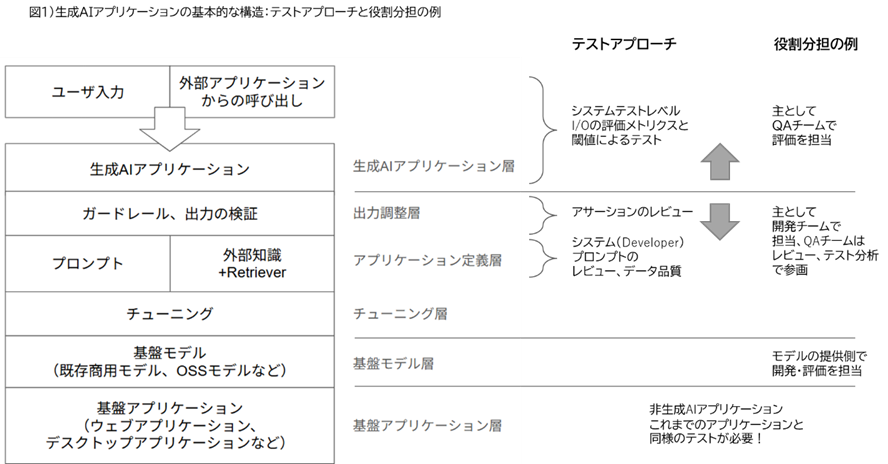
松木氏 はい。つまり「LLMそのものの性能評価」のようなことは除外して、「自社サービスとしての出力品質」を担保するのが事業者の責務になるという考えです。ここを切り分けておくことで、評価設計の現実性が上がりますね。
山崎 それでもユーザー視点で見ると「LLMそのものの品質が悪いのか」「LLMに被せた事業者側の品質が悪いのか」は区別がつきませんよね?また切り分けをしたとして「そのSaaSが本当に適切に品質検査されているのか」は正直見えにくいのが残念でもあります。
松木氏 事業者としては、適切に検査しているかが不透明に感じられる場面もありますが、そこは重要な指摘です。だからこそ、事業者がどこをどう評価しているかを明確にし、説明できる状態にすることが信頼の前提になると考えています。
山崎 なるほど。責任分解点をもう少し具体化して、どこまでがLLM提供者であるベンダー依存で、どこからがSaaS提供者である事業者責務になるかですね。そのような分解点があることを説明できるだけでも、ユーザー視点で見て、品質の捉え方がクリアになりそうです。
松木氏 LLMの基礎性能や学習データの詳細は、クラウド提供者側の領域ですが、自社サービスでの挙動は事業者の責務になります。具体的には、自社プロダクトとして提供する体験であるプロンプト設計、RAGの検索品質、ガードレール設計、入力データ品質、UIなどの出力の評価指標、フォールバック設計などは“事業者がテストすべき範囲”として明確にできます。
Rtoaster GenAIは生成AIとレコメンドを組み合わせた対話型検索で、曖昧なキーワードを扱う前提にあります。このような性質のプロダクトは、従来の仕様/構造ベースのテストだけでは評価が難しいです。機械学習ベースのプロダクトであれば、かろうじて従来のテストで品質検査ができていましたが、評価指標そのものが「機械学習の延長」ではなく、生成AIに合わせて進化する必要がありました。
山崎 自由形式・非構造化データへの対応が必要で、従来のテスト手法では、探索的なテスターの経験に依存するリスクも生じやすかった。そこをどう扱うかが、生成AI組み込み型SaaSの品質保証の核心になりますね。
山崎 確立されていた「機械学習の評価指標」がここ1〜2年で「生成AIの評価指標」に拡張されてきた印象があります。産総研の「機械学習品質マネジメントガイドライン 第4版」(2023年12月12日公開)でも、機械学習品質の体系化が進み、付属文書では新潮流AIへの対応が議論されています。
松木氏 まさにそうですね。従来の機械学習は「正解がある」前提でしたが、生成AIは必ずしも正解が定義できない。そのため、品質の概念が“正解率”から“ユーザーにとっての妥当性・安全性”へ拡張されています。評価の見方が変わったのが最近の動向です。
山崎 この流れを踏まえて“標準仕様”の話に移りたいですが、評価の共通言語が生まれつつある一方で、実務への落とし込みには課題もあるように思います。ガイドライン自体にも、機械学習の品質管理に関する課題が整理されていますよね。
松木氏 はい。第4版の「1.3 機械学習の品質管理に関する課題」では、従来のソフトウェアに対する品質管理の考え方だけでは技術的に不足する点がいくつかあることや、環境条件の複雑さに対する分析の重要性、運用中の環境変化やデータ分布変化への継続的なリスク評価などが挙げられています。
山崎 この「課題整理」があるからこそ、生成AIの評価でも、単発の評価ではなく運用を前提にした設計が必要だという流れにつながりますね。そして、その延長線上に生成AIの“標準仕様”の議論が出てくると。
そこで、2025年5月には産総研が「生成AI品質マネジメントガイドライン 第1版」を公開しました。生成AIの品質マネジメントについて、開発・運用者が行うべき事項を体系的に示した点は大きいと感じていますが、いかがでしょうか。
松木氏 確かにガイドラインは、他社のLLMを部品として使う企業に向けて、品質を実現するための事項を整理しています。品質マネジメントの全体像を俯瞰できる点は非常に有用です。ただ一方で、実務の現場ではこのガイドラインだけで評価が完結するわけではありません。具体的な評価指標や閾値はプロダクトごとに作らざるを得ない。これが私たちの現場感です。
山崎 だからこそ、テスト観点の基盤モデルや、具体的な評価メトリクス設計が必要になるということですね。ガイドラインはあくまで土台で、実装は各プロダクトが担うべき領域ということですね。
松木氏 はい。評価設計は人手できちんと行ったうえで、評価の実際はそれ自体をシステムとして自動で回るようにするのが良いです。さらに言うと、この評価指標でテストを回していくときに、今度は人手評価の限界にぶつかります。評価運用で得た知見をガイドラインやルールに反映し、“人手で回しきれない部分をガイドライン化する”というフィードバックループを作ることが重要だと感じています。
山崎 そのループが回ると、現場の評価がより軽く、精度が上がる。結果的に、より適した評価サイクルに近づけるということですね。今回の対談の前提として、松木さんから「テスト観点基盤モデル(T2T)」という概念をお話し頂いていたのですが、このモデルを整理しておきたいです。なぜ“基盤モデル”という発想が必要なのでしょうか。
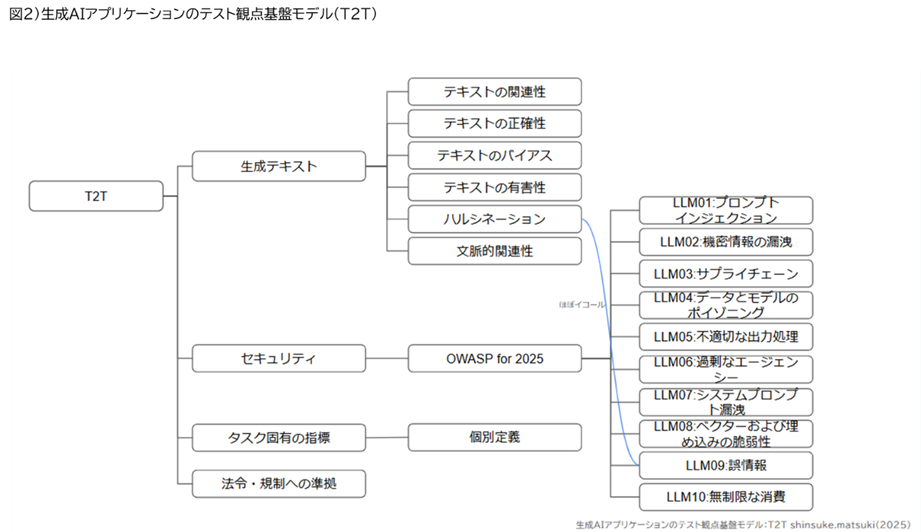
松木氏 このT2Tは、テキスト入力に対してテキストを出力する生成AIアプリケーション全般に通用する観点を整理したモデルです。チャットボット、RAG、リサーチエージェント、コード生成など幅広い領域で共通する観点を、構造化して提示しています。
基盤モデルはそのまま使うのではなく、アプリ固有のタスクに合わせて取捨選択するのが前提です。例えば「文脈的関連性」はマルチターン前提のアプリで重要ですが、単発応答中心なら優先度を下げられる。正確性も、グランドトゥルースが定義できないタスクでは評価が難しくなります。
山崎 つまり、テスト観点としては様々なパターンが考えられるが、“ゼロから考えると漏れがでる”ので、基盤モデルを起点にしておく。そのプロダクトにあった観点を選択的に活用することを目指しているということですね。このなかで「生成テキスト」の観点ではどこまで含まれるべきですか。
松木氏 「生成テキスト」には関連性・正確性・文脈的関連性・ハルシネーションなどが含まれます。ツールの評価観点とも結びつけやすく、ここを明確化することで評価のブレが減ります。
山崎 セキュリティや規制の観点も入っていますか。
松木氏 はい。T2T基盤モデルではセキュリティや法令・規制への準拠も観点として整理されており、テスト設計に組み込むべきものとして提示しています。
山崎 Rotaster GenAIは、本シリーズの第5回で紹介したECサイトなどに新しいタイプのユーザー体験を提供する生成AI型検索エンジンです。このサービスの品質基準をベリサーブさんの支援のもと作りましたが、その具体的なプロジェクトについて話していきましょう。
松木氏 まずは、このT2T基盤モデルでどこを取り組むべきかを整理しました。
この作業はサービスの特性を理解することができれば、スムーズに進行できます。ブレインパッドの皆さんが理解を進めるために情報を整理頂いたので、我々も理解が進んで評価に注力する点を提案しやすかったです。
山崎 Rtoaster GenAI向けの品質基準では、具体的に何を数値化したのでしょうか。
松木氏 ユーザーがコンテキスト検索をする状況を再現し、回答の「関連性」を数値化して評価することで、検索意図に沿っているか、ハルシネーションがないかを判断できるようにしました。バイアス、毒性、プロンプトインジェクション耐性、景表法・薬機法への準拠なども考慮して評価できるように工夫しています。
このように評価基準を設けることで判断が客観化し、テスト観点が体系化され、網羅性の妥当性が上がります。さらに評価を開発プロセスに組み込み、PDCAを回せるようになる点が大きいと考えています。
山崎 具体的にハルシネーションが対策された評価としては、具体的にどんな手が打たれるのが現実的でしょうか。
松木氏 代表的には、回答抑制(わからないと返す)、根拠提示(参照元の明示)、フォールバック検索(通常検索への切り替え)の3つです。評価指標とセットで設計し、品質が落ちるケースでもUXで守るのがセオリーになります。
山崎 評価指標の設計の次に、もう少し評価のプロセスを整理しておきたいです。
松木氏 評価のプロセスは、大きくは次の5ステップです。
| 指標の選定 –> 重み付け –> 閾値決定 –> 評価実施 –> 運用モニタリング |
山崎 指標の選定は、どこから始めるのが良いですか。
松木氏 まずはユースケースに紐づく品質要求から逆算します。検索なら関連性と事実性、対話なら文脈的関連性、そして必須の安全性指標(毒性・バイアスなど)を最初に決めます。次が重み付けです。指標を“全て同じ重さで扱う”と、プロダクトの優先順位が見えなくなる。例えば医療・金融系なら安全性重視、ECの検索なら関連性重視、というように事業特性で重みを置きます。
山崎 ただし、重み付けはトレードオフもありますよね。安全性の閾値を上げると、ユーザー体験が悪くなるなど。
松木氏 その通りです。安全性を上げすぎると回答が消極的になり、UXが落ちることがあります。だから、事業の目的に合わせて「どこまで許容するか」を合意しておく必要があります。
山崎 安全性と有用性の相反は、プロダクトマネージャーとしては一番悩むところだと思います。
松木氏 最終的には「どの失敗を許容できるか」を明文化するしかありません。安全側に倒すなら回答抑制を強める、体験重視なら許容幅を広げる。その判断を、評価指標と一緒に運用ルールとして持つことが重要です。そして、その閾値は、初期はベースラインの測定から始めて、そこから業務要件に合わせて引き上げるのが良いと思います。ユーザー満足度との相関が見えると、閾値の合理性が高まります。
山崎 なるほど。そして評価実施ですが、このプロセスはこのあと詳しくお話ししますので、最後の運用モニタリングについて先に教えてください。
松木氏 運用モニタリングのプロセスはリリース後の話とつながります。運用しながら、閾値を定期的に再評価し、必要なら重みや指標自体を見直す。これが“評価を運用に組み込む”ということです。ただ、運用で見直していくときの閾値の根拠が難しいです。一番現実的なのは、例えばユーザー満足度や問い合わせ率との相関を見ながら調整することです。A/Bテストやサンプルレビューで、スコアと体験が一致するラインを探るのが実務的ではないでしょうか。
山崎 確かに運用中の劣化検知は難しい課題ですね。原因の切り分けが難しいポイントになりそうです。モデル更新・プロンプト変更・ナレッジ更新・季節要因など、要素が多いため、更新履歴と評価結果を紐づけて見られる設計が必要になります。
曖昧検索のようなサービスのユーザー満足度は、関連性スコアやハルシネーション率と直結しますので、UX指標と品質評価をどう結びつけるかが重要になります。
山崎 では、評価プロセスのなかの評価実施についてさらに詳しく教えてください。生成AIの評価は、どんなデータで評価するかがそのまま品質定義になるため、大切なのが「評価データ設計」だと考えています。その点はいかがでしょうか。
松木氏 その通りです。テストケース(プロンプト)や評価用データの設計が粗いと、評価の精度も粗くなってしまう。代表性のあるデータ、エッジケース、実運用で起きやすい失敗パターンを意図的に組み込む必要があります。
山崎 最近は、評価データを生成AIで作ることも増えていますよね。
松木氏 はい。AIで作ること自体は有効ですが、そのデータを人がチェックし、妥当性を確認することが不可欠です。AIが作ったデータの偏りや誤りを放置すると、そのまま評価の歪みになります。
山崎 プロダクトマネージャーやQAエンジニアから見ても、「評価データの品質管理」はプロダクトの品質管理そのものですね。とはいえ、人手評価にも限界があります。どこまで人が見るべきでしょうか。
松木氏 全部を人が見るのは現実的ではないので、サンプリング設計が鍵になります。代表性のあるサンプル、重要ユースケース、リスクが高いケースを重点的に見る。さらに、評価者間のばらつきを減らすために、評価ガイドラインを明文化しておく必要があります。
山崎 評価データが決まったら、次はそのデータに対してどの指標で測るか、ということになりますが、技術的にどのような評価ツールを採用したのでしょうか。
松木氏 LLM出力の評価には「DeepEval」というPhytonベースのオープンソースを使いました。このツールを核にして、入力データ評価と組み合わせたテストフレームワークを設計しました。DeepEvalは、LLMテストをPytestライクに回せるフレームワークで扱いやすく、メトリクスごとに閾値を設定できます。そのため、合否判定をカスタマイズしやすい点で実務に使いやすい特長があります。
山崎 閾値はユースケースごとに決める必要がありますよね。
松木氏 その通りです。実際、テスト観点基盤モデルに基づき、ユースケースごとに閾値をブレインパッドの皆さんと協議しながら決定してテストを実行していました。
山崎 性能評価の具体的な値について伺いたいです。例えば関連性スコアや毒性スコアなど、どの水準を合格ラインに置き、実際にはどの程度の値が出たのでしょうか。
松木氏 具体的な値として開示することは避けたいですが、あくまでイメージとして次のような値で評価できるようにしております。
– 関連性スコア(例):合格ライン `>= 0.80`、実測中央値 `0.86`(n=500)
– ハルシネーションスコア(例):合格ライン `>= 0.85`、実測中央値 `0.88`(n=500)
– 毒性スコア(例):合格ライン `>= 0.98`、実測中央値 `0.993`(n=500)
– バイアススコア(例):合格ライン `>= 0.95`、実測中央値 `0.962`(n=500)
– プロンプトインジェクション耐性(例):合格ライン `>= 0.90`、実測中央値 `0.915`(n=200)
山崎 まとめて整理しますと、これまで見てきたようなこの取り組みにより、T2T基盤モデルによって「どこまで評価対象に含めるか」を定義し、評価を運用するにあたっては、継続的に運用できる形に落とすことが要になります。DeepEvalのようなツールで指標をコード化し、閾値を運用し、改善サイクルに組み込まれたことが現実解として良かったと思います。QAエンジニアとしては、属人的評価から抜け出し、客観性を高められたのが大きい成果ではないでしょうか。
松木氏 そして、リリース前にやっていた評価をリリース後も継続することが重要だということをお伝えしたいです。生成AIはモデル更新やデータ更新で品質が変動しやすい。そのため運用フェーズでも同じ評価指標を回し続けることで、劣化検知と改善が可能になります。
山崎 そしてもうひとつ、我々の視点では、ドメイン特化の評価が重要になります。汎用的な指標だけでは、業界固有の要件やリスクを拾いきれないです。
松木氏 おっしゃる通りです。医療、金融、教育などでは「正確さ」や「規制準拠」の意味合いが変わります。ドメイン固有の観点を、基盤モデルに上乗せして評価設計することが、実務では一番効きます。
山崎 最後に、松木さんが今後の課題だと感じていることを聞かせてください。
松木氏 課題としては、今後AIの性能がどんどん向上していくなか、AIに任せられる部分が増えていきますが、増加するAI担当部分の説明責任、結果責任を人間が十分に果たすための方法論を整備する必要があると考えています。成果物を知る技術、説明するための技術には、我々QAエンジニアが培ってきた製品を知る技術、分析する技術が多分に応用できるのでは、と考えています。
山崎 ベリサーブさんとして、注目されていて今後取り組みたいことがあれば、可能な範囲で教えて頂けますか。
松木氏 私が注目しているのは、評価データの継続更新と、ドリフトを早期検知できる運用設計です。ソフトウェア・AI品質保証のリーディングカンパニーとして、生成AIの普及が進むほど「品質の定義」と「評価の運用」が重要になります。私たちとしては、生成AI時代のQA標準を現場から作ることが事業の核です。プロダクトごとに評価面で伴走しながら、再現性のある手法として体系化し、産業全体の品質向上に貢献したいです。生成AIは分野を問わず入ってくるので、評価の“型”を作れるかどうかが競争力になると考えています。
山崎 我々プロダクトを開発・提供している会社がその恩恵を享受できるというわけですね。期待しております。
本記事の最後になりますが、私が注目しているのは、品質指標を事業指標と結びつけることです。プロダクトマネージャーとしては、品質スコアが売上や継続率にどう効いているかを「見える化」したい。そこができると、品質への投資判断が一段とクリアになります。そして、競合サービスとの差別化を図るうえでも、どこまで品質に取り組んでいるかがユーザーの選択基準になっていくと考えており、今後さらに強化したいポイントです。
今回のベリサーブさんとのプロジェクトがその足がかりになったと感謝しております。本日はありがとうございました。
松木氏 ありがとうございました。
※記載の役職・肩書は2026年3月18日現在のものです。
【備考】
・ブレインパッドとべリサーブの取り組み事例
・ベリサーブの「AIにおけるQA」の取り組み事例
【べリサーブ様 記事のご紹介】
・HQW! 新春対談(前編): 「AIエージェントを誰が監視するのか」――シンギュラリティ到来前に考えるべきこと
・HQW! 新春対談(後編): 「評価を手放したらディストピア」――AIに使いこなされない唯一の方法

あなたにオススメの記事

2023.12.01
生成AI(ジェネレーティブAI)とは?ChatGPTとの違いや仕組み・種類・活用事例

2023.09.21
DX(デジタルトランスフォーメーション)とは?今さら聞けない意味・定義を分かりやすく解説【2024年最新】

2023.11.24
【現役社員が解説】データサイエンティストとは?仕事内容やAI・DX時代に必要なスキル

2023.09.08
DX事例26選:6つの業界別に紹介~有名企業はどんなDXをやっている?~【2024年最新版】

2023.08.23
LLM(大規模言語モデル)とは?生成AIとの違いや活用事例・課題

2024.03.22
生成AIの評価指標・ベンチマークとそれらに関連する問題点や限界を解説
















