



メルマガ登録
-
テーマから探す
-
技術から探す
-
業界・事例から探す
-
関連トレンドから探す
テーマから探す
技術から探す
業界・事例から探す
関連トレンドから探す

現在、ChatGPTに代表される生成AI(ジェネレーティブAI) が世界的なブレイクスルーを起こしつつあります。本稿では、そのブレイクスルーをいち早くみなさんのビジネスやDX推進に取り込んでいただくため、「ChatGPT をどのように社内文書へ特化させるのか?」「社内文書に特化した ChatGPT がどんな応答をしてくれるのか?」に焦点を当て、その実践例をお届けします。
※生成AI(生成系AI,ジェネレーティブAI)の定義や仕組みについて知りたい方は、下の記事もあわせてご覧ください。


ChatGPT (Generative Pre-Trained Transformer) は、インターネット上の膨大な文書を事前学習した生成系チャット AI です。2022年に登場した ChatGPT は、人とのコミュニケーションを高いレベルで実現しています。たとえば、みなさんの中には、すでに日常で次のような使い方をしている方もいらっしゃると思います。
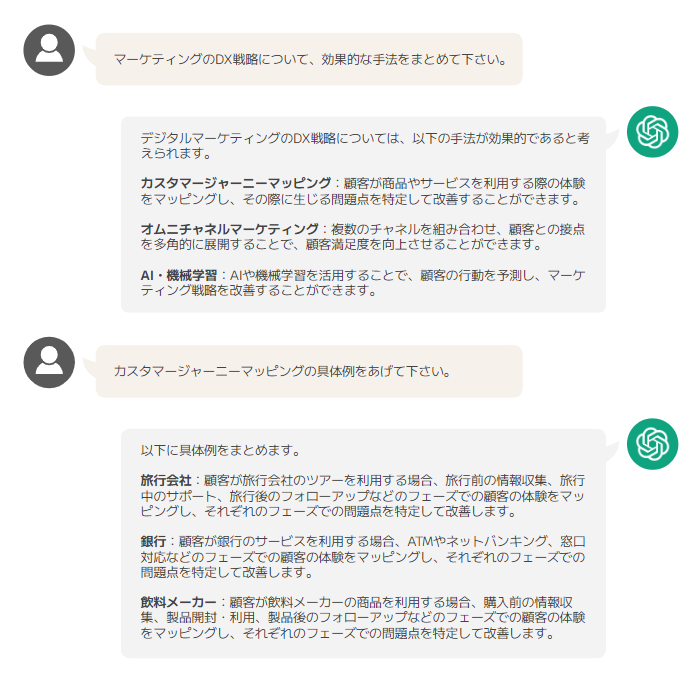
私たちはこれまで何かを知りたいとき、検索して関連記事を見つけ、その内容を読むことで情報にたどり着いていました。しかし、 ChatGPT では、膨大な知識に基づく「答え」が提供されます。この点は従来の技術と一線を画す部分であり、 AI のビジネス実装を新たなステージへ押し上げてくれます。
しかし、 ChatGPT にも苦手なことはあります。それは、社内文書のような非公開情報やドメイン知識を伴う会話です。それらは ChatGPT が事前学習に用いたインターネット上の情報には含まれていないため、そのままでは会話が成立しません。そこで登場する技術が「ファインチューニング(Fine Tuning)」です。ファインチューニングでは、 ChatGPT に新たな文書を学習させ、その内容に関する会話能力を与えます。
次節では、どのように ChatGPT のファインチューニングを行うかを解説します。

ChatGPT に未学習の情報について言及させる方法は、2つあります。もっとも簡単なアプローチは、質問と一緒に情報を入力することです。たとえば、次のような例があげられます。

見てのとおり、 ChatGPT はユーザーが入力した情報を加味して、回答を生成することができています。しかし、いくらでも情報を入力できるかというと、そうではありません。2023年5月現在の ChatGPT では、普及モデル(GPT-3.5)で約3000字、次世代モデル(GPT-4)で約6000字が一度に入力できる文字数の限界になっています。文章を分割して入力することもできるものの、その場合は重要な情報の見落としや文脈の複雑化により、 ChatGPT の回答の質が低下する傾向にあります。一般的な書籍が平均10万字程度あることを考えると、このアプローチで数多くの社内文書を同時に取り扱うことは現実的ではありません。
では、膨大な社内文書に関して会話ができる ChatGPT をつくるためには、どうすればよいのでしょうか?その答えが、もう1つのアプローチであるファインチューニングです。次の図は、ファインチューニングの仕組みを簡単に描いています。
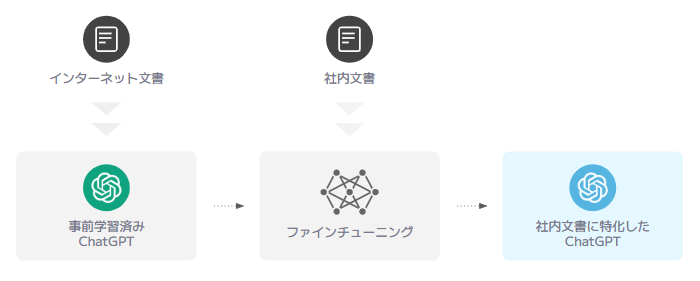
ChatGPT は、膨大なインターネット文書から学習を行い、強力な会話能力を身につけています。ファインチューニングでは、事前学習した基盤をそのままに、社内文書を用いて追加学習を行います。その結果 ChatGPT は、元々の会話能力を受け継ぎながら、社内文書に関する知識を身につけます。
以上のように、ファインチューニングの仕組みは非常にシンプルです。では、社内文書をかき集めれば、それでファインチューニングの準備は万端なのでしょうか。残念ながら、そうではありません。ファインチューニングの際、膨大な社内文書を只々 ChatGPT に与えるだけでは、十分な会話能力は得られません。次節では、ファインチューニングを成功に導く効果的なアプローチを紹介します。

複数の文書を読んだとき、個別の内容について詳しく答えることは、私たち人間にとっても簡単なことではありません。 ChatGPT も同様であり、膨大な文書を与えると、重要な情報の見落としや文脈の取り違えが発生しやすくなります。そもそも私たちは、 ChatGPT に一字一句を覚えさせたいわけではありません。多くの場合は、各文書の主要な話題ついての会話ができれば十分です。
そこでファインチューニングでは、高密度の情報を与えることがおすすめです。たとえば、次のような情報です。
しかしながら、文書が膨大であるほど、 Q&A や要約の生成は簡単な作業ではありません。これらの情報は人力で作るしかないのでしょうか。そんなことはありません。これらもまた、 ChatGPT で自動生成することができます。
具体的な例を見てみましょう。ここでは、 ChatGPT を使って次の記事から Q&A と要約を生成します。ただし、記事全文の文字数を ChatGPT に入力することはできないため、段落別に処理を行ってから ChatGPT で再構成するといった工夫をしています。
【関連】製造業でDXを推進するには?経産省経産省が発信する「観点と企業事例」から読み解く
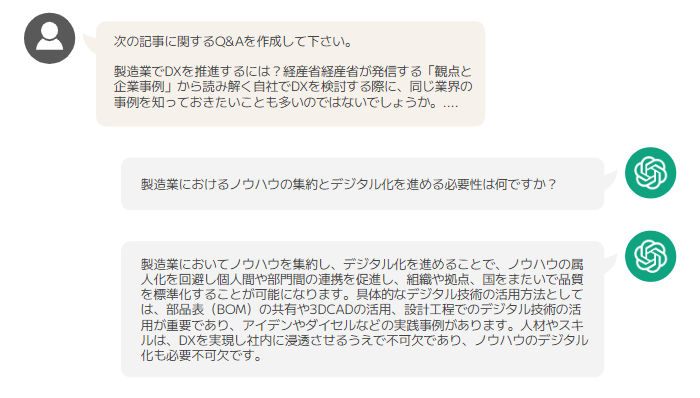

ChatGPT への Q&A や要約の依頼内容は抽象的であるものの、的を射た回答が返ってきています。 ChatGPT への依頼内容を洗練させれば、さらに回答の品質を高めることも可能です。
以上のように、膨大な文書に対して密度の高い情報を自動生成し、それらを使ってファインチューニングすることが、社内文書に特化した ChatGPT を作る上で効果的なアプローチです。次節では、社内文書に特化した ChatGPT がどのような振る舞いをするか、その実力を確認していきます。

では実際に、社内文書に特化した ChatGPT が、社内文書に関する質問にどのように回答するかをみていきましょう。ここでは、 DOORS メディアの約300記事を社内文書として仮定します。ファインチューニングでは、記事ごとに要点をまとめた Q&A を5つ生成して ChatGPT に学習させています。ただし、情報のリークを避けるため、オリジナルの ChatGPT は DOORS メディアが開設される以前の情報のみで事前学習を行っています。
それでは、まずブレインパッドについてオリジナルの ChatGPT に質問してみます。

オリジナルの ChatGPT はブレインパッドに関する情報をもってないため、見当違いの回答を生成しています。 ChatGPT は膨大な情報を学習するため、普遍的な話題には強い一方、個別情報の詳細を語ることは苦手です。では、 DOORS メディアの記事に特化した ChatGPT が、どのような回答をするかをみてみましょう。

DOORS メディアにはブレインパッドについて記述した情報が数多く含まれるため、それらをファインチューニングで学習した結果、的確な回答を生成できるようになっています。
続いて、ドメイン知識に関わる質問をしてみましょう。
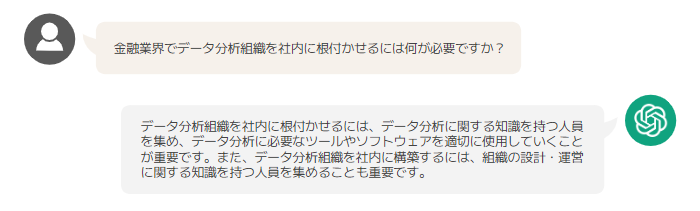
オリジナルの ChatGPT の回答は妥当な内容ではあるものの、一般論に終始しています。これは、事前学習において膨大な情報の共通項のみが強調され、ドメイン知識が薄れていることを示唆しています。では、DOORS メディアの記事に特化させた ChatGPT の答えをみてみましょう。
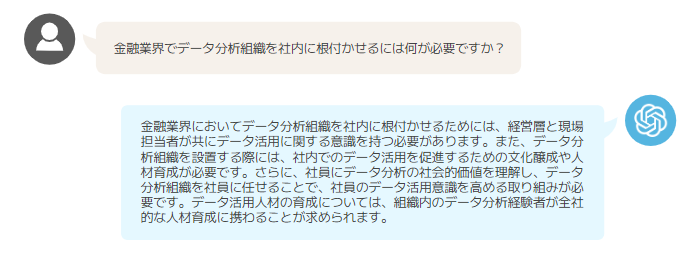
期待どおり、DOORS メディアの一部記事で言及されているデータ活用の組織文化醸成について、踏み込んだ回答が行われています。ファインチューニングを行った ChatGPT には、学習したドメイン知識に基づいて回答を補完・強化してくれる特徴があります。
以上のように、社内文書を学習した ChatGPT が、大規模言語モデル(LLM:Large Language Model)の活用シーンを広げてくれることは間違いありません。ただし、課題も残されています。それは、社内文書の表現力をどのように評価するかです。人間のやり取りでも質問側の期待値は曖昧であることが多く、質問に対する回答がどれだけ的確であるかの定量化は容易ではありません。これは ChatGPT でも同じです。今後、どのような定量指標をクリアすれば社内文書への特化が成功したと言えるのかについて、議論を深めていく必要があります。
【関連記事】
Google のような従来の検索エンジンは、質問に対して関連度の高い記事を見つけて情報を提供しています。そのため、情報から答えを探す手間はかかるものの、何を根拠にして結論を導いたかは人の目からも明らかでした。一方、 ChatGPT は答えを返してくれるため、利便性は高いものの、根拠を追跡することができません。それ故、誤った回答が含まれている場合に気づきにくい側面があります。
ここでは、 ChatGPT で根拠文書を参照するための仕組みをご紹介します。もっともシンプルなアプローチは、ChatGPT による検索と要約の組み合わせです。ユーザーが質問してから回答と根拠文書を得るまでの流れは、次のとおりです。
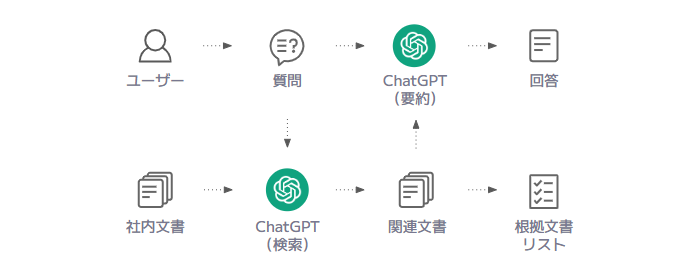
ChatGPT で検索なんてできるのか?と思われるかもしれませんが、 ChatGPT には「Embedding」と呼ばれる文書の類似度を測る仕組みがあります。これを使うことで、 ChatGPT の強力な言語能力の下で類似文書を検索することが可能です。
以上のように ChatGPT の回答が根拠文書を伴うことで、ビジネスシーンでの利便性は飛躍的に高まります。特に厳密性が要求される特許文書や研究論文などを取り扱う際には、欠かせないポイントです。次節では、 ChatGPT に渡した社内文書がセキュリティ上、安全であるかについて利用規約を確認します。
社内文書が想定外の用途で学習に使われてしまうとセキュリティ上のリスクとなるため、その安全性は業務利用において極めて重要です。ここでは、 OpenAI と Azure OpenAI Service の規約上で学習データがどのような取り扱いになっているかを確認します。結論を言えば、2023年5月現在の規約では、学習データの転用を避けて安全に取り扱う手段が用意されています。
OpenAI の利用規約の要点は、次のとおりです。
3. Content
(c) Use of Content to Improve Services.
We do not use Content that you provide to or receive from our API (“API Content”) to develop or improve our Services. We may use Content from Services other than our API (“Non-API Content”) to help develop and improve our Services. You can read more here about how Non-API Content may be used to improve model performance. If you do not want your Non-API Content used to improve Services, you can opt out by filling out this form. Please note that in some cases this may limit the ability of our Services to better address your specific use case.
Azure OpenAI Service のデータ保管規約の要点は、次のとおりです。
Training data for purposes of fine-tuning an OpenAI model
… Training data provided by the customer is only used to fine-tune the customer’s model and is not used by Microsoft to train or improve any Microsoft models.
How is data retained and what Customer controls are available?
… Prompts and completions. The prompts and completions data may be temporarily stored by the Azure OpenAI Service in the same region as the resource for up to 30 days. This data is encrypted and is only accessible to authorized Microsoft employees for (1) debugging purposes in the event of a failure, and (2) investigating patterns of abuse and misuse to determine if the service is being used in a manner that violates the applicable product terms.
Note: When a customer is approved for modified abuse monitoring, prompts and completions data are not stored, and thus Microsoft employees have no access to the data.
本稿では、社内文書に特化した ChatGPT をつくる方法、その実力と関連情報についてまとめました。 ChatGPT が急速に発展する中、これらをいち早くビジネス実装していくことが市場で一歩リードするための鍵となります。
社内文書に特化させた ChatGPT をつくりたい、そういったご要望がありましたらブレインパッドにご相談ください。当社の専門部隊がみなさんのソリューション化をご支援いたします。
※ChatGPTに限らず、データ活用やAIを用いたDX事例がブレインパッドでは複数ございます。以下の記事もご覧いただけると、他社様のDXに関するお取組みやDX事例がご覧いただけます。
【関連記事】【業界別DX事例26選】成功事例から学ぶビジネス革新の方法論
記事・執筆者についてのご意見・ご感想や、お問い合わせについてはこちらから
あなたにオススメの記事

2023.12.01
生成AI(ジェネレーティブAI)とは?ChatGPTとの違いや仕組み・種類・活用事例

2023.09.21
DX(デジタルトランスフォーメーション)とは?今さら聞けない意味・定義を分かりやすく解説【2024年最新】

2023.11.24
【現役社員が解説】データサイエンティストとは?仕事内容やAI・DX時代に必要なスキル

2023.09.08
DX事例26選:6つの業界別に紹介~有名企業はどんなDXをやっている?~【2024年最新版】

2023.08.23
LLM(大規模言語モデル)とは?生成AIとの違いや活用事例・課題

2024.03.22
生成AIの評価指標・ベンチマークとそれらに関連する問題点や限界を解説













