



メルマガ登録
-
テーマから探す
-
技術から探す
-
業界・事例から探す
-
関連トレンドから探す
テーマから探す
技術から探す
業界・事例から探す
関連トレンドから探す

本記事では、LLMやジェネレーティブAIを企業活動に取り入れるために重要となるポイントについて、Google Cloud とブレインパッドの対談を通してご紹介いたします。
【関連記事】
生成AI(ジェネレーティブAI)とは?ChatGPTとの違いや仕組み・種類・活用事例
LLM(大規模言語モデル)とは?生成AIとの違いや活用事例・課題
AI導入がトレンドになる一方、データガバナンスやセキュリティ面についても懸念される中で、どのようなバランスで機械学習を社会実装に結び付ければいいのか、本記事を通してヒントが見つかるはずです。
※本対談は、2023年6月5日から6月16日にかけて開催された日本最大級DXオンラインイベント「DOORS-BrainPad DX Conference2023」で配信されたものです。他にも収録されたコンテンツがあるので、読んでみてください。
関連する資料ダウンロードはこちら
全6社の事例とDXリーダーの「格言」を収録。保存・配布に便利なリーフレット!
▼本対談の登壇者一覧


ブレインパッド・筧 直之(以下、筧) 本セッションでは、「ジェネレーティブAI時代における機械学習の社会実装への向き合い方」というテーマで、Google Cloud のAI機械学習に関する事業開発部長をされている下田様との対談をお届けいたします。
Google Cloud とは、AIや機械学習データウェアハウスの領域において、10年以上のお付き合いをさせていただいており、本日は最新技術の動向を踏まえたお話を展開していく予定です。
下田さんとはすでにさまざまな取り組みを行っており、ご一緒できて嬉しく思っております。
またブレインパッドからは、データサイエンティストの辻も参加し、技術的な議論も深めていければと思っております。
では最初に、ブレインパッドと Google Cloud との関係性について簡単にご紹介いたします。約10年前、ブレインパッドが Google Cloud のデータサイエンス領域を支援するところからスタートしております。
その後 Google Cloud がとある食品メーカーの工場における不良検知のソリューションを提案された際にブレインパッドもご一緒し、そこからパートナー契約させていただきました。
そこからはAIや機械学習領域に絞って連携し始め、2016年には、ディープラーニングと呼ばれている画像認識を中心に使われる技術が注目され多くの企業を支援することになりました。その後も機械学習だけでなく、通販企業のデータマーケティング基盤の構築や小売りのサービス基盤の刷新など、データ利活用の範囲を広げてきています。
直近ではサプライチェーンの最適化、データ活用の内製化でもご一緒させていただいております。
ではここからは、下田さんが現在担当されているサービスに関してご紹介いただけますか?

グーグル・クラウド・ジャパン 下田 倫大氏(以下、下田氏) Google Cloud で提供させていただいているAIや機械学習のソリューションは総称として「クラウドAI」と呼んでおり、大きく2つのカテゴリに分かれて提供している状況です。
1つ目はビジネスソリューションカテゴリ。ビジネスにおいてさまざまなユースケースがありますが、そういった特定のユースケースに沿ったシナリオの中でAIや機械学習を活用するようなSaaSを提供しています。
具体例を挙げると「コンタクトセンターAI」ソリューションです。コンタクトセンターやカスタマーセンターの領域にAIのテクノロジーを持ち込み、イノベーションをもたらすサービスです。
特にコンタクトセンター領域は、コロナによって一気にデジタル化が進みました。急速なデジタル化の中で顧客との接点という部分では、コンタクトセンターが担う役割が増えています。
なので「多くの方がコンタクトセンターに問い合わせをするようになってしまい、顧客が待ってしまうシーン」がより目立つようになりましたが、そういった課題を解消するべく「応答を自動化していくことで顧客を待たせない」ような制御を取り入れています。
まだまだ「自動化しきれない部分で人が対応する」状況は存在すると思いますが、そうは言っても人材不足の問題があり、仮に採用できても今度はオペレーションのトレーニングが必要になり、なかなか十分なリソースが確保できない状況が続いています。そのような背景もあり、オペレーター業務の支援は非常に重要です。
このAIテクノロジーはいわゆる機械学習に詳しい方やデータサイエンティストといった専門家ではなく、意思決定に関与するビジネス側の方にご活用いただけるソリューションとなっています。
筧 私も別のプロジェクトでサプライチェーンソリューションに関わらせていただいておりますが、サプライチェーンソリューションに関しては最適な計画を算出するロジック自体が組み込まれており、顧客がそのまま使えるように設計されています。これには非常に驚きました。
また提供する側も自由にカスタマイズできるようになっているので、顧客だけでなく、ブレインパッドも使いやすいソリューションだと感じています。
それでは2つ目のカテゴリーについて教えていただけますか?

下田氏 2つ目のカテゴリーはエンドツーエンドのプラットフォームです。これは機械学習のモデル作成から実運用まで支援する一連の流れをカバーするプラットフォーム「Vertex AI」を指しています。
例えば、画像や言語及び音声、翻訳といったさまざまなデータのフォーマットに応じた、グーグル・クラウドですでに提供している事前学習済みのモデル。これは一からモデルを作っていただく必要がなく、APIをコールすれば次のような技術が可能になります。
など。こうして、データサイエンティストや機械学習のエンジニアがモデルを作る環境を提供しています。また環境提供だけでなく、モデルをワークフローやサービスに組み込むための一連のデータパイプライン作成や、機械学習のモデルを用いた予測の実行といった仕組みも展開できるようになっています。
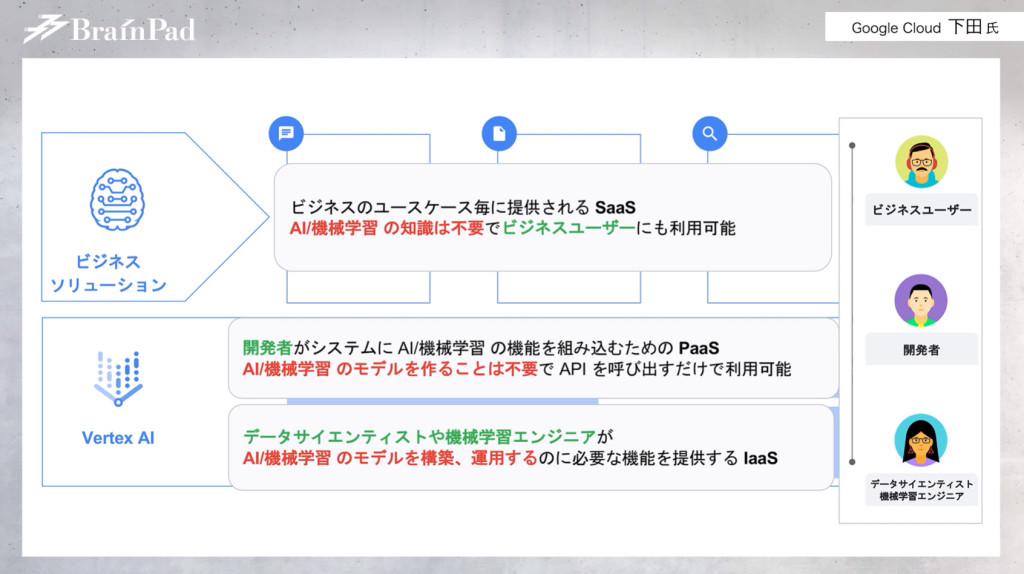
上図のように、モデル開発を行っているデータサイエンティストや研究開発をしているリサーチャーといった方々を対象に、幅広く使用してもらえるソリューションとなっています。
ここで、「Vertex AI」を日々ご活用いただいている辻さんから、「Vertex AI」に対する印象や感想をお話しいただけますか?

ブレインパッド・辻 陽行(以下、辻) 「Vertex AI」を使っている時に感じるメリットは2つあります。
1つ目は処理能力の速さ。ブレインパッドが扱うデータは非常に大規模なデータが多いため、一度モデルの予測処理をさせようとした場合、普通の環境だと時間がかかってしまいます。しかし、「Vertex AI」だと高速に行うことが可能です。トライ&エラーや仮説検証を行いやすく、データサイエンティストが業務に集中できるようになっています。
またBigQueryのデータベースとの統合も十分に進んでいるため、作ったものが本番や我々の検証環境にそのまま移行できるのも2つ目のメリットとして感じています。
筧 では、2つ目のテーマである「機械学習技術の変遷と社会実装のニーズの変遷」に移ります。
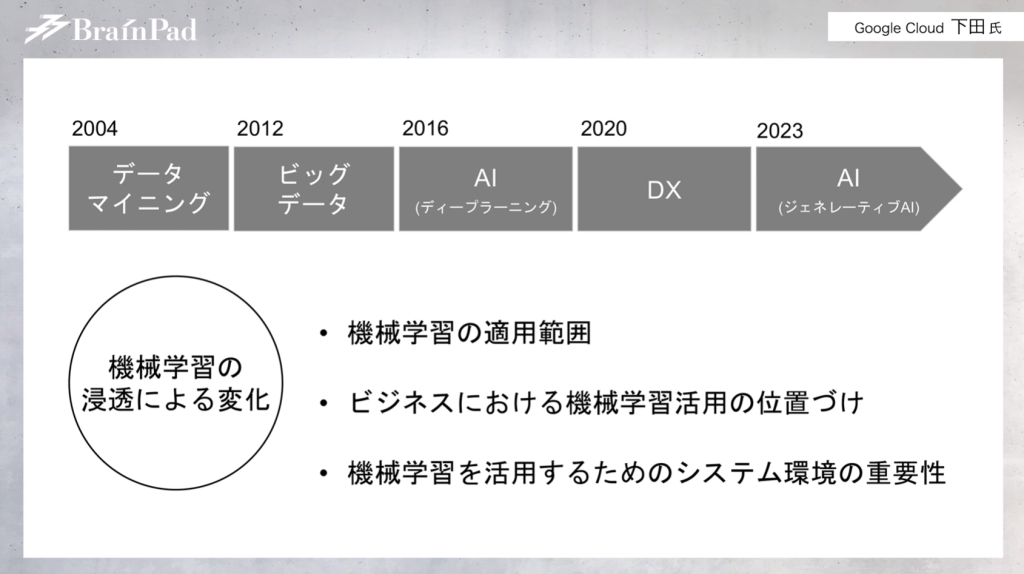
私がブレインパッドに入社した2004年のキーワードは「データマイニング」でしたが、そこから2012年は「ビッグデータ」、2016年には「AI」、2020年には「DX」となり、2023年には改めて「AI」というふうに、キーワードが移り変わっています。
機械学習の活用の重要性が徐々に認識されてきており、機械学習の適用範囲も従来と比べると格段に広がっています。例えば、以前は商品のレコメンデーションや需要予測といった特定のテーマ・業務にAIが使われることがほとんどでした。
しかし最近では、マーケティング領域で言えば「マーケティングプロセス全体」が対象となったり、サプライチェーンで言えば「自社と社外も含めたサプライチェーン全体」を対象としてAIを活用するような意識に変化しています。
このあたり、日頃データサイエンティストとしてクライアント様を支援される辻さんはどのような所感をお持ちでしょうか?

辻 ビジネスにおける機械学習の適用範囲拡大は、私も進んでいると感じています。実際、ブレインパッドの支援もビジネスプロセスの拡大にしたがって変化してきています。
以前は「分析のレポートをアウトプットする」ことが価値提供の一つとされていましたが、今は「ビジネスプロセスの中にAIをどう組み込んでいくのかを考える」ようなサポートが求められるようになってきていますね。システムの構築のみでなく、構築した上でそれを組織の中にどのように組み込むのか、どのようにデータ活用のレベルを上げていくかを支援するようになりました。
そのため今はビジネスユーザーの方々とお話しする機会も増えています。以前はデータサイエンティストとお話しすることが多かったので、こういうところからも変化が見えますよね。

あと、もう一つ思うのが「分析や機械学習を使う環境」も大きく変わってきています。以前は、モデルを作る際はデータサイエンティストが一から仕組みを作り(フルスクラッチ開発)、それをブレインパッド自身が管理する形で開発や運用を進めていました。
しかしビジネスプロセスの中にAIを組み込む必要がある現在では、ブレインパッドだけに閉じて使用できる環境は好ましくないのです。特定の組織だけでデータやモデルを保持しているとレバレッジが効かない、いわゆるサイロ化につながってしまいます。
なのでデータがサイロ化しない仕組みが必要であり、そのために求められたサービスがクラウドサービスだと理解しています。

筧 次は3つ目のテーマとして、「機械学習の社会実装」に触れていきますね。機械学習を活用する場合、さまざまな壁があると想定されます。その上で、クラウドを使うことによってどのように乗り越えていくかという内容のお話しを展開していきたいと思います。
辻さんから、スクラッチ開発ではサイロ化する傾向があるため、クラウドを使っていくと良いという話がありました。では下田さんから、この課題をどのように捉えてサービスを提供されているのかをお話しいただけますか?

下田氏 エンタープライズ企業が実際に機械学習を社会実装していく上で重要になるポイントは3点あります。
1つ目は「コンピューティングリソース」です。
機械学習には非常に大きなCPUやGPUが必要です。学習プロセスで特にコンピューティングリソースが必要になるのですが、学習が完了した後は、もう一度モデルをアップデートするまでは同様のリソ―スは不要になってしまいます。
つまり、学習をするためだけにCPUやGPUを多く持っていると「無駄」が多くなります。
一方でクラウドですと、使いたい時に必要なものをクラウドプロバイダーから購入、使用するという流れになります。ダイナミックにコンピューティングのリソースが変化していく中でのワークロードには適しています。
よく、「突然大きな処理をしなければならなくなったものの手持ちのリソースが足りない」というようなケースが起きるのですが、クラウドという選択肢があれば柔軟なコンピューティングリソースを確保でき、ストレスフリーで機械学習のエンジニアの方やデータサイエンティストが業務に取り組めるようになると感じます。
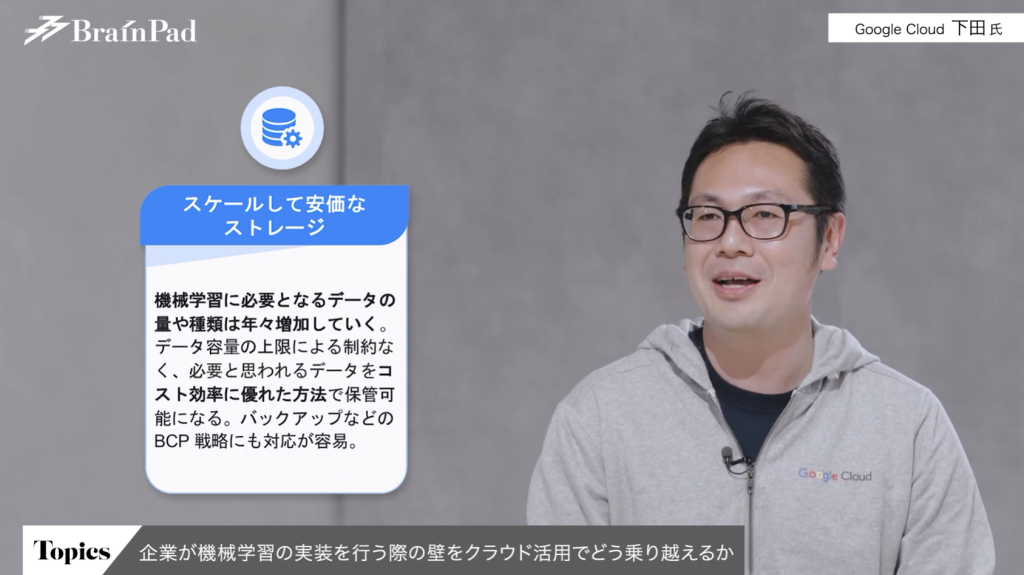
2点目がデータの保持です。
機械学習は、テキストデータや数値データだけでなく、画像や音声といった容量の大きいデータも必要になります。
そのため、いわゆるローカル環境やオンプレミスの環境にそういったデータを集めようとすると、容量の上限があるので・どうしても何かしらの工夫が求められますよね。
このような場面において、クラウドのストレージは非常に適しています。また機械学習はどのデータが必要になるのかは、実際に学習してみて初めて分かることも多いので、必要そうなデータをすべて残すことも多いと思います。そういう意味でもクラウドストレージは重宝します。
よく「2年でデータを削除しなければならないが、本当に削除していいのかどうかが分からない」というような制限に困ってしまうケースもあると思いますが、そういった制限も気にせずデータを溜められるのもメリットとなりますね。
辻 1点目のマシンリソースに関しては、モデルの予測を行うタイミングでクラウドだと柔軟に必要なマシンリソース変えられる点は大きなメリットだと私も思います。
具体的に言うと、需要予測のプロジェクトでは、モデルの予測が上手くいっている場合「対象範囲をもっと広げたい」「予測頻度をもっと細かくしたい」みたいなオーダーをされることがあるのですが、計画当初の予算で取ったオンプレミスのサーバーだとそれが柔軟に対応できない、となる場合があります。
しかしクラウドであればサーバーのことは一切考えずにプロジェクトにより集中できるため、非常に助かっていますね。

下田氏 なるほど。プロジェクトが上手くいっているからこそさらにリソースが必要になる、というのは非常に面白いですね。
話を戻しまして、エンタープライズ企業が実際に機械学習を社会実装していく上で重要になるポイント3つ目が「APIやマネージドサービス」です。
先ほどお話しした「Vertex AI」はツールという捉え方だけでなく「マネージドな環境」とも捉えられます。マネージドなサービスの上で、さまざまな機械学習のタスクが楽になるようなものを提供しています。
例えば、AutoMLは独自で高精度なモデルを作れますが、フルスクラッチで作る必要はありません。データを少し加えることで、非常に高精度なモデルを作ることが可能です。
これは人材不足となっているデータサイエンティストや機械学習エンジニアにとって重要です。「フルスクラッチで作るべきなのか」「APIやAutoMLを組み合わせながら使うべきなのか」といった使い分けができれば、限られたリソースであるデータサイエンティストや機械学習の人々がより幅広く、深い仕事をしていく環境が作られます。
そういった意味で組織の能力のスケールにもクラウドサービスは向いている部分があると感じていますね。
辻 データサイエンティストは自分でコードを書きたい傾向がありますが、後々の運用まで考えると「プロセスが標準化されている」「誰が見ても何が行われているのかが分かる」状態で管理されていることも重要です。したがって処理を標準化できるVertex AIのようなサービスは凄くメリットを感じています。
分析やモデル開発にフォーカスできるようになりますし、運用に対しても無駄なことを考えずにいられています。
筧 では、本題である「最新トレンドとしての大規模言語モデル・ジェネレーティブAI」のテーマに移ります。
今、毎日のように話題になっているChatGPTを含む大規模言語モデル(Large Language Models・以下、LLM)を、個人的に使用されている方もどんどん増えていると思います。
いったん認識をすり合わせるために、そんなLLMとジェネレーティブAIの違いについて辻さんに解説いただいてもよろしいでしょうか?

辻 LLMは、大量の自然言語のデータを学習し、学習した内容によって自然な文章を機械が生成する・文章の意味を理解して質問に答えるAIを指します。
一方でジェネレーティブAIは、自然言語に限らずもっと広い範囲でのデータ(画像や音声など)を学習し、自然言語だけでなく音声や画像を生成するAIを総称しています。
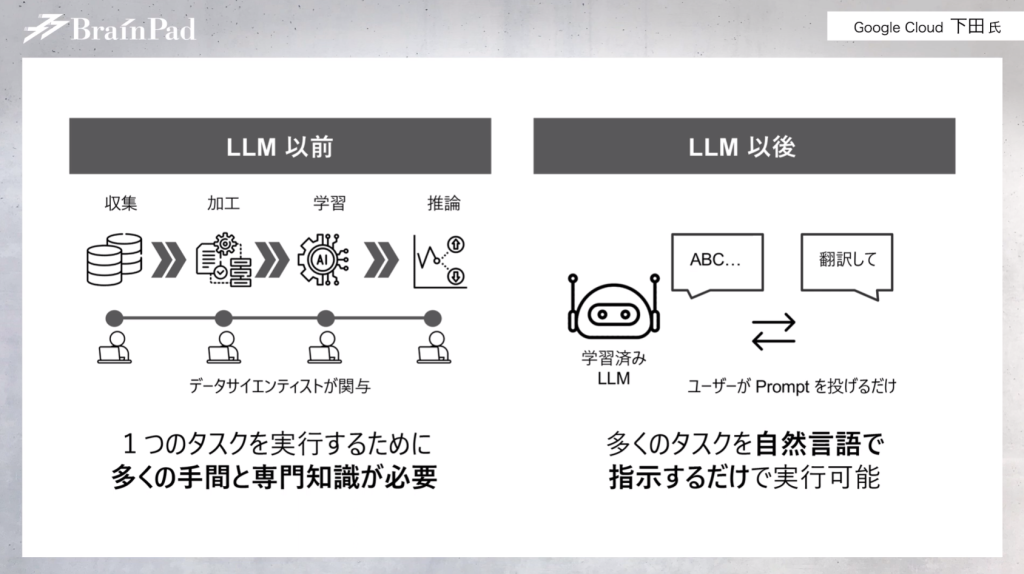
ChatGPTをはじめとするLLMは、これまでの機械学習に必要だった工程であるデータ収集や加工、データサイエンティストがモデリングする専門知識、実際にかかる労力を必要としません。事前学習済みモデルに対して会話のような形式でタスク指示を出せるようになった点が大きな革新です。
データサイエンティストはPythonをはじめとしたプログラミング言語を通して、機械学習における予測や判別を行っていました。ところがプログラミング言語を通さずとも、人に指示を出すような感覚でタスク処理が可能になったため、データサイエンティスト以外の人もLLMを利用できるようになりました。
私が考えるLLMが注目されるようになった理由は、今まで専門家に閉じていた技術がビジネスユーザーや一般の方でも簡単に使えるようになった点かつ、想像以上にさまざまなタスクをこなせる点。この2つが大きいと思います。
機械学習はこれまで企業の中だけで使われていた印象でしたが、現在は企業以外でも使われています。例えば毎日の献立の提案にLLMを活用する、など。
ちなみに、最近 Google Cloud でもLLMやジェネレーティブAIに対する取り組みを発表されましたよね?

下田氏 はい、2つのプロダクトを発表しました。
1つ目は「Vertex AI」にジェネレーティブAIのモデルを利用するための機能拡張を追加したプロダクトです。
ジェネレーティブAIを扱うにあたって色々な機能がありますが、その中に「モデルガーデン」という、さまざまなモデルをホストする機能があります。
ジェネレーティブAIやLLMと一言でいっても、特定のモデルを指すわけではなくさまざまなモデルがあり、そういったLLMに関わるあらゆるAIや機械学習のモデルを集めてホストしています。
タスクに使用するモデルを選び、その後ジェネレーティブAIスタジオと呼ばれるものを使って、モデルを微修正したり、挙動を確かめたりすることが可能です。
また、APIやSDKと呼ばれているプログラムから呼び出すための仕組みを活用することで、ワークフローや実際のアプリケーションにLLMやジェネレーティブAIのモデルを組み込めるサービス及び機能になっています。
そして2つ目に発表したプロダクトが「Generative AI App Builder」です。
「Vertex AI」は機械学習に詳しい方に向けたプロダクトですが、「Generative AI App Builder」は「機械学習に詳しくない方」に向けたものだと思ってください。LLMの典型的なユースケース「会話と検索」に特化した形で、LLMをアプリケーションに組み込むことが可能です。
例えば「Eコマース上でチャットを開くと、本物の人間が対応してくれているような振る舞いをできるようになる」「社内にある多くの文書と文書管理システムに対して検索の機能を組み込み、社内のアセットや資産を活用しやすくする」といったサービスを提供できます。
こういったものをマネージドサービスの形式で、Google Cloud 上からのサービスとして使用できます。

筧 では次に「LLMを実際の企業の課題解決に対して活用するポイント」というテーマに移ります。
ずばり、LLMはどういった企業課題を解決できるのでしょうか?

辻 今、LLMを使って企業が取り組み始めていることは2つあります。
これらの取り組みは増えてきていますね。
企業内だけに存在する業務データは当然、LLMのモデルでは学習されていません。そのためエンタープライズ向けにLLMを利用する場合には、いかにLLMに企業データを学ばせるかがキーになります。
そういったチューニングの方法には、ある程度の専門性が求められるため、ブレインパッドにもチューニングに関連するご相談が増えてきています。
下田氏 プロンプトエンジニアリングやファインチューニングは、これからもっと重要なキーワード及びテクノロジーになってくると思いますが、これら2つの技術の使い分けや扱い方のポイントについて、もう少し詳しく教えていただけないでしょうか?

辻 プロンプトエンジニアリングとファインチューニングは、どちらもLLMを開発したり、学習を行ったりする技術です。
まず、プロンプトエンジニアリングはモデルの性能や精度を向上させるために、入力プロンプトを設計するアプローチに該当します。
例えば、「この文章を解説してください」と命令するとしましょう。その時に、「その解説をお願いする意図」が示されていなければ解説をお願いされたモデルもどのように返答していいか分からなくなりますよね。
そこで「AIの専門家としてこの文章を解説してください」と聞けば、より解像度の高い返答をしてくれるようになります。指示の内容を変更していくことが、プロンプトエンジニアリングで必要になります。自然言語で可能なアプローチなので、誰でも取り組める点は非常に魅力的ですね。

対してファインチューニングは、新しいタスクに適用させるために、特定のデータセットを使用してモデルそのものを学習し直すアプローチです。先ほどの例で言うと、企業内のデータが該当します。
例えば、日本語を学習していないLLMがあったとします。この場合、日本語で応答を返すことができないLLMとなっているため、先ほど言っていたプロンプトエンジニアリングの手法を使っても日本語で返答してくれません。
こういった場合、日本語のデータセットを用意して、LLMが日本語で返せるように調整していくことがファインチューニングですね。
よって「気軽に取り組めるプロンプトエンジニアリング」と「専門性が必要なファインチューニング」を、タスクに応じて使い分ける必要があるのではないかと考えています。
下田氏 特にプロンプトエンジニアリングは、従来のAIや機械学習の中では登場してきませんでした。逆に言えばこれが、ビジネスユーザーの方がAIや機械学習を身近に感じることになった要素だと言えそうですよね。
筧 観点を少し変えて質問させていただきます。先ほど下田さんから「どんなに高性能なモデルがあったとしても、企業のサービスや業務で使おうとする場合はアプリケーションとして実装する必要がある」とお話しされました。
そこで、現場に受け入れられるアプリケーションを作るためにどのようなポイントに気を付けていらっしゃるか、日々現場を支援されている辻さんからおうかがいできますか?

辻 LLMは「正確な事実を述べることが苦手」な傾向にあります。例えば「計算」。LLMをビジネス上で扱うときに、計算を誤ってしまうのは許されないですよね。だから業務のすべてをLLMに任せることは事実上難しいです。
したがって、LLMを今後企業の中で活用するためには、既存の業務を確実に遂行できるシステムや社内ドメインの知識を持つ人間と、うまく連携しながら活用していく必要があります。
筧 LLMのコストについてはいかがでしょうか?。私の認識だと、今までの機械学習はコストの試算は難しく、通常のシステム開発と違ってROI(費用対効果)が考えにくいイメージです。

辻 これまでの機械学習と同様で、「LLMをビジネスフローに組み込んだ時にどのぐらいのお金になるのか」を検討する必要があると考えています。
LLMを使用する上での「学習」や「推論」に対するコストも重要ですが、それより重要な「安全に・継続的に運用するのに必要なコスト」を考慮しなければなりません。
またLLMは気軽に使えることから、今までよりもAIを活用するユーザーが想定している以上に増えてくるので、サービス利用者をきちんと想定しなければならないです。コストコントロールが今まで以上に重要で難しくなるというわけです。
もっと言うと、LLMの推論や予測を「スピーディーに」行うには、高いマシンリソースを確保する必要があります。なので利用ユーザーが爆発的に増えたりすると想定していたコストを大きく上回り、「採算の取れるサービス設計になっていない」ケースに陥ることも少なくありません。
これはビジネス側だけでなく、データサイエンティストも一緒に考慮すべきポイントです。
筧 一般利用のユーザーが増えること自体は、データの民主化やAIの民主化が進むことであるため、本当に喜ばしいことです。ただ守りの面として、ガバナンスやセキュリティを担保したサステナビリティのある運用がより重要だと感じました。
こういったセキュリティやガバナンス周りを、グーグル・クラウド様は強く意識されていると思うのですがいかがでしょうか?

下田氏 機密性及び秘匿性の高い情報を機械学習のモデルに入れる・入れないという判断は今後どんどん求められるようになりますし、非常に重要な要素です。その中でクラウドは、セキュリティやガバナンスに関して非常に取り扱いやすく、利用者の労力が減ってくると思っています。
これは Google Cloud に限らずクラウドプロバイダーであれば、専門家が常に最新のセキュリティを維持しようとプラットフォーム側で取り組むため、個別のマシンに対して、一つずつセキュリティを最新の状態にしていく労力が不要となります。これはセキュリティ面の一つのメリットです。
もう一つ重要な点であるガバナンスに関しても、Google Cloud は各地域やさまざまな業態・業務で必要になるコンプライアンス基準及び認証は既に Google Cloud として取得しています。
なので Google Cloud を使うと、そういった認証やコンプライアンスを最初から満たせているものを使用できることになります。
ここを一から自力で作っていく作業を省力化できる点が Google Cloud のセキュリティやコンプライアンスのポイントです。
またクラウド上では、統一的な権限管理によるユーザー管理が可能です。実運用の部分でも決めたルールを仕組みとして、運用していくことが簡単に実現できます。
適切な運用を行うことが前提ではあるものの、クラウド上でより安心安全にデータを取り扱うことが可能です。

筧 では次に、LMMを企業の「どの領域で使っていくべきか」というユースケースについて議論していきたいと思います。
現状だと社内Q&Aや検索活用が多い印象でした。今後は研究開発領域やサプライチェーン領域にも広がっていくと思っています。
このあたり辻さんは、技術的・実務的な観点でどのような領域に今後広がっていくと思いますか?

辻 LLMは、今まで非構造データと呼ばれるような画像や自然言語が今まで意味付けされずにデータが取りたまっていました。しかし、今後は人間が理解しやすい形でタグ付けしてくれることで活用が容易になると思っています。
例えば、顧客から寄せられた要望や商品の評価を人間が逐一行っていくのは現実的ではありません。しかしLLMを使った場合、書かれている文章がどういうものなのか、ポジティブかネガティブかといった判定をすぐできるようになるため、蓄積が容易になるでしょう。
個人的に面白いと思っている使われ方として、LLMは今後人間の作業のアシスタントを行う形式になっていくと想定しています。先ほどの例で言うと、顧客の要望の内容をカテゴリーごとに分類しようとする場合、データサイエンティストであれば適切なモデルを選定できますが、知識のない方はそれが難しいです。
しかし今後、それさえもLLMに対して「顧客の要望に対する分類を行ってください」といった抽象的な要望を投げかければ、モデルの選定や分析設計を行ってくれるようになる可能性があります。
もちろん実際に提案された内容がこちらの意図に沿っているのかチェックする必要はあるため、完全自動ではなく、あくまで人間のサポート的な立ち位置で、使われ方のバリエーションが広がっていくかもしれません。

筧 では、最後のテーマの「LLMを企業のビジネスや経営にどう取り込んでいくべきか」という内容に移ります。
LLMによる機械学習の社会実装によってどのような影響や変化を及ぼすのか、辻さんからお話しいただけますか?
辻 現在、企業全体でデータ活用が推進されている状況です。LLMやジェネレーティブAIは、多くのタスクをこなせる可能性を秘めているものです。そのため、ビジネスフローの中での活用も今後進んでいくでしょう。
今までの議論にもあった、特定のドメインやタスクに特化した今までの機械学習のモデルと組み合わせながら、LLMが社会の中で実装されていくと想定されます。
筧 LLM単体ではなく、これまでの技術も組み合わせていくというイメージですね。
続いて、LLMの登場によって企業が心がけるべき意識は何か、下田さんからお話しいただけますか?

下田氏 ユースケースが今後もどんどん増えてくると思います。これまでのAIや機械学習ではできなかったこと・困難だったことが、LLMによって容易に実現できるようになっていますから。
一方で、LLMのような新しいテクノロジーだけを使っていれば全てが解決するというわけでもありません。
言語モデルであるLLMは数値データを扱えないというお話もありましたが、そのような特色自体を正しく理解した上で、自社の業務にどのように適応させるかの見極めが重要です。
そういった意味では、LLMに限らず、従来のAIや機械学習に必要とされていた考え方と実は何ら変わりないかもしれません。「技術を正しく理解した上で自社の業務やサービスにどう適応できるのか」を深掘りしていくという点に尽きると思います。
筧 本セッションのまとめに入ります。
1点目は、LLMとジェネレーティブAIによって対応できることが増えてきていること。
意識すべき点として、利用者が一気に広がったことで一般消費者、各企業の社員や経営層の方の注目度も上がっている状況です。そのため、ある意味気運が全体で高まっていると言えます。
2つ目は、企業側でデータ利活用を進めていく立場としては、その気運の高まりをうまく使っていくべきだということ。
ポイントとしては、従来の技術もあわせて使いつつ、「これまで技術的にはできたが、受け入れられずにできなかったこと」を実現できるようになってきていると思っています。
3つ目はガイドラインやガバナンス、セキュリティの重要性。今回の技術革新の波を正しく受け入れ、変化していくことが求められます。
これで本セッションは終了となります。下田さん、辻さん本日はありがとうございました。
あなたにオススメの記事

2023.12.01
生成AI(ジェネレーティブAI)とは?ChatGPTとの違いや仕組み・種類・活用事例

2023.09.21
DX(デジタルトランスフォーメーション)とは?今さら聞けない意味・定義を分かりやすく解説【2024年最新】

2023.11.24
【現役社員が解説】データサイエンティストとは?仕事内容やAI・DX時代に必要なスキル

2023.09.08
DX事例26選:6つの業界別に紹介~有名企業はどんなDXをやっている?~【2024年最新版】

2023.08.23
LLM(大規模言語モデル)とは?生成AIとの違いや活用事例・課題

2024.03.22
生成AIの評価指標・ベンチマークとそれらに関連する問題点や限界を解説













